
- Updated: February 5, 2026
- 6 min read
Building Production‑Grade Data Validation Pipelines with Pandera: A Comprehensive Guide
Pandera enables data engineers to build production‑grade validation pipelines by defining typed schemas and composable DataFrame contracts that enforce data quality at every stage of a workflow.
Why Data Validation Matters in Modern Pipelines
In today’s data‑driven enterprises, a single malformed record can cascade into costly downstream failures, inaccurate analytics, and lost revenue. The original MarkTechPost tutorial demonstrates how Pandera, a Python library built on top of pandas, can turn ad‑hoc checks into a robust, contract‑driven validation layer. By treating schemas as first‑class citizens, teams can guarantee that every transformation receives clean, trustworthy data.
UBOS, a low‑code AI platform, embraces the same philosophy. Whether you are a startup or an enterprise, the UBOS homepage showcases tools that let you embed validation logic directly into your data‑centric applications without writing boilerplate code.
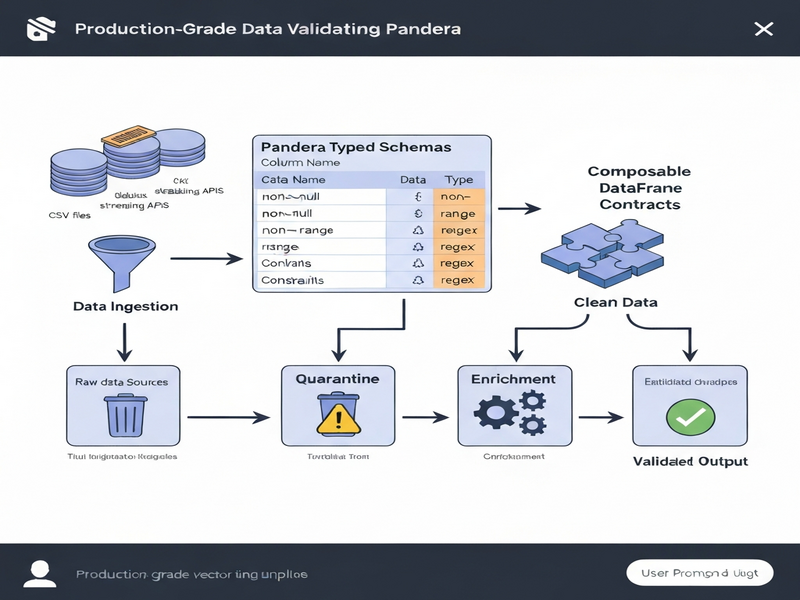
Typed Schemas and Composable Contracts in Pandera
Pandera introduces DataFrameModel classes that act like typed schemas. Each column is declared with a Series type and optional constraints (e.g., ge=0, isin=[...]). These constraints are enforced automatically during validation, turning runtime errors into deterministic schema violations.
The power of Pandera lies in its composability. You can layer column‑level checks, row‑level regex validation, and whole‑DataFrame invariants using @pa.check and @pa.dataframe_check decorators. This approach mirrors contract‑oriented programming: a function declares the exact shape of data it expects, and Pandera guarantees that contract before the function executes.
class Orders(pa.DataFrameModel):
order_id: Series[int] = pa.Field(ge=1)
email: Series[object] = pa.Field(nullable=True)
country: Series[str] = pa.Field(isin=["CA","US","MX"])
# … more fields …
@pa.check("email")
def email_valid(cls, s: pd.Series) -> pd.Series:
return s.isna() | s.str.match(EMAIL_RE)
By defining a base schema (e.g., Orders) and extending it with derived schemas (e.g., EnrichedOrders), you can safely add computed columns while preserving invariants—exactly the pattern shown in the MarkTechPost guide.
Step‑by‑Step: Building a Production‑Grade Validation Pipeline
1️⃣ Generate Realistic, Imperfect Data
The tutorial starts by synthesizing a transactional dataset that deliberately contains common quality issues: missing emails, negative prices, unknown country codes, and out‑of‑range discounts. This “dirty” data serves as a sandbox for testing schema enforcement.
In a UBOS workflow, you could replicate this step using the Workflow automation studio to orchestrate data generators, making the process repeatable across environments.
2️⃣ Declare Typed Schemas & Business Rules
Using DataFrameModel, you encode column constraints (e.g., unit_price > 0) and cross‑column logic (e.g., “partner” channel cannot be paired with “MX” country). The Config block toggles coercion, strictness, and ordering, giving you fine‑grained control over validation behavior.
For teams that need a visual schema editor, UBOS offers a Web app editor on UBOS where you can drag‑and‑drop field definitions and instantly generate the underlying Pandera code.
3️⃣ Choose Between Lazy and Strict Validation
Lazy validation (lazy=True) collects all violations in a single pass, returning a SchemaErrors object that lists every offending row and column. This is ideal for exploratory data checks where you want a full error report.
Strict validation (lazy=False) aborts on the first failure, which is faster for production pipelines that must halt on any breach. The tutorial demonstrates both modes, showing how to switch based on the pipeline stage.
UBOS’s AI marketing agents often run in strict mode when feeding clean leads into campaign engines, ensuring no bad data reaches downstream ad spend calculations.
4️⃣ Quarantine Bad Records Without Breaking the Flow
Instead of discarding the entire batch, the tutorial shows a pattern that isolates offending rows into a “quarantine” DataFrame while allowing the clean subset to continue. This approach preserves data lineage and enables targeted remediation.
In UBOS, you can route quarantined rows to a separate storage bucket or a Slack channel using built‑in Telegram integration on UBOS, keeping data engineers in the loop without manual intervention.
5️⃣ Enrich and Extend Validated Data
After cleaning, the tutorial adds a total_value column and validates it with a new schema that checks numerical consistency. This demonstrates how Pandera can guard feature‑engineering steps, preventing silent drift.
UBOS users can automate such enrichment with the UBOS templates for quick start, selecting a “Data Enrichment” template that injects the necessary Python snippets into a managed notebook.
Best Practices & Performance Tips for Production Pipelines
- Version Pinning: Record exact versions of
pandas,pandera, and any optional back‑ends (e.g.,polars) to guarantee reproducibility across environments. - Schema Modularity: Keep base schemas small and compose them with inheritance. This reduces duplication and makes updates painless.
- Lazy Validation in Development: Use lazy mode while iterating on new checks; switch to strict mode in CI/CD pipelines.
- Parallel Validation: For massive datasets, split the DataFrame into chunks and validate in parallel using
daskorray. Pandera’s API is pure‑Python, so it works seamlessly with these executors. - Cache Coercion Results: Enable
coerce=Trueonly when necessary; unnecessary type casting can add overhead. - Log Structured Failures: Persist
SchemaErrors.failure_casesas JSON lines. This makes downstream monitoring (e.g., with ELK) straightforward. - Integrate with CI: Add a validation step to your GitHub Actions or GitLab CI pipelines. Fail the build if any strict validation error surfaces.
The Enterprise AI platform by UBOS includes built‑in observability dashboards that can ingest these JSON logs, giving you real‑time visibility into data health across all services.
Conclusion: Turn Data Quality Into a Competitive Advantage
By treating schemas as immutable contracts, Pandera transforms data validation from a reactive afterthought into a proactive design principle. The MarkTechPost tutorial proves that a few dozen lines of declarative code can safeguard an entire analytics stack.
If you’re looking for a platform that blends low‑code flexibility with enterprise‑grade reliability, explore the UBOS platform overview. From the UBOS solutions for SMBs to the UBOS for startups, you’ll find pre‑built connectors for data ingestion, validation, and enrichment.
Ready to accelerate your data pipelines? Check out the UBOS pricing plans and start a free trial today. Need help customizing a validation workflow? Our UBOS partner program connects you with certified experts who can tailor Pandera‑style contracts to your specific domain.
Stay ahead of data quality challenges—integrate typed schemas, adopt lazy validation for rapid debugging, and quarantine bad rows before they propagate. The future of trustworthy AI‑driven analytics starts with clean data, and Pandera gives you the tools to get there.
Explore More AI‑Powered Tools on UBOS
Want to experiment with generative AI alongside data validation? Try the Talk with Claude AI app for conversational insights, or the AI SEO Analyzer to keep your own content discoverable.
Content creators can boost productivity with the AI Article Copywriter, while video teams may love the AI Video Generator for rapid prototyping.
All of these templates integrate seamlessly with the OpenAI ChatGPT integration and the Chroma DB integration, giving you vector‑search capabilities for advanced data retrieval.
For voice‑first experiences, explore the ElevenLabs AI voice integration—perfect for turning validation reports into audible alerts.