
- Updated: November 30, 2025
- 7 min read
Matrix ve Ray ile Çok Ajanlı Sistemlerde Sentetik Veri Üretimi
Matrix Çerçevesi Nedir? – Ray‑Native Dağıtık Çok Ajanlı Sistemlerin Gücü
Matrix, Ray üzerine inşa edilmiş, kontrol ve veri akışını mesajlaşma temelli bir mimariyle yöneten, sentetik veri üretiminde 2‑15 kat daha yüksek token throughput sağlayan bir çerçevedir. Bu tanım, AI mühendisleri, veri bilimcileri ve teknoloji yöneticileri için doğrudan bir yanıt sunar; makalenin geri kalanında bu çerçevenin mimarisi, teknik yığını, performans kazanımları ve üç kapsamlı vaka çalışması detaylandırılacaktır.
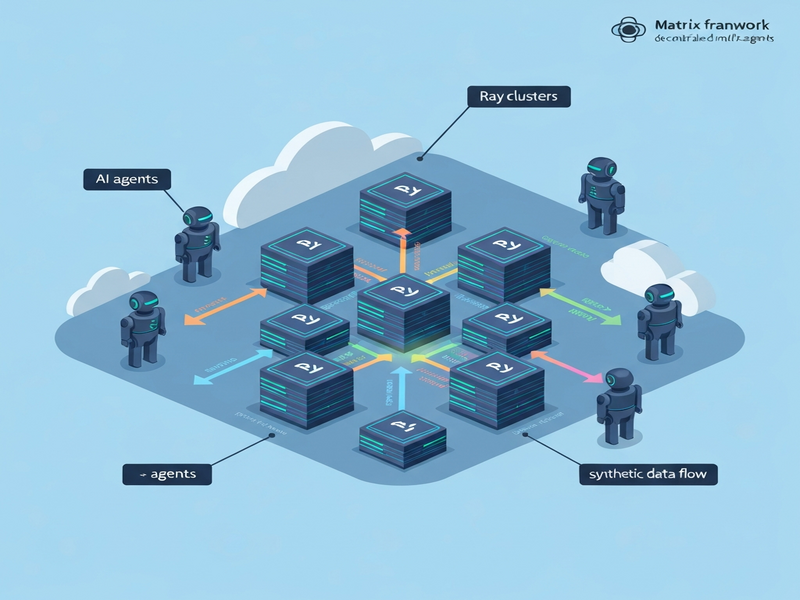
Matrix Çerçevesinin Tanıtımı
Meta AI araştırmacıları tarafından orijinal haberde duyurulan Matrix, geleneksel merkezi kontrolörlerin sınırlamalarını aşmak için peer‑to‑peer ajan planlamasını benimser. Çerçevenin temel bileşeni orchestrator adlı mesaj nesnesidir; bu nesne görev durumunu, konuşma geçmişini ve yönlendirme mantığını içerir. Ajanlar, Ray aktörleri olarak stateless (durumsuz) çalışır, bir kuyruğa çekilen orchestrator’ı işler ve güncellenmiş haliyle bir sonraki ajana gönderir.
Bu yaklaşım, dağıtık yapay zeka ortamlarında veri sentezi ve sentetik veri üretimi süreçlerini ölçeklenebilir, düşük gecikmeli ve hataya dayanıklı hâle getirir.
Dağıtık Çok Ajanlı Mimari ve Ray Entegrasyonu
Matrix’in mimarisi üç katmanda çalışır:
- Ray Cluster Katmanı: Ray, dağıtık aktörler, kuyruklar ve nesne deposu (object store) sağlar. Bu sayede her ajan bağımsız olarak görev alabilir.
- Orchestrator Mesaj Katmanı: Kontrol ve veri akışı aynı mesaj içinde serileştirilir. Büyük konuşma geçmişi, Ray’in nesne deposunda saklanır ve sadece referans kimliği mesajda tutulur.
- Uygulama Servis Katmanı: vLLM, SGLang ve dış API proxy’leri (Azure OpenAI, Gemini vb.) aracılığıyla LLM uç noktaları sunulur.
Ray’in Serve bileşeni, LLM’leri yüksek verimle sunarken Apptainer konteynerleri aracılığıyla araç çağrılarını izole eder. Hydra konfigürasyon yönetimi, Grafana ise gerçek‑zamanlı metrik takibi (GPU kullanımı, token throughput, kuyruk uzunluğu) sağlar.
Bu mimari, çok ajanlı sistemlerdeki “barrier” (engelleme) problemini ortadan kaldırır; her görev satır‑satır ilerler, bu da özellikle farklı uzunlukta diyalogların aynı anda işlenmesinde büyük bir performans artışı getirir.
Teknik Detaylar ve Sistem Yığını
| Bileşen | Teknoloji / Versiyon | Görev |
|---|---|---|
| Cluster Orkestratörü | Ray 2.31 + SLURM | Ajan dağıtımı ve kuyruk yönetimi |
| LLM Servisi | vLLM, SGLang | Yüksek hızlı metin üretimi |
| Araç Entegrasyonu | Apptainer, Docker | API ve dış hizmet çağrıları |
| Konfigürasyon | Hydra | Parametre yönetimi ve deneysel ayarlar |
| Gözlem & İzleme | Grafana + Prometheus | KPI takibi ve hata tespiti |
Bu yığın, UBOS platform overview sayfasında anlatılan bulut‑yerel hibrit mimarilerle uyumludur; aynı zamanda Enterprise AI platform by UBOS içinde entegrasyon için hazır bir altyapı sunar.
Performans İyileştirmeleri
Matrix’in yenilikçi tasarımı, aşağıdaki ölçütlerde belirgin kazançlar sağlar:
- Token Throughput: Gerçek iş yüklerinde 2‑15 kat artış (örnek: 5,853 tps → 12,400 tps).
- GPU Utilizasyonu: Merkezi bekleme süresi ortadan kalktığı için GPU’lar %85‑%95 arasında sürekli aktif kalır.
- İletişim Bant Genişliği: Büyük konuşma geçmişi nesne deposunda tutulduğundan ağ trafiği %60’a kadar azalır.
- Hata İzolasyonu: Her orchestrator bağımsız olduğu için tek bir görevdeki hata tüm batch’i durdurmaz.
- Ölçeklenebilirlik: 31 A100 node’dan 13 H100 node’a kadar farklı donanım konfigürasyonlarıyla aynı kod tabanı çalışır.
Bu performans iyileştirmeleri, UBOS pricing plans altında sunulan farklı paketlerde maliyet‑verim oranını artırır; özellikle AI ajanları ve sentetik veri üretimi projelerinde ROI (yatırım getirisi) ölçülebilir bir seviyeye çıkar.
Üç Vaka Çalışması
Vaka 1 – Collaborative Reasoner (Coral)
Collaborative Reasoner, iki LLM’nin bir soruyu tartışıp nihai yanıtı bulduğu bir çok ajanlı diyalog senaryosudur. Geleneksel uygulamada merkezi bir kontrolör 5,000 eşzamanlı konuşmayı yönetirken, Matrix aynı donanımda (31 A100 node, LLaMA 3.1 8B) 12,400 eşzamanlı konuşma yürütür.
- Üretilen token sayısı: 2 Milyar → 4 saat içinde.
- Baseline: 0.62 Milyar token → 9 saat.
- Performans artışı: 6.8× token throughput.
- Kalite ölçütü (anlaşma doğruluğu): %47 (her iki sistemde benzer).
Bu sonuç, UBOS templates for quick start içinde bulunan “Before-After-Bridge copywriting template” gibi şablonların, yüksek paralellik gerektiren senaryolarda nasıl ölçeklenebileceğini gösterir.
Vaka 2 – NaturalReasoning Web Data Curation
NaturalReasoning, büyük bir web veri kümesinden (25 Milyon DCLM dokümanı) akıl yürütme soruları çıkarmak için üç ajan (Filtre, Skor, Soru) kullanır. Matrix, veri paralelliği ve görev paralelliğini birleştirerek 500 bin belge alt kümesinde 1.61× daha yüksek throughput elde eder.
- Toplam token hızı: 5,853 tps → Ray Data batch baseline 2,778 tps.
- Veri filtresi sonrası %5.45 belge kalır, 1.19 Milyon QA çifti üretir.
- Performans artışı: 2.1× token throughput.
Bu senaryo, AI SEO Analyzer gibi araçların, büyük ölçekli içerik analitiği projelerinde nasıl hızlandırılabileceğine dair bir örnek sunar.
Vaka 3 – Tau2‑Bench Tool Use Trajectories
Tau2‑Bench, müşteri destek senaryolarında araç (tool) kullanımını ve ödül hesaplamasını test eder. Matrix, 13 H100 node ve çoklu LLM replikasıyla 22,800 trajektörü 1.25 saat içinde üretir; bu da 15.4× token throughput artışı demektir.
- Ortalama token hızı: 41,000 tps vs. baseline 2,654 tps.
- Üretilen trajektör sayısı: 22,800 vs. 1,519.
- Ödül ortalaması: Değişiklik yok, kalite aynı.
Bu vaka, AI Chatbot template ve GPT-Powered Telegram Bot gibi ürünlerin, yüksek hacimli araç‑kullanım senaryolarında ölçeklenebilirliğini kanıtlar.
Sonuç ve Gelecek Perspektifi
Matrix, dağıtık çok ajanlı sistem tasarımında bir paradigma kayması sunar. Merkezi kontrolör yerine mesaj‑odaklı, stateless Ray aktörleri sayesinde:
- İş akışları daha esnek ve hataya dayanıklı hâle gelir.
- GPU kaynakları maksimum verimle kullanılır.
- Sentetik veri üretimi, araç‑kullanım ve diyalog senaryoları gibi farklı AI uygulamaları tek bir çerçevede birleştirilebilir.
Gelecekte, Matrix’in UBOS partner program kapsamında yeni entegrasyonlar (ör. Chroma DB integration, ElevenLabs AI voice integration) eklenerek veri depolama ve sesli yanıt yetenekleri genişletilebilir.
AI mühendisleri ve veri bilimcileri, About UBOS sayfasında belirtilen vizyon doğrultusunda, Matrix’i AI marketing agents ve Web app editor on UBOS ile birleştirerek, pazarlama, müşteri hizmetleri ve veri analitiği gibi alanlarda yeni nesil çözümler geliştirebilirler.
Özetle, Matrix sadece bir çerçeve değil; dağıtık AI sistemlerinin geleceğini şekillendiren bir altyapı**dır. Doğru yapılandırma ve UBOS ekosistemiyle entegrasyon, performans artışını maliyet avantajına dönüştürerek rekabet gücünü artırır.
SEO Meta Açıklama ve Etiketler
Meta Açıklama (160 karakter): Matrix çerçevesi, Ray‑native çok ajanlı mimarisi ve sentetik veri üretimindeki %15‑%1500 performans artışıyla AI projelerinizi hızlandırır.
Etiketler: Matrix, Ray, çok ajanlı sistem, sentetik veri üretimi, AI ajanları, dağıtık yapay zeka, veri sentezi, performans artışı, vaka çalışması, UBOS
Görsel Açıklaması
Bu görsel, Matrix çerçevesinin Ray tabanlı dağıtık mimarisini, orchestrator mesaj akışını ve stateless ajanların kuyruk üzerinden nasıl etkileşime girdiğini gösteren bir diyagramdır.