
- Updated: April 3, 2026
- 6 min read
Falcon Perception Unveiled: 600M Early‑Fusion Transformer for Open‑Vocabulary Grounding and Segmentation

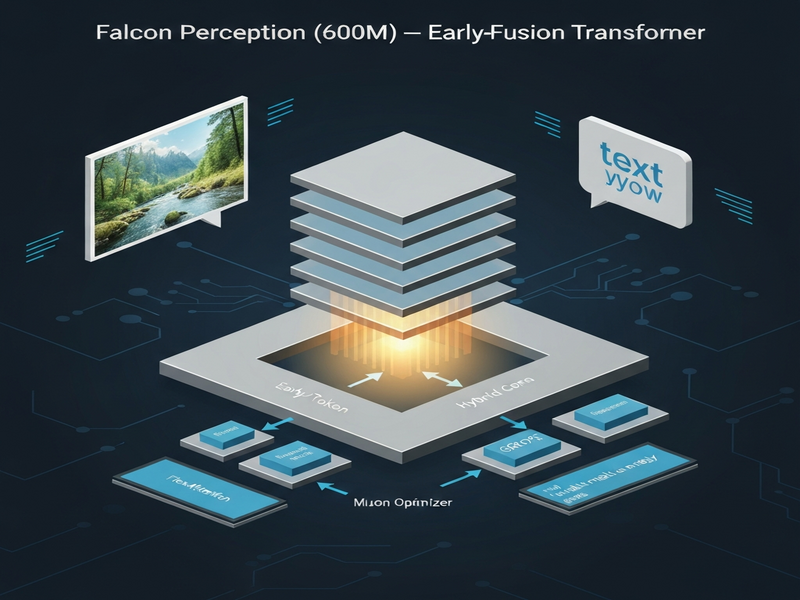
Falcon Perception is a 0.6 billion‑parameter early‑fusion transformer that processes image patches and text tokens together from the first layer, achieving state‑of‑the‑art open‑vocabulary grounding and segmentation.
Why Falcon Perception matters for computer‑vision AI
The computer‑vision community has long relied on a modular “Lego‑brick” pipeline: a vision encoder extracts features, and a separate decoder handles tasks such as segmentation or captioning. This separation creates latency, scaling bottlenecks, and limits the depth of language‑vision interaction. MarkTechPost’s coverage highlights how the Technology Innovation Institute (TII) flips this paradigm with Falcon Perception, a unified dense Transformer that learns both visual and linguistic representations in a single pass.
For tech‑savvy professionals and AI enthusiasts, the model promises faster inference, lower memory footprints, and a new level of semantic understanding—especially when dealing with open‑vocabulary queries that were previously out of reach for compact models.
Model overview: Early‑fusion unified Transformer
Falcon Perception packs 600 million parameters into a single dense stack. Unlike traditional vision‑language models that keep vision and language streams separate, this architecture fuses them at the token level right from the input layer. The model ingests a flattened sequence of image patches followed by text tokens, enabling bidirectional visual attention and causal language attention within the same self‑attention matrix.
- 600 M parameters – a sweet spot between efficiency and expressive power.
- Early‑fusion design – image and text share the same embedding space from layer 1.
- Unified decoder – the same stack generates segmentation masks, coordinates, and textual responses.
Such a design aligns perfectly with the UBOS platform overview, where developers can spin up multimodal AI services without juggling separate encoders and decoders.
Key innovations that power Falcon Perception
Hybrid Attention & GGROPE
Standard Transformers use a single masking strategy. Falcon Perception introduces a hybrid mask: visual tokens attend bidirectionally (full context), while language and task tokens use causal masking. This hybrid approach preserves the autoregressive nature needed for generation while still building a global visual context.
To keep 2‑D spatial relationships after flattening, the model employs Golden Gate Rotary Positional Embeddings (GGROPE). GGROPE decomposes each head’s positional encoding into a sequential component and a spatial component, allowing attention to respect arbitrary rotations and aspect‑ratio changes.
Muon optimizer & FlexAttention
Training a heterogeneous token stream is unstable with vanilla AdamW. The research team designed the Muon optimizer for specialized heads (coordinates, size, segmentation), achieving faster convergence and lower loss.
For efficient GPU utilization, FlexAttention restricts self‑attention to the valid patch region of each image, avoiding wasted compute on padding. Combined with a scatter‑and‑pack strategy, the model processes native‑resolution images without sacrificing throughput.
Raster ordering
When multiple objects appear, Falcon Perception predicts them in raster order (top‑to‑bottom, left‑to‑right). This deterministic ordering accelerates training and reduces coordinate error compared to random or size‑based ordering.
These engineering tricks echo the flexibility of the Workflow automation studio, where custom attention patterns can be orchestrated without writing low‑level code.
Training recipe: Multi‑teacher distillation & 685 GT compute
Falcon Perception’s training pipeline is a three‑stage process that totals roughly 685 gigatokens (GT):
- Multi‑teacher distillation: The model is initialized by distilling knowledge from DINOv3 (ViT‑H) for visual features and SigLIP2 (So400M) for language alignment.
- In‑Context Listing (450 GT): The model learns to “list” every object in a scene, building a dense global context.
- Task Alignment (225 GT): Using query masking, the model is forced to ground each textual query solely on the image, sharpening open‑vocabulary grounding.
- Long‑Context Fine‑tuning (10 GT): The final stage expands the mask limit to 600 per expression, enabling dense scene parsing.
The serialization format follows a <image> expr1 <present> <coord> <size> <seg> <eos> pattern, ensuring the model resolves spatial attributes before generating pixel‑level masks.
Such a disciplined recipe is reminiscent of the UBOS templates for quick start, where step‑by‑step pipelines reduce trial‑and‑error for developers.
Benchmark results: PBench vs. SAM 3
To surface nuanced capabilities, TII introduced PBench, a benchmark that categorizes samples into five semantic levels. Falcon Perception’s performance (Macro‑F1) outperforms the widely‑used Segment Anything Model 3 (SAM 3) on most complex tasks.
| Benchmark Split | SAM 3 | Falcon Perception (600M) |
|---|---|---|
| L0: Simple Objects | 64.3 | 65.1 |
| L1: Attributes | 54.4 | 63.6 |
| L2: OCR‑Guided | 24.6 | 38.0 |
| L3: Spatial Understanding | 31.6 | 53.5 |
| L4: Relations | 33.3 | 49.1 |
| Dense Split | 58.4 | 72.6 |
The biggest gains appear in spatial understanding (+21.9 points) and OCR‑guided queries (+13.4 points), confirming that early‑fusion and GGROPE give the model a superior grasp of geometry and text embedded in images.
Related model: FalconOCR
Building on the same early‑fusion philosophy, TII released FalconOCR, a 300 M‑parameter specialist for document processing. Despite its smaller size, FalconOCR reaches 80.3 % accuracy on the olmOCR benchmark, rivaling proprietary systems such as Gemini 3 Pro (80.2 %). It also scores 88.64 on OmniDocBench, surpassing many larger multimodal pipelines.
FalconOCR demonstrates that the unified architecture scales down gracefully, making it an attractive option for enterprises that need high‑throughput OCR without the overhead of separate vision‑language stacks.
How UBOS can accelerate your Falcon‑based projects
UBOS offers a suite of tools that align perfectly with the Falcon Perception workflow:
- UBOS homepage – launch a free sandbox to experiment with multimodal models.
- AI marketing agents – embed Falcon Perception into automated content creation pipelines.
- UBOS pricing plans – choose a tier that matches your compute budget.
- UBOS for startups – fast‑track MVPs with pre‑built integration blocks.
- UBOS solutions for SMBs – scale vision‑language services without hiring a full ML team.
- Enterprise AI platform by UBOS – manage governance, security, and multi‑tenant deployments.
- Web app editor on UBOS – drag‑and‑drop UI components that consume Falcon Perception outputs.
- About UBOS – learn about the team behind the platform.
- UBOS partner program – become a certified integrator for Falcon‑based solutions.
- UBOS portfolio examples – see real‑world deployments of vision‑language AI.
- ChatGPT and Telegram integration – combine Falcon Perception with conversational bots for on‑the‑fly image analysis.
- OpenAI ChatGPT integration – enrich ChatGPT responses with visual grounding from Falcon.
- ElevenLabs AI voice integration – turn segmentation results into spoken explanations.
- AI SEO Analyzer – leverage Falcon Perception to extract visual SEO signals from screenshots.
- AI Article Copywriter – generate copy that references detected objects in images.
- Talk with Claude AI app – pair Falcon Perception with Claude for multimodal chat experiences.
- AI Video Generator – feed segmentation masks into video synthesis pipelines.
By leveraging these resources, developers can focus on product logic while UBOS handles deployment, scaling, and monitoring.
Conclusion: A new era for open‑vocabulary vision‑language models
Falcon Perception proves that a compact, early‑fusion transformer can rival—and in many cases surpass—larger modular systems. Its hybrid attention, GGROPE positional encoding, and raster ordering deliver tangible gains on challenging semantic benchmarks, while the efficient training recipe keeps compute costs manageable.
For organizations looking to embed cutting‑edge visual grounding into products, the model’s 600 M‑parameter footprint makes it a practical choice. Combined with the Enterprise AI platform by UBOS, teams can spin up production‑grade services in days rather than months.
Ready to experiment? Visit the UBOS homepage, select a suitable pricing tier, and start building your own Falcon‑powered applications today.