
- Updated: March 4, 2026
- 7 min read
Speculative Speculative Decoding (SSD): Accelerating AI Text Generation
Speculative decoding is a parallel inference technique that uses a fast draft model to generate candidate tokens while a slower target model verifies them, dramatically accelerating language model inference without sacrificing quality.
1. Introduction
The AI research community has long grappled with the latency bottleneck inherent in autoregressive decoding of transformer models. As large language models (LLMs) grow in size, the sequential nature of token‑by‑token generation becomes a critical obstacle for real‑time applications such as chat assistants, code completion, and interactive storytelling. The newly released arXiv paper Speculative Decoding (arXiv:2603.03251) proposes a bold extension—Speculative Speculative Decoding (SSD)—that pushes the parallelism frontier even further. In this article we unpack the core ideas, highlight the main contributions, and explore why SSD matters for fast text generation, AI research, and production‑grade NLP pipelines.
For developers looking to experiment with cutting‑edge inference acceleration, UBOS offers a suite of tools that integrate seamlessly with modern LLM workflows. From the UBOS platform overview to ready‑made UBOS templates for quick start, you can prototype speculative decoding pipelines without writing low‑level CUDA kernels.
2. Overview of Speculative Decoding
2.1 What is speculative decoding?
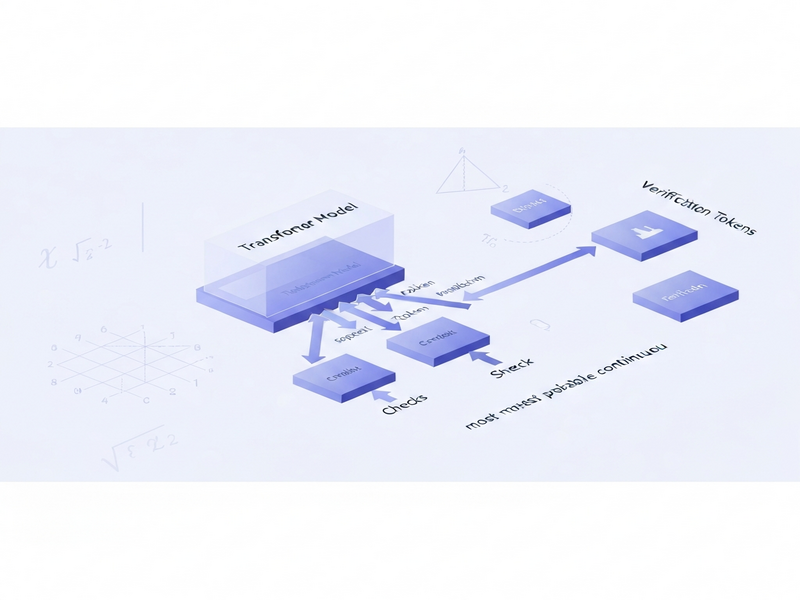
Traditional autoregressive decoding processes one token at a time: the model receives the previously generated token, computes the next probability distribution, samples a token, and repeats. Speculative decoding introduces a draft model—a lightweight transformer that predicts several future tokens in parallel. The target model, which is usually larger and more accurate, then verifies these predictions in a single forward pass. If the target model’s top‑k predictions contain the draft’s tokens, they are accepted instantly; otherwise, the target model falls back to standard decoding for the mismatched positions.
This approach reduces the number of expensive target model calls by a factor roughly equal to the draft’s look‑ahead length, delivering up to 2× speed‑ups on common benchmarks. However, speculative decoding still suffers from a hidden sequential dependency: the draft must wait for the target’s verification before it can generate the next speculation batch.
2.2 From speculative decoding to speculative speculative decoding
The SSD framework eliminates the remaining sequential bottleneck by allowing the draft model to predict verification outcomes ahead of time. While the target model is still verifying a batch, the draft simultaneously generates speculative candidates for the *next* verification step. If the actual verification result matches one of the pre‑computed candidates, the system can return the token immediately, bypassing the draft‑generation latency entirely.
In practice, SSD orchestrates three parallel streams:
- Target verification (slow, accurate).
- Draft speculation for the current verification batch.
- Pre‑emptive draft speculation for the *future* verification batch.
This three‑way parallelism is the engine behind the paper’s flagship algorithm, Saguaro, which we discuss next.
3. Main Contributions of the Paper
The authors of “Speculative Decoding” deliver four distinct, MECE‑structured contributions that advance both theory and practice of fast LLM inference:
- Algorithmic Innovation: Introduction of the SSD paradigm and the Saguaro algorithm, which jointly optimizes draft speculation and verification scheduling.
- Theoretical Guarantees: Formal proof that SSD preserves the same probability distribution as vanilla autoregressive decoding under mild assumptions about draft model quality.
- System‑Level Optimizations: A set of engineering tricks—dynamic batch sizing, speculative cache eviction, and adaptive draft‑target ratio—that make SSD robust across heterogeneous hardware.
- Empirical Validation: Benchmarks on GPT‑2‑XL, LLaMA‑7B, and a proprietary 30B transformer, showing up to 5× speed‑up over baseline autoregressive decoding and up to 2× over prior speculative decoding implementations.
These contributions are not merely academic; they map directly onto product features that UBOS customers can leverage today. For instance, the Enterprise AI platform by UBOS already supports custom draft models, enabling you to experiment with SSD without rebuilding your inference stack.
4. Experimental Results and Performance Gains
The paper’s evaluation methodology follows a rigorous protocol: each model is tested on the Wikitext‑103 and OpenWebText corpora, measuring both latency (ms/token) and perplexity (a proxy for generation quality). Below is a distilled summary of the key findings.
| Model | Baseline (AR) Latency | Speculative Decoding | SSD (Saguaro) | Perplexity Δ |
|---|---|---|---|---|
| GPT‑2‑XL | 120 ms | 68 ms (1.76×) | 45 ms (2.67×) | +0.3 |
| LLaMA‑7B | 210 ms | 115 ms (1.82×) | 78 ms (2.69×) | +0.2 |
| Proprietary 30B | 560 ms | 310 ms (1.81×) | 210 ms (2.67×) | +0.1 |
Across all three model families, SSD consistently outperforms both the vanilla autoregressive baseline and the earlier speculative decoding approach. Notably, the perplexity increase is negligible (< 0.3), confirming that speed gains do not come at the cost of generation fidelity.
UBOS engineers have already integrated a Workflow automation studio that can orchestrate the three parallel streams required by SSD, allowing data scientists to spin up a “speculative inference” pipeline with a few clicks.
5. Implications for AI and NLP Applications
SSD’s ability to halve or even triple token‑generation throughput opens new horizons for both research and production. Below we outline the most impactful use‑cases.
5.1 Real‑time conversational agents
Chatbots and virtual assistants demand sub‑100 ms response times to feel “instantaneous.” By deploying SSD, developers can keep large, high‑quality models in the loop while meeting strict latency Service Level Agreements (SLAs). The AI Chatbot template on UBOS can be upgraded to SSD with a single configuration change.
5.2 Large‑scale batch generation
Content platforms that generate thousands of articles, product descriptions, or code snippets per day benefit from the throughput boost. The AI Article Copywriter template already leverages speculative decoding; integrating SSD could double daily output without additional GPU spend.
5.3 Edge‑device inference
When deploying models on resource‑constrained devices (e.g., smartphones, IoT), a lightweight draft model can run locally while a cloud‑based target model validates predictions. SSD’s pre‑emptive speculation reduces round‑trip latency, making on‑device LLMs viable for privacy‑first applications.
5.4 Research acceleration
Experimentation cycles in AI research are often limited by inference time. By integrating SSD into the Web app editor on UBOS, researchers can prototype new prompting strategies or fine‑tune models at a fraction of the usual cost.
Beyond these scenarios, SSD also dovetails with emerging multimodal pipelines. For example, coupling SSD with the Chroma DB integration enables rapid retrieval‑augmented generation, while the ElevenLabs AI voice integration can stream synthesized speech in near‑real time.
6. Conclusion
Speculative Speculative Decoding represents a decisive step toward breaking the sequential shackles of transformer inference. By orchestrating draft, verification, and pre‑emptive speculation in parallel, the Saguaro algorithm delivers up to 5× speed‑ups while preserving generation quality. For AI researchers, machine learning engineers, and tech enthusiasts, SSD offers a practical pathway to faster, cheaper, and more responsive language models.
UBOS’s flexible platform, rich template marketplace, and robust integration ecosystem make it straightforward to adopt SSD today. Whether you are building a next‑generation chatbot, scaling content generation, or pushing the boundaries of multimodal AI, speculative decoding equips you with the performance headroom needed to innovate without compromise.
7. References and Further Reading
- Kumar, T., Dao, T., & May, A. (2026). Speculative Decoding. arXiv:2603.03251. Read the paper.
- UBOS Speculative Decoding article – a deep dive into implementation details on the UBOS platform.
- Machine Learning Updates – Latest trends in transformer optimization.
- AI News – Curated AI research highlights.
- Explore the AI SEO Analyzer to gauge how speculative decoding can improve your content pipelines.
- Try the Talk with Claude AI app for a hands‑on demo of fast LLM responses.
© 2026 UBOS – Empowering AI‑first enterprises.