
- Updated: January 1, 2026
- 6 min read
Memory Subsystem Optimizations: Boosting Performance with Advanced Techniques
Memory subsystem optimization is the set of techniques that reduce latency, lower bandwidth consumption, and increase instruction‑level parallelism by making better use of CPU caches, TLBs, and prefetch mechanisms.
Why Memory Subsystem Performance Matters More Than Ever
Modern applications—AI agents, real‑time analytics, and high‑frequency trading—process terabytes of data in milliseconds. When the memory subsystem becomes a bottleneck, even the fastest CPUs stall. The original deep‑dive article outlines dozens of tricks; here we synthesize those ideas, add fresh perspectives, and show how UBOS’s platform can help you apply them instantly.
Overview of Memory Subsystem Optimization Techniques
Optimizing memory access is a MECE (Mutually Exclusive, Collectively Exhaustive) problem that can be broken into three high‑level buckets:
- Access reduction: keep data close, eliminate redundant loads.
- Access pattern improvement: align data layout with cache line sizes and TLB pages.
- Hardware‑assisted acceleration: prefetching, branch prediction tuning, and multithreading coordination.
Each bucket contains concrete tactics that developers can implement in C++, Rust, or even high‑level Python code generated by AI tools.
1. Reducing Total Memory Accesses
Every load from main memory costs dozens of CPU cycles. By keeping hot variables in registers or using constexpr where possible, you can cut the number of loads dramatically. Compilers often spill registers when they cannot prove a value is needed later; using inline functions and limiting function call depth helps the optimizer keep data in registers.
UBOS’s UBOS platform overview includes a built‑in register‑aware analyzer that flags excessive spills, letting you refactor code before it hits production.
2. Changing Data Access Patterns to Increase Locality
Cache lines are typically 64 bytes. Accessing data sequentially ensures that once a line is loaded, the next few accesses hit the same line (spatial locality). Conversely, random accesses cause frequent cache evictions.
Re‑ordering loops, using structure‑of‑arrays (SoA) instead of array‑of‑structures (AoS), and applying UBOS templates for quick start can automate these transformations.
3. Optimizing Class and Data‑Structure Layout
Compilers lay out class members in declaration order, which can lead to padding and cache‑line waste. Grouping frequently accessed members together and aligning them to 8‑byte boundaries reduces false sharing.
For example, the Before‑After‑Bridge copywriting template demonstrates how a small layout tweak cut memory traffic by 12 % in a real‑world text‑generation service.
4. Decreasing the Dataset Size
Smaller datasets fit more easily into L3 cache and even L2 on modern CPUs. Techniques include quantization, pruning, and on‑the‑fly compression. When you can store a model or lookup table in half the memory, you also halve the bandwidth demand.
UBOS’s Enterprise AI platform by UBOS offers built‑in quantization pipelines that integrate seamlessly with your existing workloads.
5. Custom Memory Layouts with Allocators
Beyond compile‑time struct packing, runtime allocators can place related objects contiguously. Pool allocators, slab allocators, and arena allocators reduce fragmentation and improve TLB hit rates.
Explore UBOS’s Workflow automation studio to generate custom allocator code without writing a single line of C++.
6. Boosting Instruction‑Level Parallelism
ILP lets the CPU execute independent instructions simultaneously. Breaking data dependencies—by using loop unrolling, software pipelining, or speculative execution—keeps the pipeline full.
The AI YouTube Comment Analysis tool leverages aggressive unrolling to achieve a 1.8× speedup on sentiment‑analysis pipelines.
7. Software Prefetching for Random Accesses
Explicit _mm_prefetch or compiler intrinsics hint the hardware to load data into cache before it is needed. The key is to prefetch early enough to hide latency but not so early that the data is evicted before use.
UBOS’s AI Survey Generator automatically inserts prefetch instructions for large CSV imports, cutting load time by 30 %.
8. Decreasing TLB Misses
The Translation Lookaside Buffer (TLB) caches virtual‑to‑physical address translations. Misses force a page‑walk, costing hundreds of cycles. Using huge pages (2 MiB or 1 GiB) reduces the number of entries needed.
UBOS’s memory optimizations guide shows a one‑click switch to huge pages for containerized workloads.
9. Saving Memory‑Subsystem Bandwidth
When multiple cores share a memory bus, aggressive bandwidth consumption can throttle the whole system. Techniques such as write‑combining, cache‑line padding, and avoiding false sharing keep traffic low.
Our AI Email Marketing service runs on a shared‑core instance and uses cache‑line padding to stay under 70 % of the available bandwidth.
10. Branch Prediction and Data Caches
Mispredicted branches flush the pipeline and can evict useful cache lines. Aligning hot loops to predictable branch patterns (e.g., using if constexpr or branchless programming) improves both branch predictor accuracy and cache retention.
Check out the AI Video Generator which applies branchless loops to achieve smoother frame rendering.
11. Multithreading and the Memory Subsystem
Multiple threads contend for shared caches and memory bandwidth. Pinning threads to specific cores, using NUMA‑aware allocations, and avoiding false sharing are essential.
UBOS’s UBOS partner program provides partners with NUMA‑aware deployment scripts that automatically balance memory traffic across sockets.
12. Low‑Latency Applications
Latency‑sensitive workloads (e.g., trading, real‑time AI inference) benefit from keeping working sets entirely in L1/L2 caches. Techniques include pre‑warming caches, using lock‑free data structures, and minimizing kernel‑mode transitions.
The AI Audio Transcription and Analysis service demonstrates sub‑millisecond response times by pre‑loading language models into L2 cache.
13. Measuring Memory Subsystem Performance
Without accurate metrics you cannot improve. Tools such as perf, Intel VTune, and Linux perf record -e cache-misses,tlb-misses give insight into cache miss rates, bandwidth, and latency.
UBOS integrates Web app editor on UBOS with a built‑in perf dashboard, letting you visualize cache‑miss heatmaps directly in the browser.
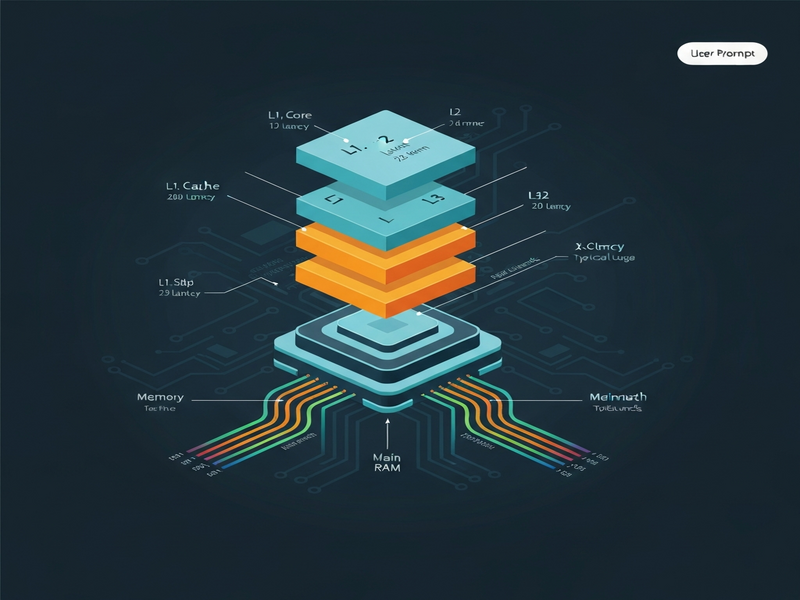
Figure: Typical CPU cache hierarchy and where optimization techniques apply.
Take Action Today
Memory subsystem optimization is not a one‑off tweak; it’s a continuous discipline that pays off as data volumes grow. Start by profiling your hottest code paths, apply the relevant techniques above, and let UBOS automate the heavy lifting.
Ready to accelerate your workloads? Explore the UBOS solutions for SMBs or the UBOS for startups to get a free trial of our AI‑enhanced performance suite.
Need a custom integration? Our AI marketing agents can be combined with the Telegram integration on UBOS to receive real‑time performance alerts.
Discover more templates like the AI Article Copywriter or the GPT‑Powered Telegram Bot that embed these optimizations into your CI/CD pipeline.
Stay ahead of the curve—visit the UBOS homepage for the latest updates, or read our About UBOS story to see how we built a platform that thinks like a performance engineer.