
- Updated: January 17, 2026
- 8 min read
Agentic Memory Breakthrough: AgeMem Framework Revolutionizes LLM Agents
Answer: AgeMem is a novel agentic memory framework that enables large language model (LLM) agents to manage both long‑term and short‑term memory as part of a single policy, using tool‑based actions and a three‑stage reinforcement‑learning (RL) training regimen.
Why Memory Management Matters for LLM Agents
Modern LLM agents excel at generating fluent text, but they still stumble when required to remember facts across long conversations or multiple sessions. Traditional pipelines treat long‑term storage (e.g., vector databases) and short‑term context (the current prompt window) as separate subsystems, linked together by hand‑crafted heuristics. This split creates brittle pipelines, inflated latency, and missed opportunities for the model to learn when to remember or forget.
The original research paper from Alibaba Group and Wuhan University proposes a solution: Agentic Memory (AgeMem). By exposing memory operations as first‑class tools inside the model’s action space, AgeMem lets the agent decide, in real time, whether to ADD, UPDATE, DELETE, RETRIEVE, SUMMARY, or FILTER information. The result is a single, end‑to‑end policy that learns memory management jointly with language generation.
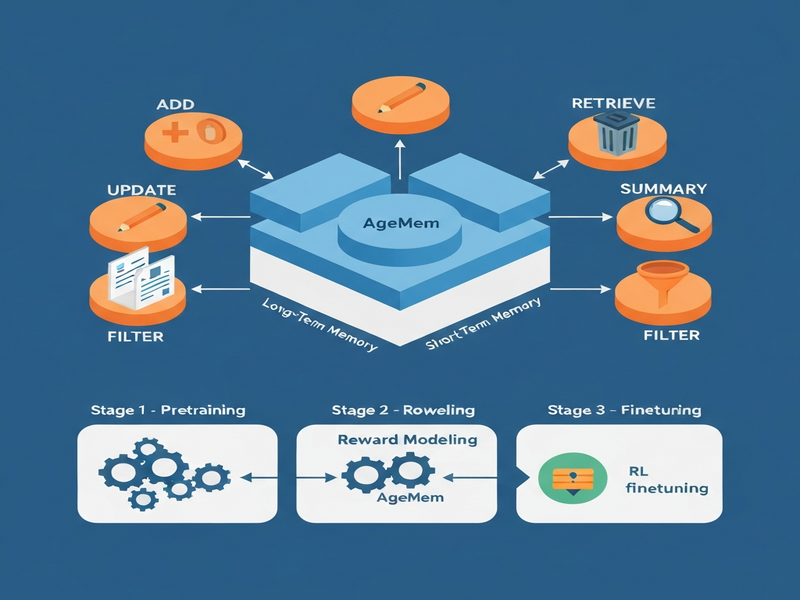
AgeMem Framework: Tool‑Based Memory Operations
AgeMem treats memory actions as tools that the LLM can invoke at any generation step. The framework defines six distinct tools, split between long‑term and short‑term memory:
- ADD: Store a new memory item with content and metadata.
- UPDATE: Modify an existing entry (e.g., add a timestamp or new attributes).
- DELETE: Remove obsolete or low‑value items.
- RETRIEVE: Perform a semantic search over the long‑term store and inject the results into the current context.
- SUMMARY: Compress a span of dialogue into a concise summary for short‑term use.
- FILTER: Drop irrelevant context fragments before the next reasoning step.
Each generation step follows a two‑phase protocol:
- A private
<think>block where the model reasons about the next action. - Either a
<tool_call>block (JSON‑encoded tool invocation) or an<answer>block that is sent to the user.
By making memory actions explicit, AgeMem eliminates hidden side‑effects and enables the RL algorithm to assign credit (or blame) to each tool use, directly shaping the agent’s memory strategy.
Three‑Stage Reinforcement Learning: From Construction to Integrated Reasoning
AgeMem’s training pipeline is deliberately split into three stages, each emphasizing a different memory challenge while keeping the long‑term store persistent across stages.
Stage 1 – Long‑Term Memory Construction
The agent engages in a casual dialogue, encountering facts that will later become crucial. It learns to invoke ADD, UPDATE, and DELETE to curate a high‑quality long‑term repository. Short‑term context naturally expands as the conversation proceeds, but no explicit short‑term tools are used yet.
Stage 2 – Short‑Term Memory Control Under Distractors
The short‑term buffer is cleared, while the long‑term store remains intact. The agent now receives a stream of distractor sentences that are tangential to the final goal. Here, SUMMARY and FILTER become essential: the model must compress useful information and discard noise, learning to keep the prompt length manageable without losing critical cues.
Stage 3 – Integrated Reasoning and Retrieval
A final query arrives that requires the agent to combine long‑term knowledge with the refined short‑term context. The model calls RETRIEVE to pull relevant memories, may apply another SUMMARY to fit within token limits, and finally produces the answer. Success in this stage demonstrates true end‑to‑end memory reasoning.
Training uses a step‑wise variant of Group Relative Policy Optimization (GRPO). Multiple trajectories are sampled per task, a terminal reward is computed, and the advantage is broadcast to every step, allowing the policy to learn which tool calls contributed most to the final outcome.
Reward Composition
- Task Reward: Quality of the final answer (LLM judge score 0‑1).
- Context Reward: Effectiveness of short‑term operations (compression ratio, relevance).
- Memory Reward: Quality of stored items, usefulness of retrievals, and proper deletion of stale data.
- Penalty: Exceeding dialogue length or token overflow.
Experimental Results: Benchmarks and Performance Gains
The authors fine‑tuned AgeMem on the HotpotQA training split and evaluated it across five diverse benchmarks:
- ALFWorld – text‑based embodied tasks.
- SciWorld – scientific reasoning environments.
- BabyAI – instruction‑following challenges.
- PDDL – planning problems.
- HotpotQA – multi‑hop question answering.
Two backbone models were used: Qwen2.5‑7B‑Instruct and Qwen3‑4B‑Instruct. AgeMem consistently outperformed strong baselines (LangMem, A Mem, Mem0, Mem0g) on every metric.
| Model | Backbone | Avg. Score (5 Benchmarks) | HotpotQA Judge | Token Savings (STM tools) |
|---|---|---|---|---|
| AgeMem | Qwen2.5‑7B‑Instruct | 41.96 | 0.533 | ≈ 4 % |
| Mem0 (best baseline) | Qwen2.5‑7B‑Instruct | 37.14 | 0.471 | — |
| AgeMem | Qwen3‑4B‑Instruct | 54.31 | 0.605 | ≈ 3 % |
| A Mem (best baseline) | Qwen3‑4B‑Instruct | 45.74 | 0.542 | — |
Key takeaways from the experiments:
- AgeMem improves average benchmark scores by 7–9 points over the strongest baselines.
- Memory quality metrics (LLM‑evaluated relevance of stored facts) rise by 12 % on HotpotQA.
- Short‑term memory tools reduce prompt length by 3‑5 % without hurting accuracy, confirming that learned summarization and filtering can replace costly retrieval‑augmented pipelines.
- Ablation studies show that each component—long‑term tools, short‑term tools, and RL fine‑tuning—contributes additively to performance.
What AgeMem Means for the Next Generation of LLM Agents
The success of AgeMem reshapes several assumptions about agent design:
- Unified Policy Over Separate Modules: By folding memory actions into the same policy that generates text, agents avoid the latency and brittleness of external controllers.
- End‑to‑End Credit Assignment: RL can now reward or penalize specific memory decisions, leading to more efficient use of token budgets.
- Scalable Context Management: Learned
SUMMARYandFILTERtools adapt to any token limit, making agents future‑proof for models with 100k‑token windows. - Domain‑Agnostic Memory Skills: The same tool set works for embodied tasks (ALFWorld), scientific reasoning (SciWorld), and classic QA, suggesting a universal memory API for all AI products.
For enterprises building AI‑driven assistants, the AgeMem paradigm offers a clear path to reduce infrastructure costs (fewer external vector stores) while boosting reliability. The framework also aligns with emerging regulations that demand transparent data handling—each memory operation is logged as a tool call, providing an audit trail.
How UBOS Helps You Build Agentic Memory Systems
UBOS provides a full‑stack platform that makes implementing AgeMem‑style agents fast and secure. Below are some UBOS resources that map directly to the AgeMem components:
- UBOS homepage – Overview of the platform’s AI‑first architecture.
- UBOS platform overview – Learn how the low‑code environment supports custom tool creation.
- Workflow automation studio – Design RL‑style training loops without writing boilerplate code.
- Web app editor on UBOS – Rapidly prototype the
<think>/<tool_call>protocol. - AI marketing agents – Pre‑built agents that already leverage memory tools for campaign optimization.
- UBOS partner program – Collaborate with UBOS to co‑develop advanced memory modules.
- UBOS pricing plans – Choose a plan that fits your compute budget for RL training.
- UBOS templates for quick start – Jump‑start a memory‑aware agent with ready‑made templates.
- UBOS portfolio examples – See real‑world deployments of agents that manage knowledge bases.
- Enterprise AI platform by UBOS – Scale AgeMem‑style agents across large organizations.
- UBOS for startups – Fast‑track your AI product with built‑in memory tooling.
- UBOS solutions for SMBs – Affordable memory‑enhanced assistants for small teams.
- Telegram integration on UBOS – Deploy your AgeMem agent as a Telegram bot.
- ChatGPT and Telegram integration – Combine OpenAI’s LLMs with UBOS memory tools.
- OpenAI ChatGPT integration – Leverage ChatGPT as the language core while UBOS handles memory.
- Chroma DB integration – Use a vector store that works seamlessly with AgeMem’s
RETRIEVEtool. - ElevenLabs AI voice integration – Turn your memory‑aware agent into a spoken assistant.
- AI SEO Analyzer – Example of a UBOS template that already uses short‑term summarization.
- AI Article Copywriter – Demonstrates long‑term knowledge retention across multiple drafts.
- AI Video Generator – Shows how memory tools can manage storyboard assets.
- Talk with Claude AI app – A conversational agent that benefits from unified memory handling.
Takeaway: Build Smarter, Self‑Managing LLM Agents Today
AgeMem proves that memory need not be an afterthought. By exposing storage, retrieval, summarization, and forgetting as learnable actions, developers can train agents that are both more capable and more efficient. The framework’s three‑stage RL regimen ensures that agents understand the long‑term value of each memory decision, leading to measurable gains on a wide range of benchmarks.
If you’re ready to experiment with agentic memory in your own products, start with UBOS’s low‑code environment, leverage the ready‑made templates, and connect to your preferred vector store (e.g., Chroma DB integration). Whether you’re a startup, an SMB, or an enterprise, UBOS offers the tools, pricing, and partner ecosystem to accelerate your journey.
Explore the UBOS platform now and turn the AgeMem research breakthrough into a production‑ready AI assistant that truly remembers, reasons, and forgets when it should.
© 2026 UBOS Technologies. All rights reserved.