
- Updated: February 25, 2026
- 6 min read
Liquid AI Unveils LFM2‑24B‑A2B Hybrid Model – Edge‑Ready 24B LLM with Convolution‑Attention Fusion
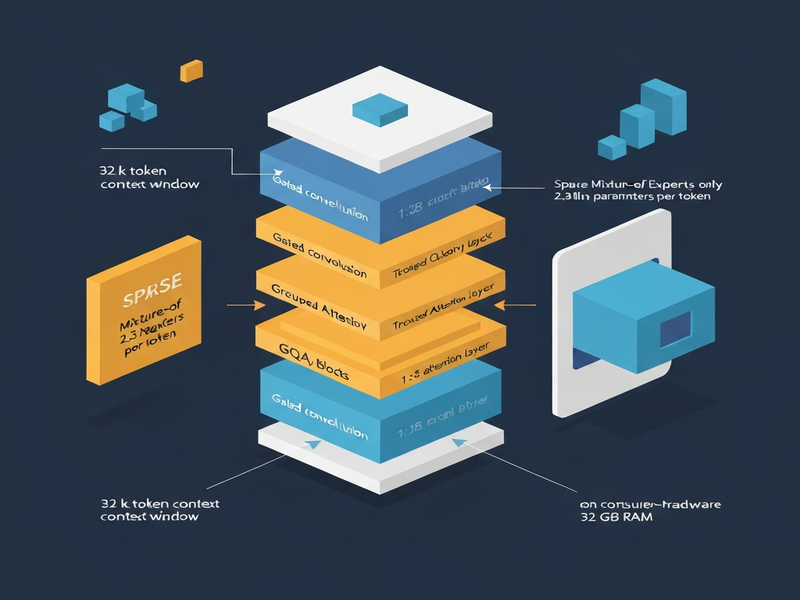
Liquid AI’s LFM2‑24B‑A2B hybrid architecture delivers 24‑billion‑parameter performance on edge devices while activating only 2.3 billion parameters per token, enabling 32 GB RAM deployment and a 32k token context window.
Why the LFM2‑24B‑A2B model matters now
As generative AI scales, power consumption and memory bottlenecks have become the new limiting factors. MarkTechPost’s coverage highlights that Liquid AI’s latest release flips the traditional “bigger is better” narrative by marrying attention mechanisms with gated convolutions. The result is a model that can run on a high‑end laptop or an on‑premise NPU without the need for a data‑center‑grade GPU.
Liquid AI and the birth of the LFM2‑24B‑A2B hybrid
Liquid AI, a research‑focused startup, has spent the last two years redesigning the core building blocks of large language models (LLMs). Their flagship offering, the LFM2‑24B‑A2B, combines a 24‑billion‑parameter backbone with a novel “Attention‑to‑Base” (A2B) ratio of 1:3. In practice, this means that for every attention‑heavy layer, three layers are dedicated to efficient gated short‑convolution blocks.
The model’s architecture is openly licensed under the LFM Open License v1.0, encouraging community adoption and integration with popular inference runtimes such as OpenAI ChatGPT integration, ChatGPT and Telegram integration, and Chroma DB integration.
Technical deep‑dive: hybrid A2B architecture
1. Gated short‑convolution blocks (Base layers)
Base layers replace the classic self‑attention stack with gated convolutions that operate in linear time (O(N)). These blocks preserve local context while dramatically shrinking the KV cache that typically inflates VRAM usage in pure‑Transformer models.
2. Grouped Query Attention (GQA)
Only 10 out of the 40 total layers employ Grouped Query Attention. GQA reduces the quadratic cost of traditional softmax attention by grouping queries, allowing the model to retain high‑resolution reasoning capabilities without the memory explosion.
3. Sparse Mixture of Experts (MoE)
The LFM2‑24B‑A2B uses a sparse MoE where each token activates a subset of experts, limiting active parameters to roughly 2.3 B. This “2 B‑budget” design is the key to fitting the model into 32 GB of RAM, making edge deployment feasible.
4. Long‑context window
With a 32k token context length, the model excels at Retrieval‑Augmented Generation (RAG) pipelines, privacy‑sensitive document analysis, and multi‑turn conversations that require extensive memory.
5. Hardware‑in‑the‑loop architecture search
Liquid AI performed a hardware‑aware neural architecture search, ensuring that the final topology aligns with the memory and compute constraints of consumer‑grade GPUs, integrated GPUs (iGPUs), and emerging NPUs.
Technical Cheat Sheet
| Property | Specification |
|---|---|
| Total Parameters | 24 B |
| Active Parameters | 2.3 B |
| Architecture | Hybrid (Gated Conv + GQA) |
| Layers | 40 (30 Base / 10 Attention) |
| Context Length | 32,768 tokens |
| Training Data | 17 T tokens |
| License | LFM Open License v1.0 |
| Native Support | llama.cpp, vLLM, SGLang, MLX |
Performance highlights
- Edge‑friendly memory footprint: Fits comfortably in 32 GB RAM, enabling deployment on laptops, desktops with iGPUs, and emerging AI accelerators.
- Throughput: On a single NVIDIA H100, the model processes 26.8 K tokens per second with 1,024 concurrent requests, outpacing larger rivals such as Snowflake’s gpt‑oss‑20B and Qwen3‑30B‑A3B.
- Long‑context efficiency: The 32k token window reduces the need for chunking in RAG workflows, improving latency and answer fidelity.
- Benchmark supremacy: On GSM8K and MATH‑500, LFM2‑24B‑A2B matches or exceeds dense models that are twice its size, demonstrating that sparse MoE does not sacrifice reasoning depth.
These results are especially relevant for teams building AI‑driven products on the UBOS platform overview, where low‑latency inference and cost‑effective scaling are top priorities.
Market impact and potential use‑cases
The LFM2‑24B‑A2B model arrives at a moment when enterprises are demanding AI that can run locally for data‑privacy, latency, and cost reasons. Below are three high‑impact scenarios where the hybrid architecture shines:
Enterprise‑grade knowledge assistants
Companies can embed the model in internal knowledge bases, delivering instant, context‑aware answers without sending proprietary data to the cloud. The 32k token context window makes it ideal for multi‑document retrieval, while the 2.3 B active parameters keep inference costs low.
AI‑enhanced SaaS products
Startups building AI‑first SaaS can leverage the model through the UBOS for startups program, integrating it with the Web app editor on UBOS and the Workflow automation studio. Use‑cases include automated report generation, intelligent email drafting, and real‑time code assistance.
Edge AI for field devices
Manufacturing, logistics, and retail environments can run the model on edge gateways or rugged laptops, enabling on‑device anomaly detection, voice‑controlled assistants, and localized translation without relying on flaky internet connections.
For marketers, the model can power AI marketing agents that generate copy, analyze sentiment, and personalize campaigns at scale, all while staying within a predictable budget thanks to the sparse MoE design.
What’s next for developers?
If you’re ready to experiment with a cutting‑edge LLM that balances size, speed, and memory, explore the following resources on UBOS:
- Enterprise AI platform by UBOS – a managed environment for deploying hybrid models at scale.
- UBOS solutions for SMBs – affordable plans that include GPU‑accelerated inference.
- UBOS pricing plans – transparent pricing that aligns with the 2 B‑budget nature of the LFM2‑24B‑A2B.
- UBOS portfolio examples – real‑world case studies of edge‑deployed LLMs.
- UBOS templates for quick start – pre‑built pipelines that integrate the model with RAG, chat, and voice interfaces.
For a hands‑on demo, try the AI SEO Analyzer template, which showcases the model’s ability to process long documents and generate actionable insights in seconds.
Finally, stay connected with the broader AI community through the About UBOS page and consider joining the UBOS partner program to co‑create next‑generation AI solutions.
Conclusion
Liquid AI’s LFM2‑24B‑A2B hybrid architecture proves that smarter design can outpace raw scale. By blending gated convolutions, Grouped Query Attention, and a sparse Mixture of Experts, the model delivers 24‑billion‑parameter intelligence on a 2‑billion‑parameter budget, unlocking true edge deployment for enterprises, startups, and developers alike.
Whether you’re building a knowledge‑base assistant, an AI‑enhanced SaaS product, or an on‑device voice agent, the LFM2‑24B‑A2B offers a compelling blend of performance, efficiency, and flexibility. Explore the UBOS ecosystem to bring this breakthrough model into your stack today.