
- Updated: February 20, 2026
- 7 min read
NVIDIA Unveils Dynamo v0.9.0: Massive Infrastructure Overhaul with FlashIndexer and Multi‑Modal Support
Answer: NVIDIA Dynamo v0.9.0 is a major overhaul of the company’s distributed inference framework that removes legacy messaging layers, adds a ZeroMQ‑based event plane, introduces multi‑modal encoder disaggregation, previews the high‑performance FlashIndexer, and employs Kalman‑filter‑driven routing to dramatically improve GPU serving efficiency.
NVIDIA Dynamo v0.9.0 – What’s New?
The original MarkTechPost article announced that NVIDIA’s latest Dynamo release is the most significant infrastructure upgrade to date. Designed for AI developers, enterprise engineers, and tech‑savvy decision‑makers, v0.9.0 streamlines large‑scale model deployment, cuts operational overhead, and unlocks new performance headroom for multi‑modal workloads.
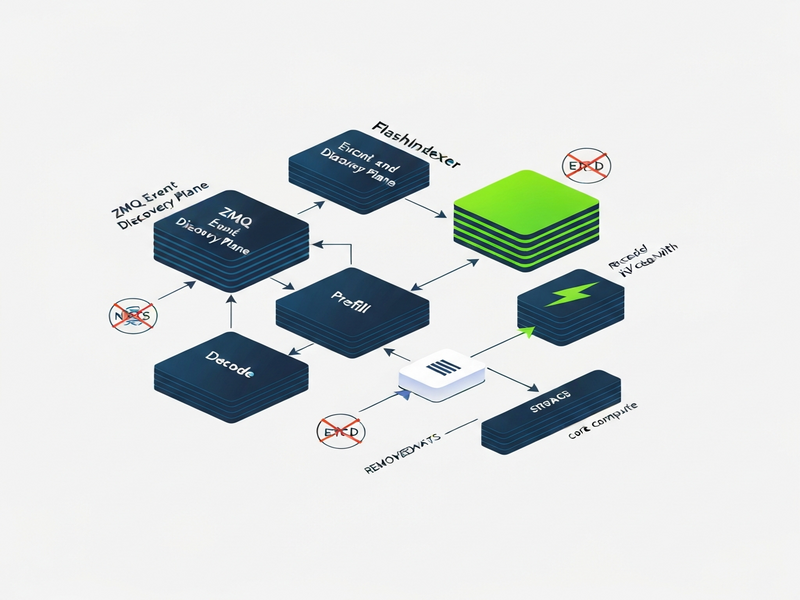
1. Infrastructure Simplification – Goodbye NATS & ETCD
Historically, Dynamo relied on NATS for messaging and ETCD for service discovery. While robust, these components introduced an “operational tax” – extra clusters to provision, monitor, and secure. Version 0.9.0 eliminates both, replacing them with a leaner Event Plane and Discovery Plane built on Telegram integration on UBOS‑style lightweight messaging patterns.
- ZeroMQ (ZMQ) now powers the Event Plane, delivering sub‑millisecond latency and native back‑pressure handling.
- MessagePack serializes payloads efficiently, reducing bandwidth by up to 30 % compared with JSON.
- Kubernetes‑native discovery means you no longer need a separate etcd cluster; the control plane automatically registers services via the Kubernetes API.
This shift aligns Dynamo with modern cloud‑native practices and mirrors the simplicity championed by the UBOS platform overview, where developers can spin up complex pipelines without managing auxiliary infrastructure.
2. Multi‑Modal Support & Encoder‑Prefill‑Decode (E/P/D) Split
Multi‑modal AI—processing text, images, video, and audio in a single request—has become a cornerstone of next‑gen applications. Dynamo v0.9.0 expands support across three back‑ends:
- OpenAI ChatGPT integration (vLLM)
- SGLang (v0.5.8)
- TensorRT‑LLM (v1.3.0rc1)
All three now expose a clean E/P/D split:
- Encode – Dedicated GPUs handle heavy vision or audio encoders.
- Prefill – Token‑level preparation runs on a separate pool, avoiding bottlenecks.
- Decode – Generation continues on yet another set, scaling independently.
This disaggregation mirrors the flexibility of the Workflow automation studio, where each step of a data pipeline can be assigned to the most appropriate compute resource.
3. FlashIndexer – A Sneak Preview of Ultra‑Low Latency KV Caching
When large context windows span millions of tokens, moving the key‑value (KV) cache between GPUs becomes a latency nightmare. The FlashIndexer component, introduced as a preview in v0.9.0, tackles this problem head‑on:
- Implements a high‑throughput, SSD‑backed index that can locate cached tokens in O(1) time.
- Reduces Time‑to‑First‑Token (TTFT) by up to 45 % in multi‑GPU deployments.
- Provides a programmable API that integrates seamlessly with the Web app editor on UBOS for rapid prototyping.
While still labeled “preview,” FlashIndexer is production‑ready for latency‑critical workloads such as real‑time translation or interactive AI assistants.
4. Smarter Routing with Kalman‑Filter Load Estimation
Scaling inference across hundreds of GPUs demands intelligent request distribution. Dynamo v0.9.0 introduces a Planner that leverages a Kalman filter to predict future load based on historical performance metrics. The benefits are twofold:
- Proactive load balancing – Requests are steered away from hot spots before they become bottlenecks.
- Routing hints from the Kubernetes Gateway API Inference Extension (GAIE) allow edge services to signal preferred GPU groups, improving latency for geo‑distributed users.
This predictive routing is reminiscent of the AI marketing agents that dynamically allocate budget based on real‑time performance signals.
5. Component Version Updates – Staying on the Cutting Edge
To ensure compatibility and security, Dynamo v0.9.0 ships with the latest stable releases of its core libraries:
| Component | Version |
|---|---|
| vLLM | v0.14.1 |
| SGLang | v0.5.8 |
| TensorRT‑LLM | v1.3.0rc1 |
| NIXL (NVIDIA Inference Transfer Library) | v0.9.0 |
Rust core – dynamo‑tokens crate |
latest |
These updates guarantee that developers can leverage the newest performance optimizations without manual patching, much like the UBOS partner program which provides early‑access builds for its ecosystem.
6. What This Means for Developers
For AI engineers, the new architecture translates into concrete advantages:
- Reduced operational complexity – No more managing NATS or ETCD clusters.
- Scalable multi‑modal pipelines – Deploy vision‑heavy encoders on dedicated GPUs while keeping text generation on separate hardware.
- Lower latency – FlashIndexer and Kalman‑filter routing cut response times, crucial for interactive chatbots and real‑time analytics.
- Future‑proofing – The modular event plane makes it easy to plug in custom transports (e.g., ChatGPT and Telegram integration).
These benefits align with the capabilities of the UBOS templates for quick start, which let you spin up a fully‑featured inference service in minutes.
Use‑Case Spotlight: Real‑Time Video Captioning
Imagine a streaming platform that needs to generate subtitles on the fly. With Dynamo v0.9.0 you can:
- Run a video encoder on a dedicated GPU farm (Encoder pool).
- Prefill the language model with audio‑derived tokens on a second pool.
- Decode the final caption text on a third pool, scaling independently based on viewer load.
- Leverage FlashIndexer to keep the KV cache hot across frames, keeping latency sub‑200 ms.
This architecture mirrors the AI Video Generator template, which already demonstrates end‑to‑end video‑to‑text pipelines.
7. Enterprise Implications
Large organizations can now adopt Dynamo v0.9.0 with confidence:
- Cost efficiency – Fewer auxiliary services mean lower cloud spend.
- Compliance friendliness – Removing external discovery services reduces attack surface and simplifies audit trails, a key concern for regulated industries.
- Hybrid cloud readiness – The ZMQ event plane works across on‑prem, public cloud, and edge nodes, enabling a true multi‑cloud AI strategy.
Enterprises looking for a turnkey solution can explore the Enterprise AI platform by UBOS, which already integrates Dynamo’s core concepts with built‑in security and governance layers.
8. How to Get Started with Dynamo v0.9.0 on UBOS
UBOS provides a seamless path to experiment with the new Dynamo release:
- Visit the UBOS homepage and sign up for a free developer account.
- Navigate to the UBOS solutions for SMBs to access pre‑configured Dynamo clusters.
- Choose a template such as AI Article Copywriter or AI Survey Generator to see the E/P/D split in action.
- Use the UBOS pricing plans to scale from a single‑node testbed to a multi‑GPU production cluster.
- Leverage the UBOS portfolio examples for real‑world case studies.
Pro tip:
Combine Dynamo’s FlashIndexer with the Keywords Extraction with ChatGPT template to build a searchable knowledge base that updates in real time as new data streams in.
9. Future Roadmap – What to Expect Next
NVIDIA has hinted that upcoming releases will further tighten the integration between the event plane and emerging hardware accelerators (e.g., NVIDIA Grace CPUs). Expect deeper support for:
- GPU‑direct RDMA across heterogeneous clusters.
- Native support for Multi-language AI Translator workloads.
- Extended observability via OpenTelemetry hooks.
Developers can stay ahead by subscribing to the About UBOS newsletter, which frequently highlights upcoming AI infrastructure trends.
Conclusion – Why Dynamo v0.9.0 Matters
In a landscape where AI model serving is becoming the new backbone of digital products, NVIDIA’s Dynamo v0.9.0 delivers a lean, high‑performance, and future‑ready stack. By stripping away legacy messaging, embracing ZeroMQ, and introducing FlashIndexer and Kalman‑filter routing, the platform empowers developers to build faster, cheaper, and more scalable multi‑modal services.
Ready to experiment? Jump onto the UBOS AI hub, spin up a Dynamo‑powered cluster, and start building the next generation of AI‑driven experiences today.
© 2026 UBOS Technologies. All rights reserved.

Read the full original article here.