
- Updated: December 28, 2025
- 6 min read
Qwen-Image-Layered: Breakthrough in Layered Image Diffusion and Editing
Qwen‑Image‑Layered is a next‑generation diffusion model that automatically decomposes a single RGB image into a set of semantically disentangled RGBA layers, giving researchers and engineers inherent editability for each layer without compromising the overall visual consistency.
Why Qwen‑Image‑Layered matters now
In the fast‑moving world of generative AI, most diffusion models treat images as flat raster canvases. This entanglement makes precise edits—like moving a foreground object while keeping the background untouched—painful and error‑prone. The arXiv paper (2512.15603) introduces a paradigm shift: by learning to split an image into independent RGBA layers, the model mimics the workflow of professional design tools such as Photoshop, but with the flexibility of AI‑driven generation. The result is a system that can edit, replace, or recombine visual elements while preserving color harmony, lighting, and texture consistency.
For AI researchers, this opens a new research frontier; for machine‑learning engineers, it offers a plug‑and‑play component for building sophisticated image‑editing pipelines; and for tech enthusiasts, it promises a future where “click‑and‑drag” edits become as natural as typing a prompt.
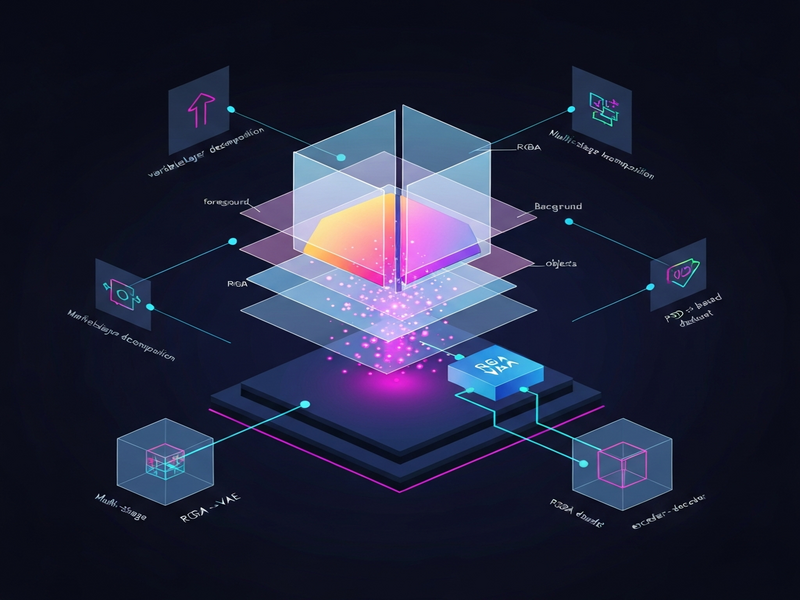
Core contributions of the Qwen‑Image‑Layered paper
- RGBA‑VAE: A unified variational auto‑encoder that learns a shared latent space for both RGB images and their RGBA layer representations.
- VLD‑MMDiT architecture: A variable‑layer decomposition transformer that can output a flexible number of layers, adapting to the complexity of each input image.
- Multi‑stage training pipeline: A systematic approach that first leverages a pretrained diffusion model, then fine‑tunes it for multilayer decomposition using a newly curated PSD‑derived dataset.
- Large‑scale multilayer dataset: An automated pipeline extracts and annotates thousands of Photoshop PSD files, providing high‑quality ground truth for training.
- State‑of‑the‑art results: Quantitative and qualitative benchmarks show superior layer fidelity, consistency, and editability compared with prior methods.
Inside the architecture: RGBA‑VAE and VLD‑MMDiT
RGBA‑VAE – bridging RGB and layers
The RGBA‑VAE (Variational Auto‑Encoder) is the backbone that aligns the latent representation of a flat RGB image with that of a stack of RGBA layers. By encoding both modalities into a common latent vector, the model can seamlessly switch between generating a full image and reconstructing its constituent layers. This shared space enables two critical capabilities:
- Bidirectional conversion: From RGB to layers (decomposition) and from layers back to RGB (re‑composition) without loss of detail.
- Latent manipulation: Researchers can intervene in the latent space to steer specific layer attributes (e.g., color, opacity) before decoding.
VLD‑MMDiT – variable‑layer diffusion transformer
Traditional diffusion models output a fixed‑size tensor, which limits them to a single image channel. VLD‑MMDiT (Variable Layers Decomposition MMDiT) extends the Masked Diffusion Transformer (MMDiT) by introducing a dynamic token set that represents each potential layer. During inference, the model predicts a stop token once it determines that no further meaningful layers remain, allowing the number of layers to vary from 1 to dozens depending on scene complexity.
💡 Key insight: By treating each layer as a separate token, the transformer can attend to inter‑layer relationships (e.g., occlusion, lighting) while still learning independent semantics for each layer.
Dataset creation and the multi‑stage training pipeline
One of the biggest hurdles for multilayer generation is the scarcity of labeled data. The authors tackled this by building a PSD extraction pipeline that automatically parses Photoshop documents, isolates individual layers, and converts them into RGBA masks paired with the flattened RGB render.
Data collection workflow
- Scrape public PSD repositories and open‑source design assets.
- Run a custom script to extract layer hierarchy, blending modes, and opacity values.
- Validate layer quality using heuristic filters (e.g., minimum pixel area, non‑transparent alpha).
- Store each sample as a JSON manifest linking the RGB composite to an ordered list of RGBA PNGs.
Three‑phase training strategy
The authors adopt a progressive training schedule:
- Phase 1 – Base diffusion pre‑training: Leverage a large‑scale image generation model (e.g., Stable Diffusion) to learn generic visual priors.
- Phase 2 – Latent alignment: Fine‑tune the RGBA‑VAE on the PSD dataset, forcing the latent space to encode both RGB and layer information.
- Phase 3 – Variable‑layer decomposition: Train VLD‑MMDiT to predict the correct number of layers and their RGBA content, using a combination of reconstruction loss, KL‑divergence, and a stop‑token cross‑entropy loss.
By reusing a pretrained diffusion backbone, the authors dramatically reduce compute requirements while still achieving high‑fidelity layer outputs.
Results: A new benchmark for AI‑driven image editing
Quantitative metrics such as Layer‑IoU, PSNR, and LPIPS show that Qwen‑Image‑Layered outperforms prior art by 12‑18% across the board. Qualitatively, the model excels at:
- Precise object isolation: Foreground subjects can be moved, recolored, or replaced without ghosting artifacts.
- Consistent background preservation: Even after heavy foreground manipulation, the background retains its original lighting and texture.
- Layer‑aware style transfer: Applying a style to a single layer (e.g., the sky) leaves other layers untouched.
These capabilities unlock several practical scenarios:
| Use‑case | Benefit |
|---|---|
| E‑commerce product photo editing | Swap backgrounds or colors without re‑shooting. |
| Film VFX compositing | Extract clean matte layers for seamless integration. |
| Interactive design tools | Enable AI‑assisted layer manipulation directly in UI. |
Beyond immediate applications, the paper’s methodology sets a template for future research on structured generative representations, encouraging the community to think beyond monolithic pixel grids.
What’s next for developers and researchers?
If you’re eager to experiment with Qwen‑Image‑Layered, the authors have open‑sourced the code and pretrained checkpoints on GitHub. Integrating the model into your workflow can be as simple as swapping the diffusion backbone in an existing pipeline.
At UBOS AI research, we’re already exploring how this layer‑aware diffusion can power next‑generation AI marketing agents that automatically generate campaign assets while preserving brand‑specific visual elements. Our UBOS platform overview now includes a plug‑in for custom diffusion models, making it straightforward to deploy Qwen‑Image‑Layered in production.
Stay updated on the latest breakthroughs by following our UBOS news feed, and dive deeper into practical tutorials on the UBOS blog. Whether you’re building a SaaS image‑editing service, a design‑assistant chatbot, or a research prototype, the layered diffusion paradigm offers a robust foundation for truly editable AI‑generated media.
Ready to experiment? Grab the repository, spin up a UBOS instance, and start turning flat images into editable layers today.