
- Updated: March 16, 2026
- 6 min read
Moonshot AI Unveils Attention Residuals: Boosting Transformer Scaling and Kimi Linear Performance
Answer: Attention Residuals (AttnRes) replace the static residual‑addition in modern Transformers with a depth‑wise softmax attention mechanism, delivering faster scaling, lower validation loss, and measurable gains when integrated into large‑scale models such as Kimi Linear.
What Are Attention Residuals?
In the classic PreNorm transformer architecture, each layer adds its output to a running hidden state—a practice known as a residual connection. While this stabilises training, Moonshot AI’s recent research shows that the fixed‑weight accumulation creates three hidden bottlenecks:
- No selective access: every layer receives the same blended state, regardless of whether it needs more low‑level or high‑level features.
- Irreversible loss: once information is merged, later layers cannot retrieve a specific earlier representation.
- Output growth: deeper layers inflate their magnitude to stay influential, which can destabilise optimisation.
Attention Residuals solve these issues by letting each layer attend over the stack of previous layer outputs, much like sequence‑wise attention but applied across depth.
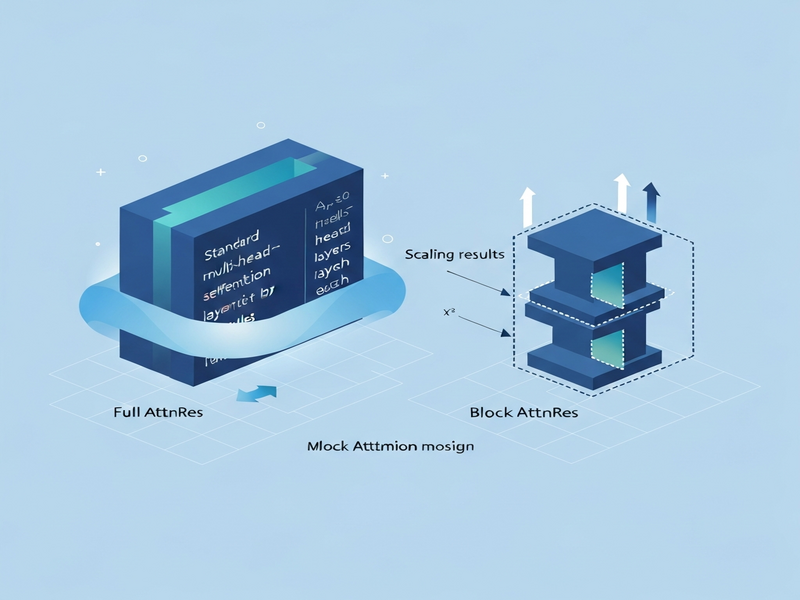
Full AttnRes: Attending Over All Prior Layers
The Full AttnRes variant computes a softmax over every earlier layer’s representation. Each layer owns a learned pseudo‑query vector wₗ ∈ ℝᵈ, while keys and values are the RMS‑normalised outputs of all preceding layers plus the current token embedding. This design has two practical consequences:
- Uniform depth attention: the model can dynamically weight shallow versus deep features for each token.
- Memory‑aware cost: per‑token complexity grows as
O(L²·d)and requires storingO(L·d)activations.
In practice, the extra memory largely overlaps with the activations already needed for back‑propagation. However, under activation recomputation or aggressive pipeline parallelism, the overhead becomes noticeable because earlier outputs must be retained across stages.
Block AttnRes: A Scalable Variant for Large Models
To keep the benefits of depth‑wise attention while curbing the quadratic cost, Moonshot AI introduced Block AttnRes. The model partitions the L layers into N blocks (e.g., eight blocks for a 96‑layer network). Within each block, outputs are aggregated into a single block representation; attention is then performed only over these N block vectors plus the token embedding.
- Memory reduction: from
O(L·d)toO(N·d). - Communication savings: block‑level tensors are far cheaper to exchange in pipeline‑parallel setups.
- Training overhead: less than 4 % extra under pipeline parallelism; inference latency rises by under 2 % on typical workloads.
The authors also describe a two‑phase computation strategy that caches block representations, making Block AttnRes practical for models with billions of parameters.
Scaling Results: How AttnRes Improves Efficiency
Moonshot AI evaluated five model sizes (from 1 B to 48 B parameters) across three configurations: a baseline PreNorm transformer, Full AttnRes, and Block AttnRes (≈8 blocks). All variants shared identical hyper‑parameters, ensuring a fair comparison. The fitted scaling laws were:
| Configuration | Scaling Law (L = a·C^b) |
|---|---|
| Baseline | L = 1.891 × C⁻⁰·⁰⁵⁷ |
| Block AttnRes | L = 1.870 × C⁻⁰·⁰⁵⁸ |
| Full AttnRes | L = 1.865 × C⁻⁰·⁰⁵⁷ |
The lower coefficients indicate that both AttnRes variants achieve a lower validation loss for a given compute budget. Notably, Block AttnRes matches the baseline’s performance while using roughly 1.25× less compute, a substantial efficiency win for large‑scale training.
Integration into Kimi Linear: Real‑World Impact
Moonshot AI’s flagship MoE model, Kimi Linear, contains 48 B total parameters (3 B active per token). The research team integrated AttnRes into Kimi Linear’s depth‑wise pathway and pre‑trained the model on 1.4 T tokens.
Key implementation details:
- All pseudo‑query vectors start at zero, yielding uniform attention at the very beginning and preventing early instability.
- RMSNorm is applied before attention to keep magnitude growth in check.
- Gradient flow becomes more uniform across layers, mitigating the “PreNorm dilution” problem.
Downstream benchmark improvements are consistent across reasoning, coding, and knowledge tasks:
| Benchmark | Baseline | Kimi + AttnRes |
|---|---|---|
| MMLU | 73.5 | 74.6 |
| GPQA‑Diamond | 36.9 | 44.4 |
| BBH | 76.3 | 78.0 |
| Math | 53.5 | 57.1 |
| HumanEval | 59.1 | 62.2 |
| MBPP | 72.0 | 73.9 |
| CMMLU | 82.0 | 82.9 |
| C‑Eval | 79.6 | 82.5 |
The gains come with a modest ≤ 4 % training overhead and ≤ 2 % inference latency increase, making AttnRes a practical upgrade for production‑grade models.
Why This Matters for AI Practitioners
For researchers and engineers building next‑generation transformers, AttnRes offers a drop‑in replacement that:
- Improves scaling efficiency without redesigning the entire architecture.
- Provides finer‑grained control over depth‑wise information flow.
- Reduces the compute budget needed to reach a target validation loss.
- Integrates cleanly with existing MoE pipelines such as Kimi Linear.
Companies that adopt AttnRes can accelerate time‑to‑market for large language models, lower cloud‑compute costs, and achieve higher benchmark scores—all while keeping model latency within acceptable bounds.
External Perspective
For a broader industry view, see the MarkTechPost article that discusses the potential of depth‑wise attention to reshape transformer scaling laws.
How UBOS Can Accelerate Your AttnRes Projects
UBOS provides a suite of tools that make experimenting with Attention Residuals fast and cost‑effective:
- UBOS platform overview – a low‑code environment for building custom transformer pipelines.
- Workflow automation studio – orchestrate data preprocessing, training, and evaluation with drag‑and‑drop nodes.
- Web app editor on UBOS – prototype UI front‑ends for model inference in minutes.
- AI marketing agents – leverage AttnRes‑enhanced LLMs for personalized campaign generation.
- UBOS pricing plans – flexible pay‑as‑you‑go options that align with compute‑intensive research.
- UBOS for startups – accelerate MVP development with pre‑built transformer templates.
- UBOS solutions for SMBs – bring enterprise‑grade AI within reach of mid‑size teams.
- Enterprise AI platform by UBOS – scale AttnRes models across multi‑region clusters.
Template Marketplace: Jump‑Start Your AttnRes Apps
UBOS’s template marketplace hosts ready‑made AI services that can be combined with AttnRes for rapid prototyping:
- AI SEO Analyzer – boost content ranking with depth‑aware language models.
- AI Article Copywriter – generate long‑form copy using AttnRes‑enhanced generation.
- AI Video Generator – create video scripts and storyboards with richer contextual awareness.
- AI Chatbot template – deploy conversational agents that benefit from deeper attention pathways.
Key Takeaways
Attention Residuals replace static residual addition with depth‑wise softmax attention, delivering better scaling, lower compute requirements, and consistent benchmark gains when integrated into large MoE models like Kimi Linear.
Quick Summary (Bullet‑Point Recap)
- Standard residuals cause selective‑access loss, irreversible blending, and output magnitude growth.
- Full AttnRes attends over every prior layer using learned pseudo‑queries.
- Block AttnRes groups layers into blocks, reducing memory/communication from O(Ld) to O(Nd).
- Scaling experiments show AttnRes variants achieve lower validation loss; Block AttnRes matches baseline with ~1.25× less compute.
- Integration into Kimi Linear improves 8 benchmark scores, with ≤ 4 % training overhead.
- UBOS offers a low‑code platform, workflow studio, and ready‑made templates to accelerate AttnRes adoption.
© 2026 UBOS. All rights reserved.