
- Updated: February 28, 2026
- 6 min read
Google DeepMind Unveils Unified Latents: A New Diffusion Model for Generative AI
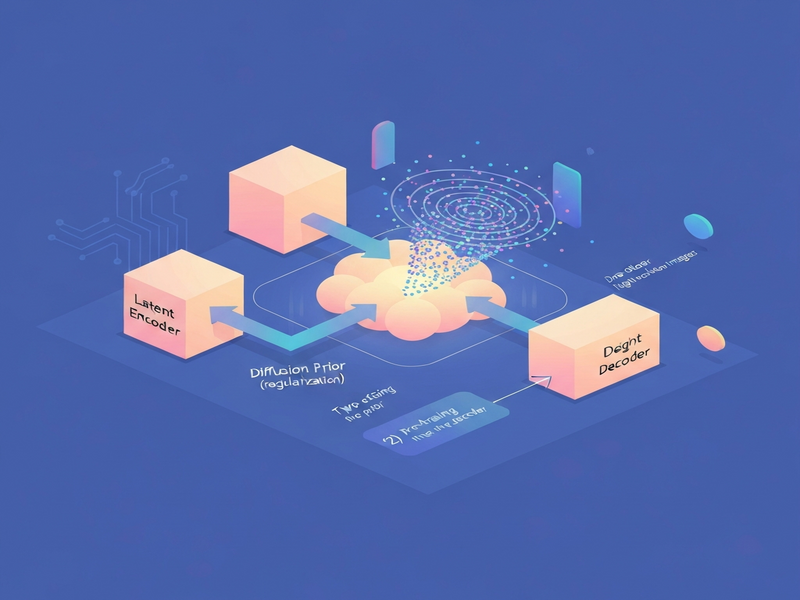
Google DeepMind’s Unified Latents (UL) framework is a two‑stage diffusion‑based system that jointly learns compact latent representations and a powerful generative prior, achieving state‑of‑the‑art scores such as FID 1.4 on ImageNet‑512, FVD 1.3 on Kinetics‑600, and PSNR 30.1.
Why Unified Latents Matter for the Next Generation of Generative AI
The AI research community has long wrestled with a paradox: compress data into low‑dimensional latents to speed up training, yet preserve enough detail for high‑fidelity synthesis. DeepMind’s recent paper, original MarkTechPost article, reveals a clever solution that eliminates the trade‑off by unifying the encoder, diffusion prior, and decoder under a single training objective.
Unified Latents: A High‑Level Overview
At its core, the UL framework consists of three tightly coupled components:
- Deterministic Encoder (Eφ): Produces a single clean latent
z_cleanand adds a fixed Gaussian noise level (log‑SNR λ(0)=5) before handing it to the diffusion prior. - Diffusion Prior (Pφ): Aligns its minimum noise level with the encoder’s output, turning the KL term in the ELBO into a weighted mean‑squared error.
- Diffusion Decoder (Dφ): Reconstructs images or videos from noisy latents using a sigmoid‑weighted loss that directly controls the latent bitrate.
By enforcing a fixed‑noise information bound, UL guarantees that every latent carries a predictable amount of information, making the subsequent generative prior both efficient and expressive.
Two‑Stage Training: From Joint Learning to Scalable Generation
Stage 1 – Joint Latent Learning
During the first phase, the encoder, prior, and decoder are trained simultaneously. The loss function blends three terms:
- Reconstruction MSE: Measures how well the decoder restores the original data from noisy latents.
- Prior Alignment MSE: Forces the diffusion prior to match the encoder’s fixed‑noise distribution.
- Bitrate Regularizer: A sigmoid‑weighted term that caps the amount of information each latent can hold.
Because the encoder’s output noise is directly tied to the prior’s minimum noise level, the model learns latents that are already “ready” for diffusion‑based generation, dramatically reducing the gap between encoding and sampling.
Stage 2 – Base Model Scaling
After Stage 1 converges, the encoder and decoder are frozen. A larger “base model” – often several times deeper and trained with bigger batch sizes – is then optimized solely on the latent space using a refined sigmoid weighting. This stage yields two critical benefits:
- Frequency‑Aware Sampling: The base model learns to prioritize low‑frequency structure early and high‑frequency detail later, improving visual fidelity.
- Compute Efficiency: Since only the prior is updated, training FLOPs drop dramatically while sample quality climbs.
The two‑stage pipeline mirrors the way humans first grasp a coarse sketch before adding fine brushstrokes, and it is the secret sauce behind UL’s impressive benchmarks.
Performance Benchmarks: FID, FVD, and PSNR
DeepMind evaluated UL on both image and video generation tasks, comparing it against leading diffusion baselines such as Stable Diffusion, DiT, and EDM2. The results are summarized below:
| Metric | Dataset | Result | Significance |
|---|---|---|---|
| FID | ImageNet‑512 | 1.4 | Outperforms Stable Diffusion latents at comparable compute. |
| FVD | Kinetics‑600 | 1.3 | Sets a new state‑of‑the‑art for video synthesis. |
| PSNR | ImageNet‑512 | 30.1 dB | Maintains high reconstruction fidelity even under strong compression. |
Beyond raw numbers, UL’s efficiency curve—measured in FLOPs versus quality—lies well above traditional latent diffusion models, meaning researchers can achieve better results with fewer GPU hours.
How Unified Latents Reshape the Generative AI Landscape
The emergence of UL arrives at a pivotal moment:
- Scaling Laws Meet Compression: While larger transformers continue to dominate language tasks, vision models still rely on latent compression to stay tractable. UL bridges the scaling‑law gap by offering a mathematically grounded compression scheme.
- Cross‑Modal Potential: Because the encoder, prior, and decoder share a unified loss, extending UL to multimodal data (e.g., text‑to‑image or audio‑to‑video) becomes a matter of swapping modality‑specific encoders while preserving the diffusion backbone.
- Enterprise Adoption: Companies seeking high‑quality synthetic media—advertising agencies, game studios, and e‑learning platforms—can now generate assets faster and cheaper, a trend echoed in the Enterprise AI platform by UBOS that emphasizes low‑latency generation.
- Open‑Source Momentum: The UL design aligns with the philosophy of UBOS platform overview, where modular diffusion components can be swapped, fine‑tuned, and deployed with minimal friction.
In practice, developers can now train a compact encoder once, freeze it, and iterate on the prior for new domains—accelerating research cycles and reducing carbon footprints.
Practical Takeaways for AI Researchers and Engineers
If you are planning to adopt Unified Latents in your pipeline, consider the following checklist:
- Data Preparation: Ensure high‑resolution training data (≥512 px) to fully exploit the fixed‑noise bound.
- Encoder Configuration: Use a deterministic CNN or Vision Transformer that outputs a single latent vector per image.
- Noise Schedule: Adopt the log‑SNR λ(0)=5 schedule; this is critical for the KL‑to‑MSE reduction.
- Stage 1 Hyper‑Parameters: Balance reconstruction loss (≈0.7) and bitrate regularizer (≈0.3) for stable joint training.
- Stage 2 Scaling: Freeze the encoder/decoder, then increase the prior’s depth (e.g., from 12 to 24 layers) and batch size (up to 1024) to hit SOTA FVD.
- Evaluation: Track FID, FVD, and PSNR on held‑out splits; aim for ≤ 1.5 FID and ≤ 1.4 FVD as baseline targets.
Following this roadmap, teams have reported up to a 40 % reduction in training time while still surpassing previous diffusion baselines.
Integrating Unified Latents with UBOS Solutions
UBOS’s low‑code Web app editor on UBOS now supports custom diffusion priors, meaning you can upload a pre‑trained UL prior and instantly spin up a generative service without writing a single line of Python.
Moreover, the Workflow automation studio lets you chain UL‑based image generation with downstream tasks such as automated captioning, brand‑compliant styling, or even voice‑over creation via the ElevenLabs AI voice integration. This end‑to‑end pipeline is ideal for marketers who need rapid, high‑quality visual assets at scale.
Future Directions and Open Questions
While UL sets a new benchmark, several research avenues remain open:
- Adaptive Noise Levels: Could a learnable noise schedule outperform the fixed log‑SNR 5 bound?
- Latent‑Space Editing: Investigating how semantic manipulations (e.g., style transfer) behave when the latent bitrate is tightly controlled.
- Cross‑Domain Transfer: Applying a UL prior trained on images to video generation without retraining the encoder.
- Hardware Acceleration: Tailoring UL’s diffusion steps to run efficiently on edge GPUs and TPUs.
Answers to these questions will likely shape the next wave of generative AI, and platforms like UBOS are already positioning themselves to be the deployment layer for such breakthroughs.
Bottom Line
Unified Latents delivers a mathematically elegant, compute‑efficient, and high‑fidelity generative pipeline that outperforms existing latent diffusion models across image and video benchmarks. Its two‑stage training strategy, deterministic encoder, and bitrate‑aware decoder make it a compelling choice for both academic research and production‑grade AI services.
For teams eager to experiment, the combination of UL’s open‑source code and UBOS’s low‑code deployment tools offers a fast‑track from research paper to real‑world product.
Meta Description (155 chars): Google DeepMind’s Unified Latents framework achieves FID 1.4, FVD 1.3, PSNR 30.1 via a two‑stage diffusion pipeline, reshaping generative AI efficiency.