
- Updated: March 17, 2026
- 7 min read
OpenClaw Memory System Revolutionizes AI Agents – UBOS News
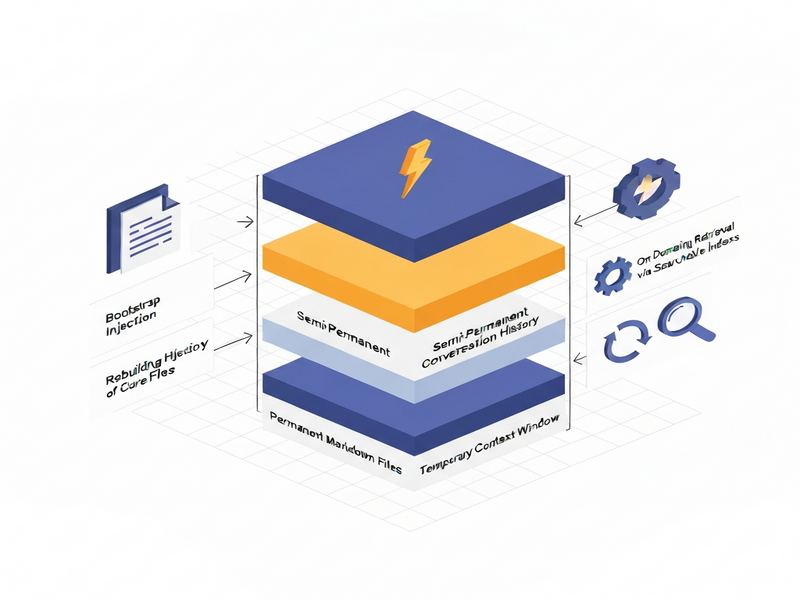
OpenClaw is a tiered memory architecture that lets AI agents store permanent markdown files, retain semi‑permanent conversation histories, and manage a temporary context window, enabling truly “remembering” behavior across sessions.
If you’ve ever chatted with a large language model (LLM) and felt it start from scratch each time, you’re not alone. The original OpenClaw announcement sparked excitement by promising a systematic way to give LLMs a memory that persists beyond a single turn. In this deep dive we unpack the OpenClaw memory system, explore its three storage layers, and explain why it matters for the next generation of AI agents.
OpenClaw Memory System: An Overview
At its core, OpenClaw treats memory as a set of files, indexes, and retrieval mechanisms rather than a modification of the model’s weights. This design choice makes the system transparent, version‑controllable, and extensible. The architecture is divided into three distinct layers, each with its own durability and purpose:
- Permanent markdown files – the long‑term “brain” of the agent.
- Semi‑permanent conversation history – a session‑level log that can be compressed.
- Temporary context window – the short‑term “working memory” the model actually sees.
These layers are orchestrated by three subsystems that decide where information lives, how it enters the model, and when it is retrieved on demand. The result is a predictable, MECE‑structured memory flow that AI agents can rely on.
Component Deep‑Dive
1. Permanent Markdown Files
OpenClaw stores its most stable knowledge in plain‑text markdown files on disk. Because they survive restarts and deployments, they act as the agent’s long‑term memory. The key files include:
SOUL.md– defines the agent’s identity, tone, and core values.AGENTS.md– contains workflow rules, tool permissions, and operational constraints.USER.md– captures user‑specific preferences, project details, and communication style.MEMORY.md– holds facts, decisions, and policies that must persist across all sessions.- Daily log files (e.g.,
memory/2026-03-16.md) – chronological records of tasks, outcomes, and notes.
These files are human‑readable, version‑controlled via Git, and can be edited directly, giving developers full auditability over what the AI “knows.”
2. Semi‑Permanent Conversation History
Every interaction with the agent is saved in a structured JSON‑like format on disk. This conversation history enables session continuity: you can pause a project today and resume tomorrow without losing context.
When the history grows beyond the model’s context limit, OpenClaw automatically compresses older segments into concise summaries. The raw logs remain on disk, but the model only sees the summarized version, trading detail for token efficiency.
3. Temporary Context Window
The context window is the only place the LLM can actually “read.” For Claude‑style models this window is roughly 200 K tokens (≈50 K words). It holds the current user prompt, the agent’s reply, tool call results, and any injected memory snippets.
Because the window is finite, OpenClaw must constantly decide which pieces of information deserve a spot. This is where the three subsystems—bootstrap injection, history rebuild, and on‑demand retrieval—come into play.
How OpenClaw Moves Information: The Three Subsystems
Bootstrap Injection – Auto‑Loading Essentials
When a new session starts, OpenClaw automatically injects a predefined set of markdown files into the context window. These typically include SOUL.md, AGENTS.md, TOOLS.md, IDENTITY.md, and USER.md. The injection logic varies by session type; for example, MEMORY.md is only loaded in private, main sessions, not in group chats.
Because this injection is unconditional, the information is guaranteed to survive even after conversation history is compressed. However, each file consumes up to 20 K characters, and the total bootstrap payload caps at ~150 K characters. Exceeding this limit triggers truncation warnings, and any overflow is effectively invisible to the model.
History Rebuild – Resuming Prior State
When you continue an existing conversation, OpenClaw reads the stored conversation history and reconstructs it into the context window. This “history rebuild” lets the agent recall what was said earlier in the same session.
If the accumulated history exceeds the context capacity, older turns are replaced by their summaries. While this preserves the overall narrative, fine‑grained details (exact phrasing, specific constraints) may be lost—a trade‑off that developers must manage through careful prompt design.
On‑Demand Retrieval – Pulling the Right Fact at the Right Time
Not every piece of knowledge needs to sit in the context permanently. OpenClaw builds a searchable index over all markdown files, supporting both keyword and semantic search. Agents can invoke a memory_search tool to fetch relevant fragments from MEMORY.md, daily logs, or any other file.
Key points about this subsystem:
- Only content that has been written to a file is searchable; ad‑hoc conversation snippets are invisible unless persisted.
- The agent must be prompted (or have rules in
AGENTS.md) to perform the search; otherwise the retrieval engine stays idle. - Search results are injected into the context window on demand, keeping token usage efficient.
Implications for AI Agents
Understanding OpenClaw’s architecture unlocks several strategic advantages for developers building AI agents:
Predictable Memory Behavior
Because persistence is file‑based, you can audit exactly what the agent knows at any time. This transparency satisfies E‑E‑A‑T guidelines and helps with compliance (e.g., GDPR data‑subject requests).
Fine‑Grained Control Over Token Budget
Developers decide which markdown files are bootstrapped, which histories are rebuilt, and when to trigger on‑demand retrieval. This control prevents “token bloat” and keeps costs predictable when using pay‑per‑token LLM APIs.
Modular Agent Design
Sub‑agents can be spawned with a reduced bootstrap set, allowing specialized tasks without loading the full long‑term memory. This modularity mirrors micro‑service patterns and improves scalability.
Enhanced Collaboration Across Teams
Since the memory files are plain markdown, multiple engineers can edit, review, and version them in a shared repository. Teams building AI marketing agents or Enterprise AI platform by UBOS can coordinate without stepping on each other’s toes.
Future‑Proofing with Retrieval Augmented Generation (RAG)
OpenClaw’s on‑demand retrieval is a native RAG implementation. As vector databases and hybrid search improve, you can swap the underlying index without changing the agent’s core logic, keeping the system adaptable to emerging AI research.
Practical Tips to Maximize OpenClaw’s Potential
- Persist Critical Rules in
AGENTS.md– Anything you want the agent to remember forever (e.g., “Never share user passwords”) should be written here, not just spoken during a chat. - Chunk Large Files – Split massive knowledge bases into multiple markdown files (e.g.,
PRODUCTS_01.md,PRODUCTS_02.md) to stay under the 20 K character per‑file limit. - Define Retrieval Triggers – Add explicit prompts in
AGENTS.mdlike “When asked about past project status, runmemory_search('project‑status').” - Leverage Summarization – Use OpenAI’s summarization endpoint to create concise daily log summaries that fit comfortably into the context window.
- Monitor Token Usage – Log the token count of each bootstrap injection; adjust file sizes or move less‑used data to on‑demand retrieval.
Conclusion & Next Steps
OpenClaw transforms the “stateless” nature of LLMs into a structured, auditable memory system that blends permanent files, session logs, and dynamic retrieval. For tech‑savvy professionals and AI enthusiasts, this means building agents that truly remember, adapt, and scale.
Ready to experiment with a memory‑rich AI agent? Explore the UBOS platform overview to spin up a sandbox, or dive straight into the UBOS templates for quick start. Whether you’re a startup looking for a lean solution or an enterprise seeking a robust Enterprise AI platform by UBOS, OpenClaw’s architecture gives you the foundation to build memory‑aware agents that deliver consistent value.
Stay ahead of the AI curve—integrate OpenClaw today and watch your agents evolve from forgetful chatbots into reliable knowledge partners.