
- Updated: June 28, 2026
- 7 min read
VISTA Architect: A Graph Database‑Oriented Health AI System Demonstrated in Multidisciplinary Tumor Boards
{{IMAGE_PLACEHOLDER}}
Direct Answer
VISTA Architect is a graph‑database‑centric AI platform that pre‑processes longitudinal electronic health records into a provenance‑rich knowledge graph and a concise, temporally ordered clinical timeline, enabling large language models to answer tumor‑board queries with near‑human accuracy while avoiding the latency and context‑length limits of traditional retrieval‑augmented generation.
The system matters because it eliminates repeated raw‑text processing, preserves the full audit trail of clinical documentation, and delivers a scalable, specialty‑agnostic foundation for AI‑driven decision support in high‑stakes environments such as multidisciplinary oncology meetings.
Background: Why This Problem Is Hard
Electronic health records (EHRs) are a goldmine of patient information, but the data are stored as heterogeneous, free‑text notes, structured codes, imaging reports, and lab tables that evolve over years. Clinicians need a coherent, temporally accurate view of a patient’s journey to make treatment decisions, especially in tumor boards where dozens of variables—diagnoses, prior therapies, imaging findings—must be synthesized quickly.
Current AI approaches typically fall into two camps:
- Long‑context prompting. Feeding the entire raw record to a large language model (LLM) exceeds token limits, forces truncation, and discards older but clinically relevant events.
- Retrieval‑augmented generation (RAG). A separate search engine (often BM25) pulls snippets at query time, which the LLM then stitches together. RAG struggles with temporal reasoning because retrieved fragments are unordered, and each query incurs the cost of re‑parsing raw notes.
Both strategies suffer from high latency, unpredictable cost, and a loss of provenance—clinicians cannot trace an extracted fact back to the original note without manual effort. In safety‑critical domains, this opacity is unacceptable.
What the Researchers Propose
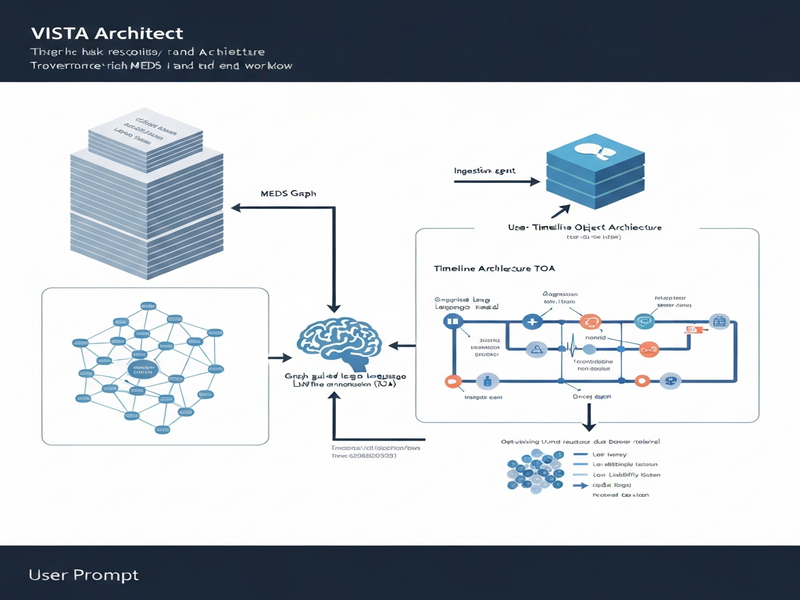
The authors introduce a two‑layer architecture that decouples raw‑record ingestion from downstream query answering:
- MEDS Graph. A source‑faithful, graph‑structured representation that mirrors the original EHR hierarchy (patients, encounters, documents, observations) while attaching immutable provenance metadata to every node.
- Timeline Object Architecture (TOA). A clinically abstracted, deduplicated timeline that aggregates events (e.g., “started pembrolizumab on 2023‑04‑12”) into a temporally coherent sequence. The TOA is generated once using graph‑guided LLM extraction and then cached for fast access.
Key agents in the system include:
- An Ingestion Agent that parses incoming HL7/FHIR bundles, normalizes terminology, and populates the MEDS Graph.
- A Graph‑Guided Extraction Agent that prompts an LLM with structured graph queries, extracts salient events, and writes them into the TOA.
- A Query Orchestrator that routes clinician questions to the TOA for rapid lookup, falling back to the MEDS Graph only when verification or deeper context is required.
How It Works in Practice
The end‑to‑end workflow can be broken into three phases:
- Ingestion & Graph Construction. As new notes arrive, the Ingestion Agent creates nodes for each document, links them to the patient and encounter entities, and records the source file hash, timestamp, and author. This step runs once per record, regardless of how many future queries will touch the data.
- Graph‑Guided Timeline Synthesis. A scheduled job triggers the Extraction Agent, which traverses the MEDS Graph to locate candidate clinical statements (e.g., medication changes, pathology results). The agent formulates concise prompts that embed the graph context, asks the LLM to produce a normalized event object, and writes the result into the TOA. Duplicate events are merged, and temporal conflicts are resolved using a rule‑based validator.
- Agentic Query Interface. When a tumor board member asks, “What systemic therapies has the patient received in the last 12 months?” the Query Orchestrator retrieves the relevant slice of the TOA in milliseconds. If the answer requires nuance—such as “Why was therapy X discontinued?”—the orchestrator presents a link back to the originating document in the MEDS Graph, allowing the clinician to inspect the original note.
What distinguishes VISTA Architect from conventional RAG pipelines is the pre‑computation of the clinical synthesis. By moving the heavy LLM work to an offline stage, the system achieves:
- Predictable latency (< 2 seconds for most queries).
- Reduced token consumption (the TOA typically fits within a few hundred tokens).
- Full auditability (every TOA entry points to a provenance node).
Evaluation & Results
The authors validated the architecture on a real‑world thoracic oncology tumor board at Stanford Medicine. The dataset comprised 1,180 patients and 17,700 expert‑annotated evaluations across 15 tumor‑board‑relevant variables (e.g., staging, molecular markers, prior lines of therapy).
Key evaluation steps:
- Ground‑Truth Comparison. Two board‑certified oncologists independently labeled each variable; inter‑rater agreement exceeded 0.94 (Cohen’s κ).
- Baseline RAG System. A BM25‑based retrieval engine coupled with GPT‑4 served as the comparison point, reflecting a state‑of‑the‑art RAG setup.
- Agentic Interface Test. A separate cohort of 30 patients was processed through an interactive “agentic” UI that let clinicians ask free‑form questions; preparation time per patient was recorded.
Results:
- Overall accuracy on the 15 variables was 96.4 % (mean score 9.75/10), with a 95 % confidence interval of 96.1‑96.7 %.
- The BM25 RAG baseline achieved 89.2 % accuracy, highlighting the advantage of graph‑guided synthesis.
- Agentic interface reduced case‑preparation time to roughly 2.2 minutes per patient, a 70 % speed‑up compared to manual chart review, without any measurable drop in accuracy.
- Latency measurements showed median query response times of 1.8 seconds, versus 7‑12 seconds for on‑the‑fly RAG queries.
These findings demonstrate that pre‑computed, provenance‑linked timelines can deliver near‑human performance while dramatically cutting cost and latency.
Why This Matters for AI Systems and Agents
For AI practitioners building clinical decision‑support tools, VISTA Architect offers a blueprint for reconciling three competing demands: accuracy, speed, and auditability. By anchoring LLM outputs to a graph that preserves the original record, developers can:
- Design agents that reason over structured temporal data rather than raw text, improving reliability in safety‑critical contexts.
- Implement cost‑effective pipelines where expensive LLM calls happen offline, freeing up compute for real‑time inference.
- Provide clinicians with traceable explanations, a prerequisite for regulatory compliance and user trust.
Enterprises looking to scale AI across specialties can reuse the same MEDS‑to‑TOA pattern, simply redefining the event schema (e.g., cardiology events, surgical procedures). The modularity also aligns with emerging UBOS platform overview, where graph databases and workflow automation studios can be orchestrated to automate the ingestion and extraction phases.
Moreover, the agentic UI demonstrated in the study mirrors the capabilities of modern conversational agents such as those built with the OpenAI ChatGPT integration. By feeding the TOA into a chat interface, developers can create “clinical copilots” that answer nuanced queries while automatically surfacing source documents for verification.
What Comes Next
While the results are compelling, several open challenges remain:
- Generalization beyond thoracic oncology. The current event definitions are tuned to lung cancer workflows; extending to other domains will require new ontologies and validation studies.
- Real‑time ingestion. In fast‑moving settings like emergency departments, the latency between note creation and TOA update must shrink to seconds.
- Privacy‑preserving graph sharing. Multi‑institution collaborations could benefit from federated graph queries, but techniques for secure provenance linking are still nascent.
Future research directions include:
- Integrating multimodal data (radiology images, pathology slides) into the MEDS Graph, enabling LLMs to reason over visual findings.
- Applying reinforcement learning to refine the Extraction Agent’s prompts based on downstream query performance.
- Exploring hybrid retrieval strategies that combine graph‑based similarity with vector stores such as Chroma DB integration for rare event lookup.
Healthcare organizations interested in piloting a graph‑first AI stack can start by leveraging the Workflow automation studio to orchestrate data pipelines, then layer on the UBOS templates for quick start that include pre‑built MEDS Graph schemas.
For a deeper dive into the technical details, the full pre‑print is available on VISTA Architect paper on arXiv.
For more information, visit ubos.tech.