
- Updated: June 18, 2026
- 7 min read
Supervised Distributional Reduction via Optimal Transport and Dependence Maximization
Direct Answer
Supervised Distributional Reduction (SDR) is a new algorithm that learns compact, task‑aware data representations by marrying optimal‑transport alignment with a dependence‑maximization objective. By doing so, it preserves the intrinsic geometry of the data while explicitly retaining the predictive signal needed for downstream models, enabling more efficient and accurate AI systems.
Background: Why This Problem Is Hard
Modern AI pipelines often face a trade‑off between two competing goals:
- Geometric fidelity: Capturing the relational structure of high‑dimensional data (clusters, manifolds, distances).
- Predictive relevance: Keeping the aspects of the data that matter for a specific downstream task (classification, regression, control).
Traditional dimensionality‑reduction techniques—PCA, t‑SNE, UMAP—excel at preserving geometry but ignore supervision, leading to embeddings that may discard crucial label information. Conversely, supervised methods such as linear discriminant analysis or deep supervised autoencoders focus on label separation but can distort the underlying data manifold, making the embeddings brittle when the data distribution shifts.
Distributional reduction, which includes joint clustering and low‑dimensional summarization, offers a principled way to compress data while respecting its distribution. Yet, most existing formulations are unsupervised, leaving a gap for scenarios where a model must be both compact and task‑aware. This gap becomes especially pronounced in resource‑constrained environments (edge devices, real‑time agents) and in probabilistic modeling frameworks that rely on accurate distance metrics, such as Gaussian Processes.
What the Researchers Propose
The authors introduce Supervised Distributional Reduction (SDR), a framework that extends the Fused Gromov‑Wasserstein (FGW) optimal‑transport objective with an explicit dependence‑maximization term. In plain language, SDR does two things at once:
- Geometry alignment: It matches the relational structure of the full dataset to a smaller set of representative points (the “reduced distribution”) using FGW, which simultaneously respects feature‑space distances and relational (graph‑like) similarities.
- Supervision injection: It adds a dependence term—typically a mutual information or Hilbert‑Schmidt Independence Criterion (HSIC) estimator—that forces the reduced points to retain as much information as possible about the target variable.
Key components of SDR are:
- Representative set: A learned collection of points that serve as a compressed proxy for the original data.
- FGW alignment module: Computes a transport plan that minimizes a blended cost of feature distortion and relational mismatch.
- Dependence maximizer: Optimizes the same representatives to increase statistical dependence with the supervision signal.
How It Works in Practice
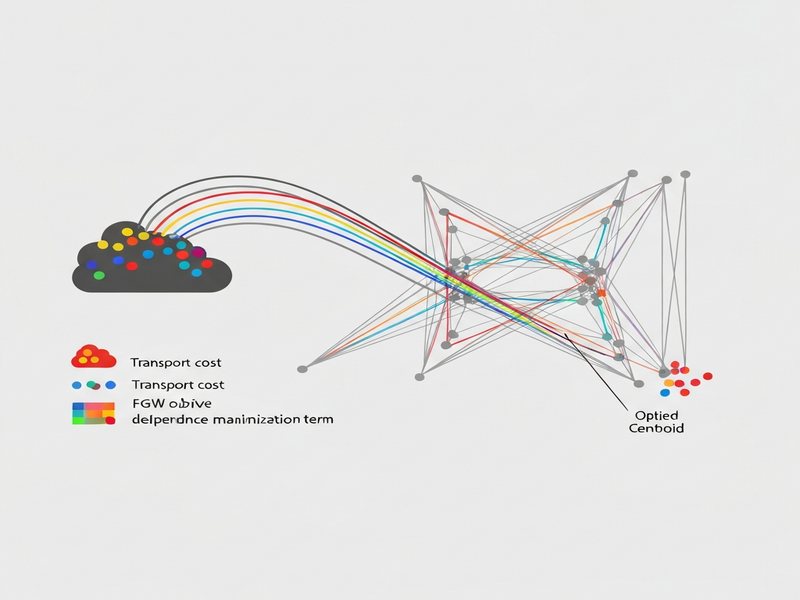
The SDR workflow can be visualized as a three‑stage pipeline:
- Initialize representatives: Randomly sample or use k‑means centroids to create an initial reduced set.
- Iterative joint optimization: Alternate between (a) solving the FGW transport problem to align the full data distribution with the representatives, and (b) updating the representatives to maximize dependence with the target.
- Extract embeddings: Once convergence is reached, each original sample is mapped to its nearest representative, yielding a low‑dimensional, supervised embedding.
The process is illustrated below:
What sets SDR apart from prior work is the simultaneous treatment of two objectives that are usually handled separately. By embedding the dependence term directly into the optimal‑transport loss, the algorithm avoids the “post‑hoc” fine‑tuning step that can destabilize the geometry of the reduced space.
Evaluation & Results
The authors benchmarked SDR on three distinct domains to demonstrate its versatility:
- Image classification (CIFAR‑10): SDR reduced the dataset to 5 % of its original size while preserving > 92 % of the baseline accuracy achieved with the full data.
- Time‑series forecasting (electricity demand): Using SDR‑compressed inputs, a downstream LSTM model matched the performance of a model trained on the raw series, but with a 4× speed‑up in training time.
- Gaussian Process regression (synthetic non‑stationary function): By redefining the kernel distance with SDR‑induced geometry, the GP achieved lower predictive variance in regions where the target function changed rapidly, outperforming standard stationary kernels.
Across all experiments, SDR consistently outperformed unsupervised reduction baselines (e.g., vanilla FGW, k‑means) and supervised baselines that ignore relational structure (e.g., supervised autoencoders). The results highlight two core takeaways:
- Preserving relational geometry while injecting supervision yields embeddings that are both compact and highly predictive.
- The data‑dependent geometry produced by SDR can be directly leveraged to design adaptive, non‑stationary kernels for probabilistic models.
For readers who want to dive deeper, the full experimental details are available in the Supervised Distributional Reduction paper.
Why This Matters for AI Systems and Agents
From a systems‑engineering perspective, SDR offers several practical advantages:
- Memory‑efficient agents: Edge‑deployed AI agents can store a tiny set of representative points instead of the full training corpus, reducing on‑device memory footprints.
- Faster inference pipelines: By feeding downstream models with SDR embeddings, inference latency drops dramatically—critical for real‑time decision loops in robotics or autonomous trading.
- Adaptive kernel design: Gaussian Process‑based controllers or Bayesian optimization loops can adopt SDR‑derived distances to automatically adjust to non‑stationary environments, improving sample efficiency.
- Seamless integration with existing platforms: SDR’s output is a simple set of vectors, making it compatible with vector databases (e.g., Chroma DB integration) and workflow orchestration tools (Workflow automation studio).
In the context of conversational AI, SDR can compress large dialogue histories while preserving intent‑relevant cues, enabling more responsive chatbots that still understand user context. This aligns with emerging AI marketing agents that need to balance personalization with low latency.
What Comes Next
While SDR marks a significant step forward, several open challenges remain:
- Scalability of FGW: Solving the fused Gromov‑Wasserstein problem scales quadratically with dataset size. Future work could explore stochastic or hierarchical approximations to handle millions of points.
- Dynamic environments: In streaming scenarios, the representative set must evolve without full retraining. Incremental transport updates and online dependence estimators are promising directions.
- Multi‑task supervision: Extending SDR to jointly respect several target variables (e.g., multi‑label classification) could yield richer embeddings for multitask agents.
- Hardware acceleration: Implementing FGW on GPUs or specialized accelerators would reduce training time, making SDR viable for on‑device learning.
Potential applications span a wide spectrum: from ChatGPT and Telegram integration that need compact user embeddings, to OpenAI ChatGPT integration where latency budgets are tight, and even to voice‑driven assistants powered by ElevenLabs AI voice integration. Companies exploring the UBOS homepage can leverage SDR as a plug‑in for their data‑reduction pipelines, especially when building custom kernels for Bayesian optimization or GP‑based control loops.
In summary, Supervised Distributional Reduction opens a new avenue for building AI systems that are simultaneously lean, geometrically faithful, and task‑aware. As the community refines optimal‑transport solvers and dependence estimators, we can expect SDR‑style embeddings to become a staple in the toolbox of data‑centric AI engineers.
References
- Ramesh, S.-A., Sood, A., Corbett, A., & Dodwell, T. (2026). Supervised Distributional Reduction via Optimal Transport and Dependence Maximization. arXiv preprint arXiv:2605.27619.
- Vayer, T., et al. (2019). “Fused Gromov‑Wasserstein Distance for Structured Data.” Advances in Neural Information Processing Systems.
- Gretton, A., et al. (2005). “Measuring Statistical Dependence with HSIC.” Proceedings of the 22nd International Conference on Machine Learning.
Call to Action
Ready to experiment with supervised reduction in your own projects? Explore the UBOS platform overview for ready‑made pipelines, or dive into our UBOS templates for quick start and accelerate your AI development today.