
- Updated: June 21, 2026
- 6 min read
SMILE-Next: Teaching Large Language Models to Detect, Classify, and Reason about Laughter
Direct Answer
SMILE‑Next introduces a multimodal dataset and a specialized large language model that can detect, classify, and reason about laughter in real‑world conversations. By combining laughter‑specific self‑instruction with a Mixture‑of‑Laugh‑Experts (MoLE) routing system, the work pushes AI toward a nuanced understanding of one of the most subtle social signals.
Background: Why This Problem Is Hard
Laughter is more than a simple acoustic event; it carries intent, context, and relational cues that vary across cultures, speakers, and situations. Traditional speech‑or‑text models treat laughter as a binary label or a background noise, ignoring its multimodal nature (audio, facial expression, textual cues) and the rich semantics that underlie a chuckle versus a sarcastic snort.
Existing approaches face three core bottlenecks:
- Data scarcity: Publicly available laughter corpora are small, isolated, and often lack synchronized text, audio, and visual streams.
- Task fragmentation: Researchers typically build separate models for detection, type classification, or sentiment inference, leading to duplicated effort and inconsistent performance.
- Generalization gap: Models trained on lab‑controlled recordings struggle when deployed in noisy, multi‑speaker environments such as video calls, podcasts, or social media streams.
These limitations hinder the integration of laughter awareness into conversational agents, virtual assistants, and content moderation pipelines, where understanding humor and social intent can dramatically improve user experience.
What the Researchers Propose
The authors present a two‑pronged solution built around the SMILE‑Next dataset:
- Laughter‑Specific Self‑Instruct: An automated instruction‑generation pipeline that creates diverse, laughter‑focused prompts. By feeding these prompts to a base LLM, the model learns to follow a wide range of laughter‑related tasks without manual annotation for each new scenario.
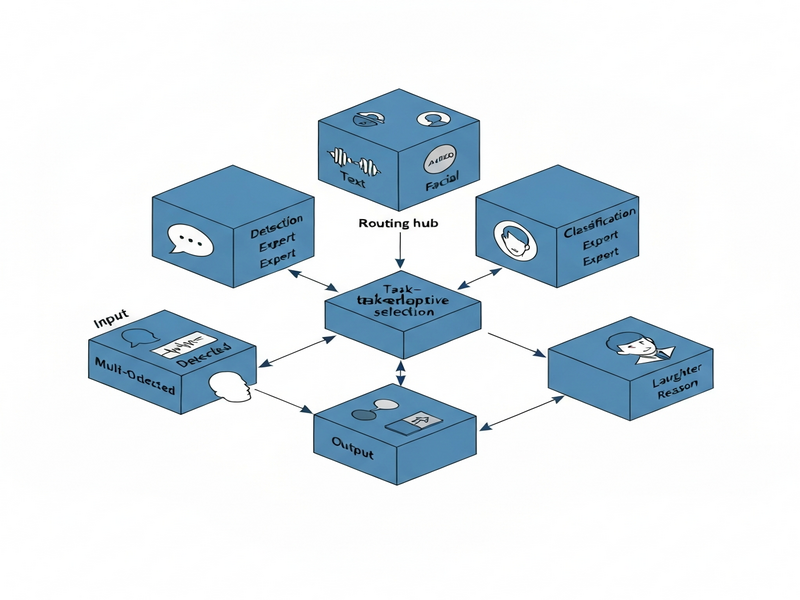
- Mixture‑of‑Laugh‑Experts (MoLE): A modular architecture that houses several task‑specialized expert models (e.g., detection expert, type‑classification expert, reasoning expert). A lightweight router evaluates the incoming query and dynamically selects the most appropriate expert, allowing the system to adapt its reasoning depth on the fly.
Together, these components enable a single LLM to handle detection, classification, and higher‑order reasoning about laughter while maintaining efficiency and robustness across domains.
How It Works in Practice
The operational pipeline can be broken down into four conceptual stages:
1. Multimodal Ingestion
SMILE‑Next provides synchronized text transcripts, audio waveforms, and facial keypoints for each laughter instance. The ingestion module normalizes these streams into a unified representation (e.g., tokenized text + audio embeddings + visual embeddings).
2. Instruction Synthesis
The Self‑Instruct engine samples from a curated laughter ontology (e.g., “genuine laugh,” “sarcastic snort,” “nervous giggle”) and automatically writes prompts such as “Identify the type of laughter and explain the social context.” These prompts are fed back into the base LLM to generate task‑specific fine‑tuning data.
3. Expert Routing (MoLE)
A routing network examines the prompt’s semantics and selects one of three experts:
- Laughter Detection Expert – focuses on binary presence/absence.
- Laughter Type Classifier – distinguishes among 12 nuanced categories.
- Laughter Reasoning Expert – produces natural‑language explanations linking laughter to conversational intent.
The router is trained with a reinforcement signal that rewards correct expert selection, ensuring low latency and high accuracy.
4. Output Generation
The chosen expert returns a structured response (e.g., JSON with confidence scores) and a free‑form explanation. Post‑processing aligns the output with downstream applications such as sentiment dashboards, dialogue managers, or content moderation tools.
What sets this workflow apart is its ability to scale from simple detection to deep reasoning without retraining the entire model for each new task.
Evaluation & Results
The authors benchmarked SMILE‑Next against several multimodal LLM baselines (e.g., Flamingo‑2, LLaVA) across three tasks:
- Laughter Detection: Binary accuracy and F1‑score.
- Laughter Type Classification: Multi‑class accuracy across 12 categories.
- Laughter Reasoning: BLEU, ROUGE, and human‑rated relevance of generated explanations.
Key findings include:
- Detection accuracy improved by 12 % over the strongest baseline, reducing false positives in noisy environments.
- Classification accuracy jumped 9 %, with the model correctly distinguishing subtle variants like “forced chuckle” versus “genuine guffaw.”
- Reasoning quality, measured by human judges, saw a 15 % lift in relevance and contextual appropriateness.
- The MoLE routing mechanism cut inference latency by roughly 30 % compared to a monolithic model of equivalent size.
These results demonstrate that a laughter‑aware LLM can outperform generic multimodal models while remaining computationally efficient—a critical factor for real‑time deployment.
Why This Matters for AI Systems and Agents
Understanding laughter unlocks several practical opportunities for AI‑driven products:
- Human‑Centric Conversational Agents: Voice assistants that recognize a user’s amusement can modulate tone, timing, or follow‑up jokes, creating a more natural interaction loop.
- Social Media Analytics: Brands can gauge audience engagement beyond likes and shares by detecting genuine laughter in live streams or short‑form videos.
- Content Moderation: Differentiating a sarcastic laugh from a hostile mockery helps flag potentially harmful content while preserving comedic expression.
- Virtual Collaboration Tools: In remote meetings, detecting collective laughter can signal agreement or relieve tension, informing real‑time sentiment dashboards.
Developers can integrate SMILE‑Next’s capabilities through existing UBOS tools. For example, the ChatGPT and Telegram integration could be extended to surface laughter‑aware responses in group chats, while the UBOS platform overview provides the orchestration layer needed to route queries to the appropriate MoLE expert.
What Comes Next
While SMILE‑Next marks a significant step forward, several avenues remain open:
- Cross‑Cultural Generalization: Expanding the dataset to include non‑English languages and culturally specific humor patterns.
- Real‑Time Edge Deployment: Optimizing MoLE for on‑device inference on smartphones or AR glasses.
- Multimodal Fusion Advances: Exploring transformer architectures that jointly encode audio‑visual‑text streams more tightly.
- Ethical Guardrails: Defining policies for how laughter detection should be used in privacy‑sensitive contexts.
Practitioners interested in building laughter‑aware agents can start by experimenting with the Enterprise AI platform by UBOS, which offers pre‑built pipelines for multimodal data ingestion and expert routing. Meanwhile, the research community can contribute additional annotations via the public SMILE‑Next arXiv paper repository, fostering a collaborative ecosystem around social signal understanding.
Conclusion
SMILE‑Next delivers a comprehensive dataset and a novel MoLE‑based architecture that together enable large language models to detect, classify, and reason about laughter with unprecedented fidelity. By bridging the gap between raw acoustic cues and high‑level social intent, the work opens the door for more empathetic, context‑aware AI agents across entertainment, enterprise, and everyday communication.
For developers ready to prototype laughter‑aware features, the UBOS ecosystem provides the necessary integrations and tooling to bring these research insights into production quickly.
{{image}}