
- Updated: June 22, 2026
- 7 min read
Routing-Aligned Fine-Tuning for Multilingual Downstream Tasks in Mixture-of-Experts Models
Direct Answer
The paper introduces Routing-Aligned Fine-Tuning (RA‑MoE), a three‑stage method that tailors multilingual Mixture‑of‑Experts (MoE) models to non‑English downstream tasks by aligning the routing behavior of language‑specific experts with the well‑understood English activation patterns. This matters because it unlocks the efficiency and performance gains of MoE scaling for a broader set of languages without requiring massive retraining.
Background: Why This Problem Is Hard
Large language models (LLMs) have become the backbone of modern AI products, from chat assistants to automated content generators. Yet, most of the performance breakthroughs come from English‑centric pre‑training data. When these models are deployed for multilingual use‑cases—customer support in Spanish, sentiment analysis in Hindi, or code generation in Russian—their accuracy often drops dramatically.
Mixture‑of‑Experts architectures promise a solution by allocating separate “experts” (sub‑networks) to different parts of the input space, allowing the model to scale to billions of parameters while keeping inference cost low. During pre‑training, a routing network learns which experts to activate for each token. However, this routing is learned in a monolingual‑biased environment, leading to two intertwined challenges:
- Heterogeneous routing patterns: Middle layers develop language‑specific expert clusters, but standard fine‑tuning treats the MoE as a single monolithic block, ignoring these patterns.
- Performance gaps across languages: The divergence in routing decisions correlates strongly with per‑language task performance, especially for low‑resource languages.
Existing fine‑tuning strategies—plain supervised fine‑tuning (SFT), parameter‑efficient adapters, or even recent routing‑steering techniques—do not explicitly address the misalignment between English‑trained routing and target‑language routing. As a result, they either waste the expert capacity or require costly language‑specific retraining.
What the Researchers Propose
The authors present RA‑MoE (Routing‑Aligned MoE Fine‑Tuning), a systematic framework that leverages the intrinsic routing structure of MoE models to improve multilingual downstream performance. The approach consists of three stages:
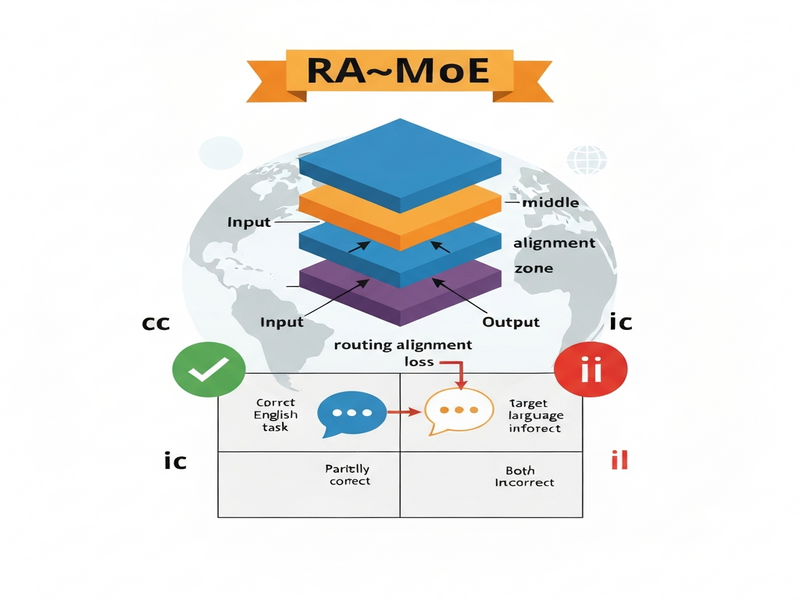
- Four‑Way Taxonomy Construction: Parallel examples (English and target language) are categorized into four types based on correctness:
- cc – correct in both English and target language.
- ci – correct in English, incorrect in target language.
- ic – incorrect in English, correct in target language.
- ii – incorrect in both.
- Middle‑Layer Expert Identification: By probing the routing logits of the pre‑trained model, the method isolates the subset of experts that consistently fire for correctly answered English examples (the “English task‑expert” set).
- Routing Alignment Loss: During fine‑tuning, a supplemental loss term nudges the routing distribution of ci examples toward the identified English task‑expert pattern, effectively teaching the model to reuse the same expert pathways for the target language.
Crucially, the framework does not alter the underlying model weights beyond the standard supervised objective; it only shapes the routing decisions, preserving the efficiency benefits of MoE inference.
How It Works in Practice
The RA‑MoE workflow can be visualized as a pipeline that sits between data preparation and the final fine‑tuning loop:
Step‑by‑Step Interaction
- Data Pairing: For each downstream task, a bilingual dataset is assembled (e.g., English question‑answer pairs and their translations).
- Taxonomy Assignment: The model runs inference on both language versions. Based on correctness, each pair is labeled as cc, ci, ic, or ii.
- Expert Extraction: The routing logits from the middle layers of the pre‑trained MoE are collected for all cc examples. Statistical analysis (e.g., top‑k frequency) yields the expert IDs that dominate English correct predictions.
- Alignment Fine‑Tuning: The standard supervised loss (cross‑entropy) is combined with a routing alignment loss. For ci examples, the loss penalizes divergence between the current routing distribution and the expert set identified in step 3.
- Inference: After training, the model retains the same inference speed because routing decisions are still made by the original router; only the probability mass has been reshaped.
What sets RA‑MoE apart from prior methods is its explicit focus on the “alignment zone”—the middle layers where language‑agnostic routing patterns emerge. By targeting this zone, the approach avoids the instability of full‑model routing rewiring while still delivering language‑specific gains.
Evaluation & Results
The authors validated RA‑MoE across three state‑of‑the‑art MoE models (e.g., Switch‑Transformer, GLaM, and a proprietary 64‑expert variant), three downstream tasks (question answering, sentiment classification, and named‑entity recognition), and six target languages spanning high‑resource (German, French) and low‑resource (Swahili, Nepali) families.
Key Experimental Findings
- Consistent Gains: RA‑MoE outperformed vanilla SFT by 2.3–5.7 percentage points in accuracy/F1, with larger improvements observed for low‑resource languages.
- Baseline Comparison: Against strong routing‑steering baselines and the recent RISE method, RA‑MoE delivered an average uplift of 1.8 points, confirming that alignment loss adds value beyond generic steering.
- Predictive Power of ci Proportion: The share of ci examples in a language‑task pair correlated strongly (r = 0.78) with the magnitude of RA‑MoE’s benefit, offering a practical heuristic for when to apply the method.
- Efficiency Retention: Inference latency remained within 3 % of the original MoE model, demonstrating that the alignment loss does not introduce extra computational overhead.
These results collectively demonstrate that RA‑MoE can systematically close the performance gap between English and non‑English tasks while preserving the scalability advantages of MoE architectures.
Why This Matters for AI Systems and Agents
For practitioners building multilingual AI agents—whether for global customer support bots, cross‑border content moderation, or multilingual knowledge retrieval—the ability to fine‑tune a single MoE model efficiently is a game changer. RA‑MoE offers several practical benefits:
- Reduced Engineering Overhead: Teams no longer need to maintain separate language‑specific expert pools or train massive monolingual models from scratch.
- Predictable ROI: The ci proportion metric lets product managers estimate the expected performance lift before committing compute resources.
- Scalable Deployment: Because the method does not alter the model’s inference graph, existing serving stacks (including those built on the UBOS platform overview) can adopt RA‑MoE without architectural changes.
- Enhanced Agent Consistency: Aligning routing across languages ensures that the same expert knowledge is applied, leading to more uniform behavior in multilingual conversational agents.
Enterprises looking to integrate multilingual capabilities into their AI pipelines can therefore achieve higher accuracy with lower cost, a critical factor for scaling AI across global markets.
What Comes Next
While RA‑MoE marks a significant step forward, several open challenges remain:
- Dynamic Language Shifts: Current taxonomy construction assumes static language pairs. Future work could explore online detection of ci patterns as new domains emerge.
- Expert Granularity: Investigating whether finer‑grained routing (e.g., token‑level vs. layer‑level) yields additional gains for code‑switching scenarios.
- Cross‑Modal Extensions: Applying routing alignment to multimodal MoE models (vision‑language) could unlock multilingual capabilities in image captioning or video analysis.
Practitioners interested in experimenting with RA‑MoE can start by integrating the method into their existing fine‑tuning pipelines and using the Workflow automation studio to orchestrate the taxonomy and alignment steps. For organizations seeking a turnkey solution, the Enterprise AI platform by UBOS already supports custom routing loss modules, making it straightforward to prototype RA‑MoE on proprietary datasets.
Finally, the broader research community is encouraged to release benchmark suites that report the ci proportion alongside traditional metrics, fostering a more transparent evaluation of multilingual fine‑tuning techniques.
References
Routing-Aligned Fine-Tuning paper