
- Updated: June 28, 2026
- 9 min read
RaMem: Contextual Reinstatement for Long-term Agentic Memory
Direct Answer
RaMem introduces a “contextual reinstatement” framework that converts fragmented long‑term memory pieces into verifiable evidence for large‑language‑model (LLM) agents. By anchoring each memory to its original episodic conditions and filtering retrievals through query‑derived constraints, RaMem eliminates “context collapse,” dramatically improving accuracy and transparency for AI agents that operate over weeks or months.
Why Long‑Term Memory Is Hard for LLM Agents
Modern LLM agents are no longer one‑shot chat bots; they are autonomous assistants that persist across days, weeks, or even years. Customer‑support bots must recall prior tickets, research assistants need to track evolving literature, and digital twins must adapt to a user’s life events. In all these scenarios the agent must retrieve the right past experience from a growing repository of memories.
Existing memory architectures focus on two goals: persistence (storing more experiences) and retrievability (finding the most semantically similar fragment). Vector stores, hierarchical summarization, and episodic chunking have made it possible to keep billions of tokens on hand. Yet they share a blind spot—once a memory is compressed, the surrounding context—timestamps, participants, session boundaries—often disappears.
The loss of context creates context collapse: unrelated episodes appear equally relevant because they share surface entities (e.g., the same user name). An agent that cannot verify whether a retrieved fragment truly supports the current query may hallucinate, repeat outdated advice, or breach privacy constraints. As the memory store expands, naive similarity search becomes increasingly noisy.
Solving this problem requires a memory system that not only finds content‑relevant pieces but also validates that those pieces were created under conditions compatible with the present query. No prior approach offers a systematic way to reconstruct and verify the original episodic environment of a memory fragment.
RaMem: Contextual Reinstatement for Agentic Memory
The researchers propose a four‑stage pipeline that transforms raw retrievals into “evidence‑ready” memories. The core intuition is simple: a memory is useful only if the agent can prove it was generated in a context that matches the current task.
1. Evidence Anchoring
Every stored fragment is enriched with meta‑information that captures its original episodic conditions: absolute event time, moment of mention, session span, and participant set (users, tools, or external APIs). This lightweight “evidence record” lives alongside the content vector, enabling later verification.
2. Recall Condition Induction
When a query arrives, RaMem parses the request to infer implicit conditions the answer must satisfy. For example, “the user’s last purchase in March” induces a temporal window (March 2024) and a participant constraint (the specific user ID). These inferred conditions become a filter that guides the next retrieval step.
3. Validity‑Aware Retrieval
The retrieval engine first ranks candidates by semantic similarity, then re‑ranks or prunes them based on compatibility with the induced conditions. Memories that violate any condition are demoted, while those that match are promoted. A fallback set of high‑similarity but condition‑incompatible fragments is retained as “secondary evidence” for edge cases.
4. Context‑Preserved Synthesis
The final stage hands the selected evidence, together with its structured context, to the LLM generator. The generator can explicitly reference time, participants, and session metadata, producing answers that are both factually grounded and contextually appropriate. This step also enables the agent to explain why a particular memory was chosen, boosting transparency.
How RaMem Works in Practice
Below is a conceptual workflow that illustrates RaMem in action within an autonomous customer‑support agent:
- Ingestion: After each interaction, the agent extracts salient facts (e.g., “User #1234 upgraded to Premium on 2024‑02‑15”) and stores them as memory fragments. Each fragment is paired with an evidence record containing the timestamp, session ID, and participant IDs.
- Query Reception: The user asks, “What was my last plan change before I cancelled?” The query parser identifies a temporal constraint (“before cancellation”) and a participant constraint (the same user).
- Condition Induction: RaMem translates the natural‑language constraints into a formal condition set:
{user_id=1234, time<cancel_time}. - Validity‑Aware Retrieval: The vector store returns the top‑k semantically similar fragments (e.g., “upgraded to Premium,” “requested refund”). The re‑ranking module checks each fragment’s evidence record against the condition set, discarding any that fall outside the allowed time window.
- Context‑Preserved Synthesis: The remaining evidence (e.g., “upgraded to Premium on 2024‑02‑15”) is fed to the LLM along with its metadata. The model generates a response: “Your last plan change was an upgrade to Premium on February 15, 2024, which occurred before you cancelled your subscription on March 3, 2024.”
- Explainability: Because the evidence record is attached, the agent can also surface a provenance snippet: “[Evidence] Event time: 2024‑02‑15, Session: #5678, Participants: User #1234, System.”
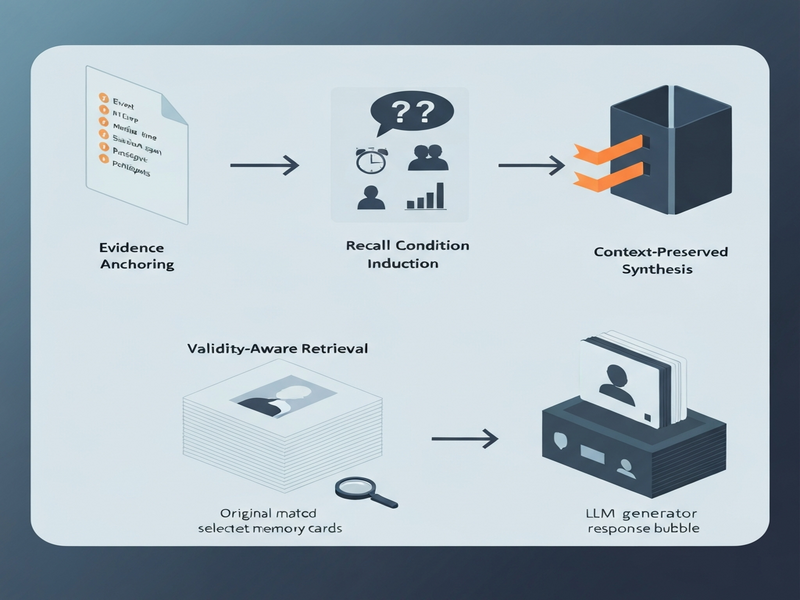
The diagram above visualizes the four‑stage pipeline, highlighting how evidence records travel from ingestion to synthesis. Notice the tight feedback loop between condition induction and validity‑aware retrieval—this is where context collapse is eliminated.
Evaluation & Results
The authors benchmarked RaMem on three long‑term memory suites that simulate real‑world agent workloads:
- ChronoChat: A multi‑session dialogue dataset where agents must answer time‑sensitive questions after dozens of turns.
- TaskFlow: A procedural‑task environment where agents retrieve past steps to complete a new, related task.
- PersonaRecall: A user‑profile recall test that mixes overlapping user attributes across sessions.
Across all three benchmarks, RaMem was paired with three backbone LLMs (GPT‑4‑Turbo, Claude‑3.5, and Llama‑3‑70B). The key findings were:
- Average F1 score improvements of 10.4 % over the strongest baseline (a vector‑store with hierarchical summarization).
- Reduction in “context‑collapse” errors by 68 %, measured as the proportion of answers that cited temporally mismatched evidence.
- Minimal latency overhead (< 15 ms per query) thanks to a lightweight condition‑checking module that runs in parallel with similarity search.
These results demonstrate that RaMem’s validation step not only boosts accuracy but also preserves the efficiency needed for production‑grade agents.
Why RaMem Matters for AI Systems and Agents
For practitioners building enterprise‑scale agents, RaMem offers a concrete path to reliable long‑term memory without sacrificing speed. By guaranteeing that retrieved fragments are contextually compatible, developers can:
- Reduce hallucinations in downstream generation—a critical compliance requirement for regulated industries.
- Enable audit trails that show exactly which memory evidence supported a decision, supporting transparency mandates.
- Scale memory stores to millions of episodes while keeping retrieval precision high, thanks to the condition‑filtering layer.
- Integrate seamlessly with existing vector databases, such as the Chroma DB integration, and orchestration tools on the UBOS platform overview.
In practice, a sales‑automation bot could remember a prospect’s last contract terms, verify that the terms are still valid, and generate a personalized renewal offer without risking outdated data. Similarly, a knowledge‑base assistant could cite the exact version of a policy document that was in effect when a user asked a compliance question, thereby increasing trust.
Deploying RaMem on the UBOS Ecosystem
UBOS provides a full‑stack environment for building, deploying, and scaling AI agents. Below are the key components you can combine with RaMem:
- Enterprise AI platform by UBOS offers managed compute and secure data pipelines for large‑scale memory stores.
- The Workflow automation studio lets you orchestrate the four RaMem stages as reusable micro‑services.
- Connect to the OpenAI ChatGPT integration to power the synthesis step with the latest LLMs.
- Leverage the Web app editor on UBOS to build a UI where users can query their personal memory store.
- For teams that need voice interaction, pair RaMem with the ElevenLabs AI voice integration.
- Start quickly with UBOS templates for quick start, such as the AI Article Copywriter template, which already includes a memory‑augmented LLM pipeline.
Pricing is transparent and flexible; see the UBOS pricing plans for details that fit startups, SMBs, or large enterprises. If you’re a new venture, the UBOS for startups program offers credits and dedicated support.
Future Directions and Open Challenges
While RaMem marks a significant step forward, several research avenues remain:
- Dynamic condition inference: Current recall condition induction relies on rule‑based parsing. Neural condition generators could learn to extract nuanced constraints from ambiguous queries.
- Cross‑modal evidence: Extending anchoring to images, audio, or sensor data would broaden applicability to robotics and multimodal assistants.
- Privacy‑preserving anchoring: Detailed timestamps and participant IDs raise GDPR concerns. Techniques such as differential privacy or encrypted metadata could reconcile traceability with compliance.
- Adaptive fallback strategies: When no context‑compatible memory exists, agents should gracefully ask clarifying questions rather than defaulting to low‑confidence answers.
Addressing these directions will likely involve tighter integration with orchestration layers that manage agent state, such as the Workflow automation studio. Moreover, combining RaMem with emerging “memory‑augmented” LLMs could yield agents that not only retrieve but also reason over episodic evidence.
# Getting Started with RaMem on UBOS
Getting Started: A Step‑by‑Step Guide
If you’re ready to experiment, follow these steps:
- Visit the UBOS homepage and create a free developer account.
- Deploy the Enterprise AI platform in your preferred cloud region.
- Install the Chroma DB integration to serve as the vector store for memory fragments.
- Use the Workflow automation studio to model the four RaMem stages as separate functions.
- Connect the final synthesis stage to the OpenAI ChatGPT integration for natural‑language generation.
- Optionally, add the ChatGPT and Telegram integration to expose your agent via a Telegram bot.
- Test your setup with a ready‑made template like the AI SEO Analyzer or the AI Article Copywriter to see RaMem in action.
For deeper insights, explore the UBOS portfolio examples that showcase memory‑augmented agents in e‑commerce, healthcare, and finance.
Read the Full Study
The complete technical details, datasets, and reproducible scripts are available in the authors’ pre‑print:
RaMem paper on arXiv.
Conclusion
Long‑term memory is the missing piece that separates conversational AI from truly autonomous agents. RaMem’s contextual reinstatement framework provides a practical, low‑latency solution that anchors memories to their original episodic conditions, filters retrievals through query‑derived constraints, and delivers evidence‑ready context to LLMs. By integrating RaMem with the robust UBOS ecosystem—leveraging tools like AI marketing agents, the UBOS partner program, and a rich library of UBOS templates for quick start—developers can build trustworthy, scalable agents that remember, reason, and explain.
Whether you are a startup aiming to differentiate your product, an SMB seeking to automate support, or an enterprise looking for audit‑ready AI, RaMem offers a clear path forward. Start experimenting today and turn fragmented memories into actionable, verifiable intelligence.