
- Updated: June 27, 2026
- 7 min read
PRIME: Evaluating Prompt Resolution Under Incompatible Instructions in LLMs
Direct Answer
The paper introduces PRIME (Prompt Resolution under Incompatible Meta‑Instructions Evaluation), a systematic framework for probing how large language models (LLMs) behave when faced with contradictory prompts. It matters because current instruction‑following benchmarks treat meta‑instructions in isolation, leaving a blind spot in our understanding of model reliability when real‑world users issue overlapping or opposing commands.
Background: Why This Problem Is Hard
LLMs are increasingly deployed as autonomous agents, customer‑support bots, and workflow orchestrators. In production, these systems rarely receive a single, clean instruction. Instead, they encounter conflicting meta‑instructions—for example, a request to keep a response concise while simultaneously demanding a detailed step‑by‑step explanation, or a demand for a JSON payload that also requires a narrative summary. Existing instruction‑following benchmarks, such as MMLU‑Instr or AlpacaEval, evaluate each constraint separately, assuming that a model can simply toggle between modes. This assumption breaks down when constraints intersect, leading to ambiguous outputs, hallucinations, or outright failure to comply.
Two technical bottlenecks amplify the difficulty:
- Signal dilution: LLMs are trained on massive corpora where contradictory directives are rare, so the model’s internal attention mechanisms lack a robust signal for prioritizing one instruction over another.
- Evaluation opacity: Without a unified test harness that deliberately creates calibrated conflicts, researchers cannot reliably measure whether a model is “choosing” the right instruction, ignoring one, or attempting a compromise that satisfies none.
Consequently, developers lack actionable diagnostics to improve conflict handling, and enterprises risk deploying agents that behave unpredictably under realistic user interactions.
What the Researchers Propose
The authors present PRIME, a three‑layered methodology designed to surface and categorize LLM behavior under deliberately engineered instruction conflicts:
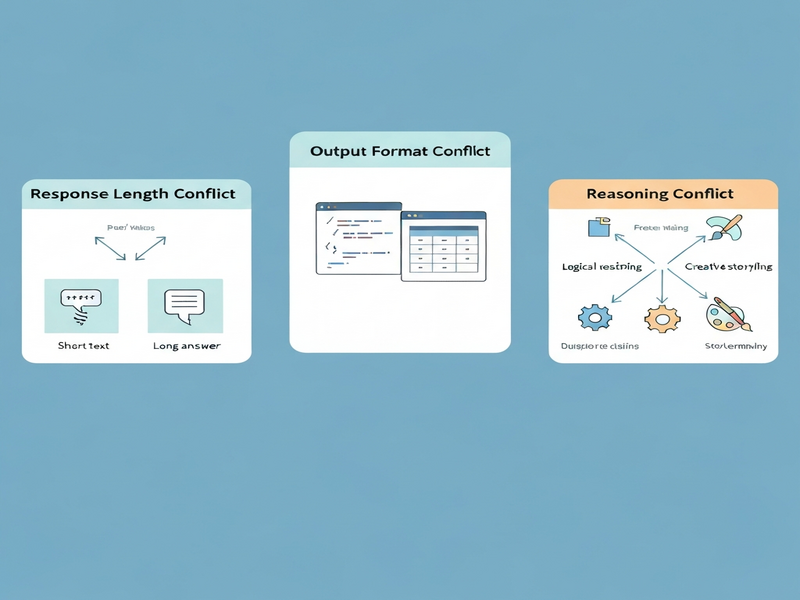
- Conflict Generation Engine: Constructs prompts that embed incompatible meta‑instructions across three orthogonal dimensions—response length (short vs. long), output format (plain text vs. structured JSON), and reasoning style (direct answer vs. chain‑of‑thought). Each dimension can be toggled independently, yielding a combinatorial set of conflict scenarios.
- Deterministic Behavioral Taxonomy: Defines a closed set of response categories (e.g., Prioritize‑Length, Prioritize‑Format, Hybrid‑Compromise, Failure‑to‑Resolve) that can be automatically assigned via rule‑based parsing of the model’s output.
- Evaluation Protocol: Applies the conflict engine to a suite of instruction‑tuned open‑weight LLMs under two distributional regimes—balanced (equal representation of each conflict type) and naturally distributed (conflicts sampled according to real‑world frequency estimates).
By separating conflict creation from taxonomy, PRIME enables reproducible, fine‑grained analysis that goes beyond “does the model follow the instruction?” to “how does the model resolve competing directives?”
How It Works in Practice
Implementing PRIME follows a straightforward workflow that can be integrated into existing evaluation pipelines:
- Prompt Template Library: Researchers author a small set of base prompts (e.g., “Summarize the article”) and annotate them with placeholders for meta‑instructions.
- Conflict Injector: An automated script substitutes placeholders with contradictory directives drawn from the three dimensions. For instance, a single prompt may become: “Provide a brief summary in JSON while also explaining each step of your reasoning.”
- Model Invocation: The conflicted prompts are fed to each target LLM via its API or local inference endpoint. No model‑specific tuning is required.
- Response Parser: The output is examined against the deterministic taxonomy. Simple regex patterns detect format compliance, length thresholds, and presence of reasoning markers.
- Aggregated Reporting: Results are visualized as heatmaps that map conflict types to taxonomy outcomes, enabling quick identification of systematic weaknesses.
What sets PRIME apart is its calibrated conflict generation. Rather than relying on ad‑hoc contradictory prompts, the framework guarantees that each conflict is comparable across models, scales, and evaluation settings. This uniformity makes cross‑model benchmarking both fair and insightful.
Evaluation & Results
The authors applied PRIME to five open‑weight, instruction‑tuned LLMs (including variants of LLaMA‑2 and Mistral) under two experimental regimes:
- Balanced Setting: Each of the nine possible conflict combinations (3 dimensions × 3 pairwise conflicts) was presented an equal number of times.
- Natural Distribution Setting: Conflict instances were sampled according to a corpus‑derived estimate of how often users issue contradictory instructions in real‑world chat logs.
Key observations emerged:
- Conflict Type Dominates Scale: Across all models, the nature of the conflict (e.g., length vs. format) had a larger impact on taxonomy outcomes than the model’s parameter count. Smaller models sometimes outperformed larger ones on format‑centric conflicts.
- Systematic Failure Modes: Models frequently defaulted to the first instruction in the prompt, leading to a “Prioritize‑Length” pattern when length and format conflicted. In reasoning‑vs‑format conflicts, many models produced a hybrid output that partially satisfied both but violated strict format constraints.
- Balanced vs. Natural Regimes: In the natural distribution, models appeared to “learn” the more common conflict patterns, reducing failure rates for those cases but worsening performance on rare conflict types.
- Taxonomy Coverage: No model achieved a pure “Hybrid‑Compromise” outcome across all conflict categories, indicating a universal gap in conflict‑aware instruction handling.
These findings underscore that current instruction‑tuning pipelines do not endow LLMs with a robust conflict‑resolution strategy; instead, they inherit a brittle, order‑dependent bias.
Why This Matters for AI Systems and Agents
For practitioners building AI‑driven agents—whether for customer support, workflow automation, or autonomous decision‑making—the PRIME insights translate into concrete design considerations:
- Prompt Engineering Discipline: Knowing that LLMs tend to honor the first meta‑instruction, developers should explicitly order constraints or embed a “conflict‑resolution policy” within the prompt (e.g., “If you cannot satisfy both, prioritize format”).
- Orchestration Layer Enhancements: Agent frameworks can pre‑process user requests to detect potential conflicts and either re‑phrase them or route them to a conflict‑resolution module before invoking the LLM.
- Evaluation Integration: Incorporating PRIME‑style tests into CI pipelines ensures that new model releases maintain or improve conflict handling, reducing the risk of silent failures in production.
- Product Differentiation: Companies that surface conflict‑aware behavior (e.g., “I’m unable to give a concise JSON response; would you like a longer text version instead?”) can build trust with end‑users.
These practical steps align with broader trends toward Enterprise AI platform by UBOS, where robust agent orchestration and transparent failure modes are core value propositions.
What Comes Next
While PRIME establishes a solid baseline, several avenues remain open for advancing conflict‑aware LLM research:
- Dynamic Conflict Resolution Training: Fine‑tune models on datasets that explicitly label conflict priorities, enabling the model to learn a policy rather than rely on prompt order.
- Multi‑Objective Optimization: Extend the taxonomy to capture trade‑offs between competing objectives (e.g., accuracy vs. brevity) and explore reinforcement learning from human feedback (RLHF) that rewards balanced compromises.
- User‑Centric Conflict Detection: Build front‑end tools that flag contradictory user inputs in real time, offering suggestions before the request reaches the model.
- Benchmark Expansion: Incorporate domain‑specific conflicts (e.g., legal compliance vs. user privacy) to test models in regulated environments.
- Open‑Source Tooling: Release a plug‑and‑play PRIME library that integrates with popular inference stacks (e.g., Ollama) to democratize conflict testing.
Addressing these challenges will move the field from “does the model follow a single instruction?” to “how intelligently does the model negotiate multiple, possibly opposing, demands.” For organizations seeking to embed such capabilities, exploring AI marketing agents that already incorporate conflict‑aware prompting can serve as a practical starting point.
References
For the full technical details, see the original PRIME paper on arXiv.
Andrii Bidochko
CTO UBOS
Andrii Bidochko is an AI entrepreneur and researcher focused on AI agents, reinforcement learning, and autonomous systems. He writes about the technologies shaping the future of machine intelligence, from frontier models and agent architectures to real-world AI applications.