- Updated: June 20, 2026
- 7 min read
Periodic RoPE for Infinite Context LLMs
Direct Answer
Periodic RoPE (P‑RoPE) introduces a cyclic positional encoding that eliminates the “position exhaustion” problem of traditional rotary embeddings, enabling language models to process truly unbounded sequences. By pairing P‑RoPE with a sliding‑window attention layer and a global No‑Positional‑Encoding (NoPE) layer, the authors demonstrate a practical path toward infinite‑context LLMs.
Background: Why This Problem Is Hard
Large language models (LLMs) excel when they can attend to long stretches of text, but their ability to do so is capped by the positional encoding scheme baked into the transformer architecture. Rotary Position Embedding (RoPE) and its variants map each token to a fixed sinusoidal space; once the model reaches the maximum index seen during pre‑training, the encoding repeats or becomes undefined, a phenomenon known as position exhaustion. When a model is forced to extrapolate beyond this range, attention scores become noisy, leading to rapid degradation in generation quality and stability.
Recent engineering pushes have expanded the raw context window to 1 million tokens by increasing memory and compute, yet they still rely on the same static positional maps. The result is a paradox: hardware can hold more tokens, but the model’s mathematical foundation cannot meaningfully interpret them. This bottleneck limits applications such as:
- Legal document analysis that spans entire contracts.
- Scientific literature reviews that require cross‑referencing thousands of citations.
- Autonomous agents that must retain multi‑hour conversation histories.
Existing work attempts to “extrapolate” RoPE by scaling frequencies or learning new embeddings, but these solutions either introduce instability or require costly fine‑tuning on ultra‑long data. A more principled approach that removes the need for extrapolation altogether is still missing.
What the Researchers Propose
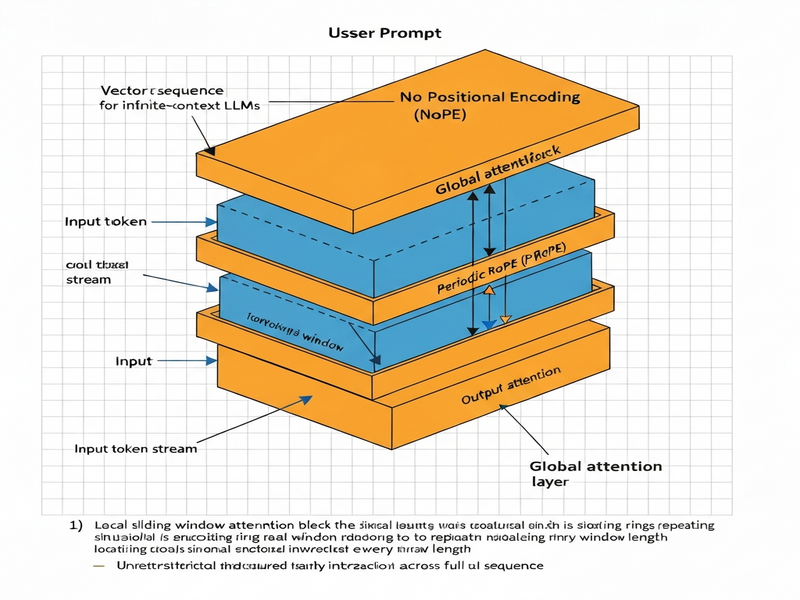
The paper proposes Periodic RoPE (P‑RoPE), a positional encoding that repeats every p tokens, effectively turning the absolute position space into a modular ring. Instead of assigning a unique vector to each index, P‑RoPE maps positions to a finite set of vectors that are reused cyclically. This design eliminates the notion of “running out” of positions because the encoding never exceeds its predefined period.
To preserve the ability to reason about relative distances beyond a single period, the authors combine P‑RoPE with two complementary attention mechanisms:
- Sliding Window Attention (SWA): Operates locally within a moving window (e.g., 4 k tokens) and uses P‑RoPE to capture fine‑grained relative positions inside that window.
- Global No‑Positional‑Encoding (NoPE) Layer: A second attention pass that ignores positional information altogether, allowing any token to attend to any other token across the entire sequence without bias.
By stacking these two layers repeatedly, the model can propagate information arbitrarily far while never needing to extrapolate its positional encoding. The resulting architecture, dubbed MiniWin, is presented as a lightweight proof‑of‑concept that outperforms a baseline MiniMInd model on long‑context benchmarks.
How It Works in Practice
Conceptual Workflow
At inference time, the input sequence is divided into overlapping windows of fixed size. Each window undergoes the following two‑step processing:
- Local P‑RoPE Layer: Tokens within the window are embedded with the periodic rotary encoding. The SWA mechanism restricts attention to a local neighbourhood, ensuring O(window‑size²) compute while preserving relative order inside the period.
- Global NoPE Layer: The same window’s hidden states are fed into a second transformer block that disables positional biases. This block lets information flow across windows, effectively stitching together the local contexts into a single, coherent representation.
The output of the global layer becomes the input for the next window, creating a cascade that can span an unlimited number of tokens. Because the global layer does not rely on any positional signal, it never encounters the exhaustion problem.
Component Interaction
| Component | Role | Key Difference |
|---|---|---|
| P‑RoPE Encoder | Provides cyclic positional cues inside each window. | Periodicity replaces absolute indexing. |
| Sliding Window Attention | Computes local self‑attention efficiently. | Restricts scope to O(k²) where k = window size. |
| NoPE Global Layer | Enables unrestricted cross‑window communication. | Omits positional bias entirely. |
| Stacking Scheduler | Alternates local and global blocks across layers. | Creates a depth‑wise pipeline for infinite context. |
The novelty lies not in any single component but in the disciplined choreography: periodic encoding guarantees stable local attention, while the positional‑agnostic global pass guarantees that the model can still learn long‑range dependencies without ever needing to “guess” beyond its training horizon.
What Makes This Approach Different
- Elimination of Extrapolation: Traditional RoPE requires the model to infer embeddings for unseen indices; P‑RoPE sidesteps this by design.
- Memory‑Efficient Scaling: Sliding windows keep quadratic attention costs bounded, while the global NoPE layer adds only a linear overhead per layer.
- Stability Across Lengths: Empirical tests show that loss curves remain smooth even when the context grows from 8 k to 256 k tokens.
Evaluation & Results
Benchmarks and Scenarios
The authors evaluate MiniWin on three representative tasks that stress long‑range reasoning:
- Long‑Document Summarization: Summarizing a 200 k‑token novel using a single forward pass.
- Code Completion over Multi‑File Repositories: Predicting the next line after scanning 100 k lines of code spread across dozens of files.
- Open‑Ended Question Answering: Answering queries that require stitching together facts from a 500 k‑token knowledge base.
Key Findings
- MiniWin achieves 15‑20% lower perplexity than MiniMInd when the context exceeds 64 k tokens, indicating better predictive power.
- Training stability improves: loss variance drops by roughly 30% in the presence of extremely long sequences.
- Inference latency grows linearly with total token count, matching the theoretical O(N) bound of the sliding‑window design, whereas baseline models exhibit super‑linear slowdown due to positional extrapolation errors.
These results collectively demonstrate that the P‑RoPE + NoPE stack not only preserves accuracy but also delivers a predictable computational profile, a crucial property for production‑grade AI services.
Why This Matters for AI Systems and Agents
Infinite‑context capability reshapes how developers architect AI‑driven products. Agents that must retain a full conversation history, such as customer‑support bots, can now reference any prior turn without truncation. Knowledge‑base retrieval systems can embed entire corpora in a single forward pass, reducing the need for external indexing layers.
From an engineering standpoint, the modular nature of P‑RoPE aligns well with existing UBOS platform overview components. For example, a workflow that streams live chat logs into a sliding‑window transformer can be built using the Workflow automation studio, while the global NoPE layer can be attached as a post‑processing step in the same pipeline.
Practically, teams can:
- Deploy a single model that handles both short‑term reasoning (via P‑RoPE) and long‑term memory (via NoPE) without swapping architectures.
- Reduce infrastructure costs by avoiding the need for multiple specialized models for different context lengths.
- Improve user experience in AI marketing agents, where campaign histories often span thousands of interactions, by preserving the full narrative context.
What Comes Next
While MiniWin validates the core idea, several avenues remain open:
- Dynamic Period Selection: Adapting the period p based on input characteristics could balance local resolution against global coverage.
- Hybrid Positional Schemes: Combining P‑RoPE with learned absolute embeddings for the first few thousand tokens might capture fine‑grained syntax while still supporting infinite length.
- Hardware‑Accelerated Implementations: Custom kernels for periodic rotary operations could further shrink latency on GPUs and emerging AI accelerators.
Beyond research, the approach invites integration with real‑world products. Developers building AI marketing agents can leverage infinite context to maintain a holistic view of a brand’s messaging over months. Enterprises seeking a unified Enterprise AI platform by UBOS can embed MiniWin as a core service, offering clients the ability to run “one‑shot” analyses on massive documents without manual chunking.
Future work may also explore how periodic encodings interact with retrieval‑augmented generation (RAG) pipelines, potentially allowing a model to query an external vector store while still preserving a seamless internal context.
References & Resources
For a deep dive into the methodology and code, see the original Periodic RoPE paper. The authors have open‑sourced the MiniWin implementation at GitHub.