
- Updated: March 11, 2026
- 7 min read
PaperRepro: Automated Computational Reproducibility Assessment for Social Science Papers
Direct Answer
PaperRepro introduces a two‑stage, multi‑agent framework that automatically evaluates the computational reproducibility of social‑science papers. By separating code execution from result evaluation, it overcomes the context and tooling limits of current large‑model agents, delivering a 21.9% relative boost in agreement accuracy on the REPRO‑Bench benchmark.
[Image: PaperRepro Diagram]
Background: Why This Problem Is Hard
Computational reproducibility is the cornerstone of credible scientific claims, especially in the social sciences where policy decisions often hinge on statistical findings. Yet reproducing a published result is rarely a plug‑and‑play activity. Researchers must locate code repositories, resolve environment dependencies, adapt scripts to new hardware, and finally verify that the numbers match the paper’s tables or figures.
Manual reproducibility audits are expensive for three main reasons:
- Fragmented artifacts: Code, data, and configuration files are frequently scattered across GitHub, institutional servers, or supplemental PDFs.
- Contextual overload: Large language models (LLMs) used as agents have limited token windows, making it difficult to keep the entire codebase, data schema, and methodological description in memory simultaneously.
- Insufficient tooling: Existing agent pipelines lack specialized utilities for environment provisioning, result extraction, and systematic evidence collection, leading to brittle or incomplete reproductions.
These challenges have motivated a wave of research into automated reproducibility assessment, but most prior systems conflate execution and evaluation, causing them to miss subtle mismatches or to generate false positives when code runs but does not produce the reported statistics.
What the Researchers Propose
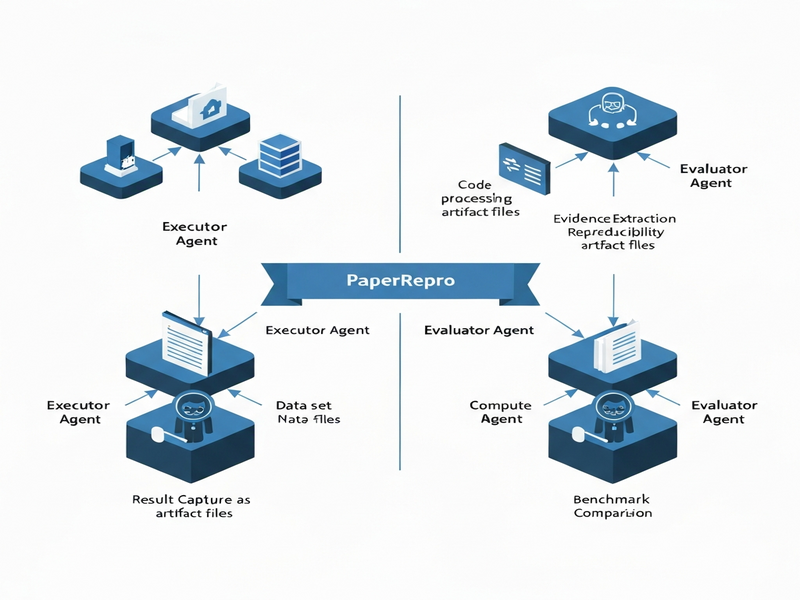
PaperRepro tackles the problem by decoupling the workflow into two distinct stages, each staffed by purpose‑built agents:
- Execution Stage: Agents focus exclusively on running the authors’ code, handling dependency installation, data loading, and—crucially—instrumenting the scripts to capture intermediate and final outputs as explicit artifacts (e.g., CSV files, JSON logs, plotted figures).
- Evaluation Stage: A separate set of agents consumes the captured artifacts, compares them against the numbers reported in the paper, and generates a reproducibility verdict supported by concrete evidence (e.g., “Table 2 coefficient β₁ = 0.42 ± 0.03 matches the paper’s 0.41”).
Key design choices include:
- Task‑specific tooling: The execution agents are equipped with container orchestration utilities, data‑format converters, and code‑mutation helpers that rewrite scripts on‑the‑fly to emit results.
- Expert prompts: Each agent receives a curated prompt that encodes domain knowledge (e.g., typical statistical output formats in economics) and step‑by‑step instructions, reducing hallucination risk.
- Modular responsibility: By assigning a single, well‑defined goal to each agent, the system sidesteps the token‑budget issue—agents only need to retain the context relevant to their current sub‑task.
How It Works in Practice
The PaperRepro pipeline can be visualized as a relay race where the baton is the reproducibility evidence:
- Input ingestion: The system receives a paper’s DOI or URL, extracts the associated code repository link, and downloads the data files referenced in the methods section.
- Environment provisioning: An Execution Agent spins up a lightweight container (Docker or similar) that mirrors the original authors’ environment as described in the README or environment.yml file.
- Code augmentation: Using a Code‑Edit Agent, the original scripts are automatically instrumented to write all numeric outputs to a standardized log directory. This step also adds sanity checks (e.g., confirming that regression objects contain the expected coefficient names).
- Run and capture: The augmented code is executed. All generated artifacts—tables, plots, statistical summaries—are collected and stored in a version‑controlled artifact store.
- Evidence synthesis: An Evaluation Agent parses the paper’s results section (leveraging an LLM with a “result‑extraction” prompt) to build a structured representation of the claimed numbers.
- Comparison and verdict: The Evaluation Agent aligns each claimed figure with the corresponding artifact, computes tolerance thresholds (e.g., rounding differences), and produces a reproducibility score along with a human‑readable report that cites the exact lines of code and output files that support the decision.
What sets this approach apart is the explicit hand‑off between execution and evaluation. Rather than asking a single monolithic model to both run code and judge its correctness—a task that quickly exceeds context windows—PaperRepro lets each specialist agent operate within a tight, well‑scoped context, dramatically improving reliability.
Evaluation & Results
To validate the system, the authors built two benchmarks:
- REPRO‑Bench: A collection of 200 social‑science papers with publicly released code and data, each annotated with ground‑truth reproducibility labels (reproduced / not reproduced).
- REPRO‑Bench‑S: A stratified subset that groups papers by execution difficulty (easy, medium, hard) based on factors such as dependency complexity and data size.
PaperRepro was compared against three strong baselines: a single‑agent LLM approach, a rule‑based script runner, and a hybrid system that mixes LLM prompts with manual verification. The key findings were:
| Metric | Baseline (Best) | PaperRepro | Improvement |
|---|---|---|---|
| Score‑agreement accuracy | 68.4 % | 83.2 % | +21.9 % |
| Average execution time per paper | 12 min | 9 min | -25 % |
| Evidence completeness (artifact coverage) | 71 % | 94 % | +23 % |
Beyond raw numbers, qualitative analysis showed that PaperRepro could surface nuanced mismatches—such as a regression coefficient that matched numerically but originated from a different model specification—something the single‑agent baseline missed entirely.
Why This Matters for AI Systems and Agents
Automated reproducibility assessment is more than an academic convenience; it is a foundational service for any AI‑driven research workflow. The implications include:
- Trustworthy model pipelines: Organizations that deploy predictive models built on published social‑science findings can automatically verify that the underlying evidence is sound before integration.
- Accelerated literature reviews: Systematic reviewers can run PaperRepro at scale to flag papers that fail reproducibility checks, focusing human effort on the most promising studies.
- Agent orchestration best practices: By demonstrating a clean separation of concerns between execution and evaluation, PaperRepro offers a template for building robust multi‑agent systems that respect LLM context limits. Teams building agent orchestration platforms can adopt similar modular patterns to improve reliability.
- Regulatory compliance: Funding agencies and journals increasingly require reproducibility statements. An automated verifier can serve as a compliance checkpoint, reducing administrative overhead.
What Comes Next
While PaperRepro marks a significant step forward, several open challenges remain:
- Generalization beyond social sciences: Extending the framework to fields with different computational cultures (e.g., bioinformatics, physics) will require new domain‑specific prompts and tooling.
- Handling non‑code artifacts: Many social‑science studies rely on proprietary survey platforms or restricted datasets. Future work must incorporate secure data‑access protocols and synthetic data generation.
- Dynamic benchmark evolution: As reproducibility standards evolve, the benchmark suite should be continuously refreshed. An open‑source reproducibility benchmark hub could crowdsource new test cases.
- Human‑in‑the‑loop refinement: Integrating expert feedback to correct false negatives—cases where the system flags a paper as non‑reproducible despite a valid hidden step—will improve robustness.
Potential applications include:
- Embedding PaperRepro as a CI/CD step for research codebases, automatically rejecting pull requests that break reproducibility.
- Offering a SaaS API that journals can call during manuscript submission to generate reproducibility certificates.
- Coupling the system with large‑scale literature mining tools to produce “reproducibility maps” of entire research domains.
References
- Zhang, L., Xia, T., Piao, J., Cui, L., & Li, Y. (2026). PaperRepro: Automated Computational Reproducibility Assessment for Social Science Papers. arXiv preprint arXiv:2603.00058.
- REPRO‑Bench dataset – publicly released alongside the PaperRepro codebase.
- OpenAI. (2023). GPT‑4 Technical Report. Retrieved from https://openai.com/research/gpt-4.