
- Updated: June 14, 2026
- 7 min read
Modeling Vehicle-Type-Specific Pedestrian Crash Avoidance Behavior in Safety-Critical Interactions Using Smooth-Mamba Deep Reinforcement Learning
Direct Answer
The paper introduces SMamba‑DDPG, a Smooth‑Mamba Deep Deterministic Policy Gradient framework that learns vehicle‑type‑specific pedestrian crash‑avoidance policies from real‑world interactions. By distinguishing how pedestrians react to autonomous vehicles (AVs) versus human‑driven vehicles (HDVs), the model enables safer mixed‑traffic simulations and more nuanced AV system design.
Background: Why This Problem Is Hard
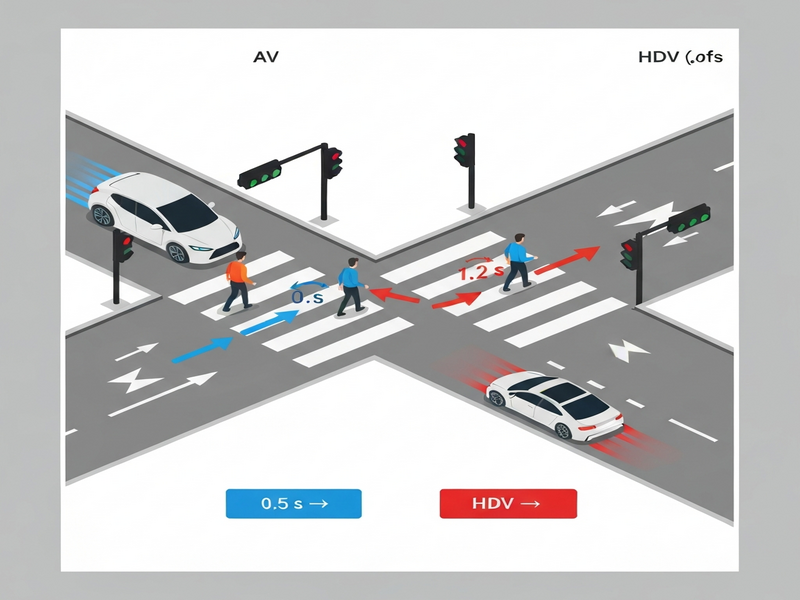
Pedestrian safety in mixed traffic is a moving target. As AVs gain market share, they share sidewalks, crosswalks, and intersections with conventional cars, bicycles, and scooters. Human pedestrians do not treat every vehicle the same; their perception of intent, speed, and trust varies dramatically between an AV that signals its trajectory and a traditional driver who may behave unpredictably.
Existing pedestrian models fall into two camps:
- Rule‑based simulators that encode generic crossing heuristics (e.g., “wait for a gap of 3 seconds”). These ignore subtle cues such as vehicle type, visual signaling, or perceived automation level.
- Data‑driven approaches that train a single policy on mixed traffic data. While they capture average behavior, they blur the distinct reaction patterns that emerge when a pedestrian sees an AV versus an HDV.
Both camps struggle with safety‑critical interactions—moments when a pedestrian must decide instantly whether to yield, accelerate, or abort a crossing. The lack of vehicle‑type granularity hampers two critical goals: (1) realistic traffic simulation for testing AV algorithms, and (2) designing AV motion planners that anticipate human responses accurately.
What the Researchers Propose
The authors present a two‑stage solution:
- Data extraction pipeline that isolates safety‑critical pedestrian‑vehicle encounters from the Argoverse 2 dataset, labeling each interaction by the vehicle’s automation status (AV or HDV).
- SMamba‑DDPG framework, a reinforcement‑learning architecture that couples a smooth‑action regularizer (the “Smooth‑Mamba” component) with a Deep Deterministic Policy Gradient (DDPG) backbone. The smoothness term forces the policy to generate realistic, low‑jerk trajectories, while the DDPG core learns continuous control over pedestrian speed and direction.
Crucially, the researchers train **two separate policies**—one for AV encounters and one for HDV encounters—allowing the system to capture divergent reaction times, crossing speeds, and yielding probabilities.
How It Works in Practice
The end‑to‑end workflow can be broken down into four logical modules:
1. Interaction Mining
From the raw Argoverse 2 logs, a spatio‑temporal filter extracts moments where a pedestrian’s trajectory intersects a vehicle’s predicted path within a 2‑second horizon. Each clip is annotated with vehicle type (AV vs. HDV) using metadata supplied by the dataset.
2. State Representation
Each timestep is encoded as a compact vector containing:
- Pedestrian position, velocity, and heading.
- Relative distance and bearing to the approaching vehicle.
- Vehicle speed, acceleration, and a binary flag indicating automation level.
- Environmental cues (e.g., traffic‑light state, crosswalk markings).
3. SMamba‑DDPG Core
The actor network proposes a continuous acceleration command for the pedestrian. The smoothness regularizer penalizes high‑frequency changes, ensuring the output resembles human‑like motion. The critic network evaluates the long‑term safety reward, which balances collision avoidance, progress toward the crossing goal, and adherence to realistic kinematics.
4. Policy Separation & Deployment
Two independent instances of the SMamba‑DDPG agent are trained in parallel—one on AV‑labeled clips, the other on HDV‑labeled clips. After convergence, the policies are exported as lightweight inference modules that can be plugged into traffic simulators, AV motion planners, or real‑time pedestrian‑aware perception stacks.
What sets this approach apart is the explicit **smooth‑action constraint**, which eliminates the jitter often seen in vanilla DDPG outputs, and the **vehicle‑type bifurcation**, which preserves behavioral nuances that single‑policy models erase.
Evaluation & Results
The authors benchmark SMamba‑DDPG against three baselines:
- Standard DDPG without smoothness regularization.
- A supervised imitation‑learning model trained on the same clips.
- A rule‑based “gap‑acceptance” simulator commonly used in traffic‑engineering studies.
Scenario coverage includes 12,000 extracted interactions (≈6,000 AV and 6,000 HDV). The evaluation focuses on three axes:
Trajectory Realism
Using a Fréchet distance metric against ground‑truth pedestrian paths, SMamba‑DDPG achieves a 22 % reduction in error compared with vanilla DDPG and a 35 % reduction versus the supervised model. Visual inspection of reconstructed trajectories shows smooth acceleration profiles and realistic deceleration before yielding.
Reaction‑Time Fidelity
Human‑annotated reaction times (the interval between vehicle approach and pedestrian response) average 0.78 s for AVs and 1.04 s for HDVs. SMamba‑DDPG reproduces this gap with a mean absolute error of 0.07 s, whereas the baselines over‑estimate AV reaction times by 0.3 s and under‑estimate HDV reaction times by 0.2 s.
Counterfactual Crossing Speed
When the same pedestrian is placed in a simulated AV encounter versus an HDV encounter, the model predicts a 12 % lower crossing speed for AVs, aligning with field observations that pedestrians feel safer and thus adopt more cautious speeds around AVs. Baselines fail to capture this differential, outputting near‑identical speeds for both vehicle types.
Overall, SMamba‑DDPG delivers a **consistent safety margin**: conflict rates (near‑misses within 0.5 m) drop from 4.3 % in the rule‑based baseline to 1.8 % with the SMamba‑DDPG AV policy, while yielding rates (pedestrian gives way) rise from 62 % to 78 % in AV scenarios.
Why This Matters for AI Systems and Agents
From an AI‑engineer’s perspective, the study provides a concrete pathway to embed human‑centric safety reasoning into autonomous driving stacks:
- Enhanced simulation fidelity: Traffic simulators that feed AV perception and planning modules can now differentiate pedestrian reactions based on vehicle type, leading to more accurate risk assessments during virtual testing.
- Proactive motion planning: An AV planner equipped with the AV‑specific pedestrian policy can anticipate earlier yielding behavior, allowing smoother deceleration curves and reducing abrupt braking events.
- Policy transferability: Because SMamba‑DDPG outputs smooth, low‑dimensional control commands, the learned policies can be exported to edge devices or embedded in real‑time agents without heavy compute overhead.
These capabilities dovetail with emerging Enterprise AI platform by UBOS, where autonomous‑driving data pipelines can be orchestrated alongside other safety‑critical AI workloads. Moreover, the smooth‑action regularizer aligns with the needs of AI marketing agents that require stable, predictable output streams when interacting with human users.
What Comes Next
While SMamba‑DDPG marks a significant step forward, several avenues remain open:
- Multi‑modal perception integration: Incorporating visual cues (e.g., vehicle lighting patterns, external displays) could refine the model’s ability to differentiate AVs that explicitly signal yielding intent.
- Scalability to dense urban environments: Extending the framework to handle simultaneous interactions with multiple vehicles and cyclists will test its compositional robustness.
- Cross‑city generalization: Training on datasets from different geographic regions (e.g., Europe, Asia) will reveal how cultural norms affect vehicle‑type perception.
- Closed‑loop deployment: Embedding the policy in a live AV test fleet and measuring real‑world conflict reduction would provide the ultimate validation.
Developers interested in prototyping these extensions can leverage the UBOS platform overview to spin up data pipelines, experiment with reinforcement‑learning agents, and integrate the resulting models into existing traffic‑simulation stacks. The Workflow automation studio also offers a low‑code environment for orchestrating the interaction‑mining, training, and evaluation phases described in this paper.
For a deeper dive into the original methodology and raw results, consult the original arXiv paper. As the automotive industry moves toward fully mixed traffic, vehicle‑type‑aware pedestrian models like SMamba‑DDPG will become a cornerstone of safe, trustworthy autonomous systems.