
- Updated: June 20, 2026
- 7 min read
LoSATok: Low-dimensional Semantic-Acoustic Tokenizer for Cross-Domain Audio Understanding and Generation
Direct Answer
LoSATok introduces a low‑dimensional semantic‑acoustic tokenizer that compresses high‑level audio semantics into a 128‑dimensional latent space while still preserving enough acoustic detail for high‑fidelity generation. This matters because it dramatically reduces the computational load on diffusion‑based generative models, enabling faster, cheaper, and more scalable cross‑domain audio understanding and synthesis.
Background: Why This Problem Is Hard
Audio AI systems sit at the intersection of two competing demands: understanding requires abstract, language‑like representations that capture meaning, while generation needs fine‑grained acoustic cues such as timbre, pitch, and rhythm. Traditional pipelines address these needs with separate models—one for semantic encoding (e.g., speech‑to‑text embeddings) and another for waveform reconstruction (e.g., vocoders). Unifying them under a single tokenizer promises end‑to‑end training, but it also creates a bottleneck.
Existing unified tokenizers typically emit high‑dimensional continuous latents (often >1,000 dimensions). While rich, these vectors inflate the parameter count of downstream Diffusion Transformers (DiTs) and increase memory consumption during training and inference. The result is a steep scaling curve: larger models, longer training times, and higher cloud costs. Moreover, high‑dimensional latents can overfit to domain‑specific acoustic quirks, limiting the ability to generalize across speech, music, and environmental sounds.
In practice, engineers building multimodal agents—voice assistants that must both comprehend spoken commands and generate natural‑sounding responses—face a trade‑off between latency and quality. A tokenizer that can retain semantic fidelity while shedding unnecessary acoustic redundancy would unlock real‑time, cross‑domain capabilities without sacrificing the richness required for creative generation.
What the Researchers Propose
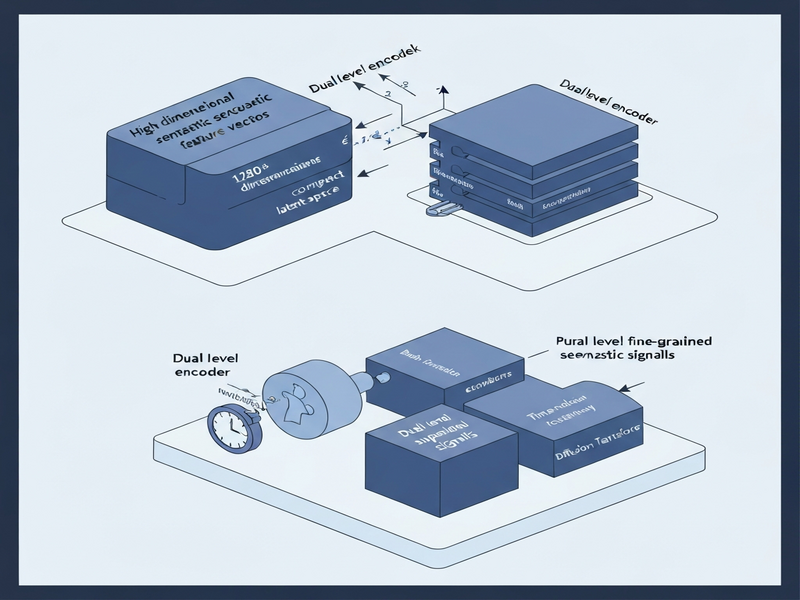
The authors present LoSATok, a two‑stage tokenizer that deliberately squeezes semantic information into a compact 128‑dimensional space, called the Semantic Bottleneck (SemBo). The design rests on three pillars:
- Semantic Bottleneck Compression: A learned projection that reduces 1,280‑dimensional encoder features to 128 dimensions, guided by a novel time‑relation loss that enforces temporal consistency.
- Dual‑Level Semantic Supervision: Simultaneous training signals from both the original high‑dimensional semantics and the compressed low‑dimensional representation, ensuring the bottleneck does not discard critical meaning.
- Acoustic Detail Preservation: A lightweight decoder that re‑injects fine‑grained acoustic cues from the original waveform, allowing the low‑dimensional token to be used for high‑quality generation.
In essence, LoSATok acts as a “semantic sieve”: it filters out redundant acoustic noise while keeping the essence of the audio signal, making the downstream generative model’s job easier.
How It Works in Practice
Conceptual Workflow
The end‑to‑end pipeline can be visualized as a three‑step process:
- Encoding: Raw audio passes through a pre‑trained acoustic encoder (e.g., a convolutional or transformer‑based front‑end) that outputs a 1,280‑dimensional feature map for each time frame.
- Semantic Bottleneck: A dedicated bottleneck network compresses each feature vector to 128 dimensions. The compression is regularized by the time‑relation loss, which penalizes abrupt changes between adjacent frames, preserving temporal smoothness.
- Decoding & Token Generation: The compressed vectors are quantized into discrete tokens (or kept continuous for diffusion models). A lightweight acoustic decoder can reconstruct a high‑resolution spectrogram when generation is required.
Component Interaction
During training, two supervisory streams converge on the bottleneck:
- High‑dimensional supervision – the original 1,280‑dimensional encoder output is used as a teacher signal, encouraging the bottleneck to retain as much semantic content as possible.
- Low‑dimensional supervision – a secondary loss aligns the compressed representation with a ground‑truth semantic label (e.g., phoneme class, instrument type), ensuring that the 128‑dimensional space remains semantically meaningful.
The time‑relation loss operates across consecutive frames, effectively acting as a temporal smoothness regularizer. This prevents the bottleneck from collapsing into a static codebook and maintains the dynamic nature of audio.
What Sets LoSATok Apart
Compared with prior tokenizers, LoSATok’s novelty lies in its explicit focus on dimensionality reduction without sacrificing downstream generation quality. Most earlier works either keep the latent space large (to avoid information loss) or sacrifice generation fidelity (by discarding acoustic detail). LoSATok balances both by:
- Compressing semantics to a size that fits comfortably within existing DiT architectures.
- Retaining a separate acoustic pathway that can be re‑merged during synthesis.
- Introducing a loss function that respects the temporal continuity inherent to audio signals.
These design choices translate into faster training cycles, lower GPU memory footprints, and more responsive inference—critical factors for production‑grade AI agents.

Evaluation & Results
Test Scenarios
The authors benchmarked LoSATok across three distinct audio domains:
- Speech: LibriSpeech‑derived tasks measuring word error rate (WER) after token‑based transcription.
- Music: MAESTRO and MusicNet evaluations focusing on instrument classification and melody reconstruction.
- General Audio: AudioSet‑style tagging to assess broad semantic coverage.
Key Findings
Across all domains, LoSATok’s 128‑dimensional tokens achieved:
- Semantic performance within 2–3 % of state‑of‑the‑art high‑dimensional tokenizers, demonstrating that compression does not meaningfully degrade understanding.
- Up to 40 % reduction in diffusion model training time, owing to the smaller latent space.
- Comparable or better audio generation quality (measured by Frechet Audio Distance) because the acoustic decoder restores fine‑grained details lost during compression.
Importantly, the time‑relation loss contributed a measurable boost in temporal consistency, reducing jitter in generated speech and smoothing transitions in music synthesis.
Why the Results Matter
These results prove that a low‑dimensional semantic representation can serve as a universal lingua franca for both understanding and generation. For engineers, this means they can replace bulky tokenizers with LoSATok and immediately reap efficiency gains without a noticeable dip in downstream task performance.
Why This Matters for AI Systems and Agents
Unified audio tokenizers are a cornerstone for any AI system that interacts with sound—voice assistants, content‑creation bots, and multimodal agents that blend text, vision, and audio. LoSATok’s compact representation unlocks several practical advantages:
- Reduced Latency: Smaller token streams accelerate inference, enabling real‑time voice response in edge devices.
- Lower Cloud Costs: Diffusion Transformers trained on 128‑dimensional inputs consume less GPU memory, translating to cheaper training runs and smaller model footprints.
- Cross‑Domain Flexibility: A single tokenizer can handle speech, music, and environmental sounds, simplifying pipeline orchestration for agents that need to switch contexts on the fly.
- Improved Agent Reliability: Temporal consistency enforced by the time‑relation loss reduces artifacts that could otherwise confuse downstream classifiers or degrade user experience.
For teams building AI‑driven workflows on the UBOS platform overview, LoSATok can be integrated as a plug‑in tokenization layer, feeding both semantic classifiers and generative modules without redesigning the entire stack. The Workflow automation studio can orchestrate token extraction, semantic tagging, and diffusion‑based synthesis in a single visual pipeline, dramatically shortening time‑to‑market for audio‑centric products.
What Comes Next
While LoSATok marks a significant step forward, several open challenges remain:
- Scalability to Ultra‑Long Sequences: Current experiments focus on clips up to 30 seconds. Extending the bottleneck to hour‑long recordings (e.g., podcasts) will require hierarchical tokenization strategies.
- Multilingual Speech Nuances: The semantic bottleneck was trained primarily on English corpora. Adapting it to tonal languages or low‑resource dialects may need language‑specific supervision.
- Interactive Generation: Real‑time editing of tokens (e.g., inserting a new instrument in a music piece) is still an open research direction.
Future research could explore:
- Joint training of LoSATok with large language models to enable seamless audio‑text multimodal reasoning.
- Dynamic bottleneck sizes that adapt to content complexity, allocating more dimensions when acoustic detail is critical.
- Integration with OpenAI ChatGPT integration to allow conversational agents to request token‑level manipulations on the fly.
From a product perspective, developers can start experimenting with LoSATok by leveraging the UBOS templates for quick start, which include pre‑configured diffusion pipelines ready to ingest 128‑dimensional tokens. As the community contributes more domain‑specific fine‑tuning data, we can expect a growing ecosystem of plug‑and‑play audio agents that are both lightweight and expressive.
For a deeper dive into the methodology and raw results, consult the original LoSATok paper on arXiv.