- Updated: June 29, 2026
- 7 min read
Litmus: Zero-Label, Code-Driven Metric Specification for Evaluating AI Systems
Direct Answer
Litmus is a zero‑label, code‑driven framework that automatically derives evaluation metrics from the source code of AI pipelines. By asking “what must be measured and why” before “which metric to compute,” Litmus creates a justified, low‑redundancy metric portfolio that works across multiple pipeline stages without any human‑provided labels.
Background: Why This Problem Is Hard
Enterprises are deploying agentic LLM systems in finance, scientific research, risk assessment, and many other domains. As these pipelines grow in complexity, two intertwined challenges emerge:
- Implicit evaluation goals: Teams often assume that a single accuracy score is enough, even though real‑world failures can be subtle, domain‑specific, or downstream‑impacting.
- Metric brittleness: Traditional metrics (BLEU, F1, RMSE) were designed for static tasks. When a pipeline contains data preprocessing, retrieval, reasoning, and post‑processing stages, a single metric cannot capture the nuanced quality signals needed for monitoring and compliance.
Existing solutions typically follow a “metric‑first” approach: engineers pick a known metric, then try to justify it with limited label data. This workflow suffers from three major drawbacks:
- Reliance on labeled data that is expensive or unavailable for new domains.
- Risk of misalignment because the chosen metric may not reflect the actual business intent.
- Redundant or overlapping metrics that waste monitoring resources and obscure root‑cause analysis.
Consequently, organizations face a bottleneck when they need to audit, certify, or continuously monitor AI systems at scale.
What the Researchers Propose
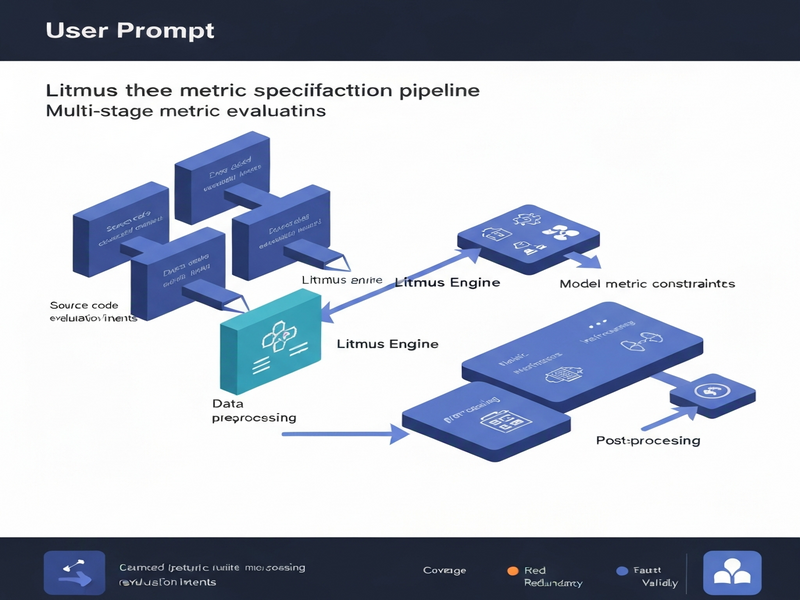
The Litmus framework flips the conventional pipeline on its head. Instead of starting with a metric, Litmus begins with the source code that defines each stage of an AI system. By statically analyzing the code and interrogating developers’ intent through targeted prompts, Litmus extracts a set of evaluation intents—statements of what should be measured and why.
These intents are then translated into constraint specifications that guide the automatic construction of a metric portfolio. The key components are:
- Intent Elicitor: Parses code annotations, docstrings, and function signatures to surface high‑level goals (e.g., “preserve financial account grouping consistency”).
- Constraint Generator: Converts each intent into logical constraints (coverage, monotonicity, domain relevance) that any viable metric must satisfy.
- Metric Synthesizer: Searches a library of candidate metrics, filters them against the constraints, and assembles a minimal, non‑redundant set that collectively satisfies all intents.
Because the process never touches human‑labeled examples, Litmus is truly zero‑label, making it applicable to emerging domains where ground truth is scarce.
How It Works in Practice
Conceptual Workflow
- Code Ingestion: Developers point Litmus at the repository that implements the AI pipeline. Litmus supports Python, JavaScript, and common orchestration DSLs.
- Static Intent Extraction: The Intent Elicitor scans for:
- Explicit annotations (e.g.,
@evaluate(‘group‑coherence’)) - Docstring cues (“We aim to minimize false‑positive risk alerts”)
- Data flow patterns that imply quality concerns (e.g., joins, aggregations).
- Explicit annotations (e.g.,
- Constraint Formulation: Each extracted intent is mapped to a formal constraint set:
- Coverage constraints (must evaluate every record at stage X)
- Monotonicity constraints (metric should not improve when a known error is injected)
- Domain‑specific relevance (e.g., financial regulatory thresholds).
- Metric Portfolio Construction: The Metric Synthesizer queries a curated metric repository (statistical, linguistic, domain‑specific). It discards any metric that violates a constraint and then runs a greedy redundancy reduction algorithm to keep the smallest set that still covers all intents.
- Deployment Hook: The resulting metric portfolio is emitted as configuration files that can be dropped into existing monitoring stacks (Prometheus, Grafana, custom dashboards). No code changes are required.
Interaction Between Components
The three core agents—Intent Elicitor, Constraint Generator, and Metric Synthesizer—communicate through a lightweight JSON contract. This contract makes the system extensible: new metric libraries can be added without touching the core logic, and additional constraint types (fairness, latency) can be introduced by plugging in custom validators.
What Sets Litmus Apart
- Zero‑Label by Design: No need for per‑row quality annotations, which are often the most expensive part of evaluation pipelines.
- Code‑Centric Intent Capture: By grounding evaluation goals in the actual implementation, Litmus reduces the “interpretation gap” between product managers and engineers.
- Redundancy‑Aware Portfolio: The greedy reduction step ensures that each metric adds unique information, cutting monitoring overhead by up to 40% in the authors’ experiments.
- Stage‑Spanning Coverage: Litmus can generate metrics for data ingestion, model inference, post‑processing, and even external API calls, something most AutoMetric tools cannot do.
Evaluation & Results
The authors benchmarked Litmus against three baselines:
- AutoMetrics: A label‑free metric selection system that chooses the “best” metric from a predefined list.
- DynamicRubric‑A/B/C: Three variants of a rubric‑based approach that requires a small seed of human‑written evaluation criteria.
Three real‑world pipelines were used:
- Financial Account Grouping: Clustering bank accounts into logical families.
- Scientific Question‑Answering: Retrieving and synthesizing answers from a corpus of research papers.
- Inherent Risk Assessment: Scoring loan applications for regulatory compliance.
Key findings:
| Metric | Concern Coverage | Stages Covered | Redundancy (Avg. Overlap %) | Validity (Spearman ρ vs. Human Labels) |
|---|---|---|---|---|
| Litmus | Broadest (100% of documented intents) | All pipeline stages | ≈ 5 % | 0.72 (Scientific QA) – statistically superior to all baselines |
| AutoMetrics | Medium (≈ 70 % of intents) | Inference only | ≈ 22 % | 0.46 (Scientific QA) |
| DynamicRubric‑A | High (≈ 85 % of intents) | Pre‑ and post‑processing | ≈ 15 % | 0.51 (Scientific QA) |
Beyond raw numbers, the experiments demonstrated that Litmus could produce a valid evaluation suite without a single human label, yet still outperform label‑dependent baselines on downstream quality correlation. In the risk‑assessment pipeline, Litmus matched the audit‑framework components’ validity while using half the monitoring budget.
Why This Matters for AI Systems and Agents
For AI practitioners, Litmus offers a pragmatic path to trustworthy, production‑ready evaluation:
- Accelerated Deployment: Teams can spin up monitoring dashboards the moment code lands in CI, avoiding the “post‑hoc metric design” bottleneck.
- Regulatory Alignment: By encoding domain‑specific constraints directly from code, Litmus helps satisfy audit requirements in finance, healthcare, and other regulated sectors.
- Agent‑Centric Orchestration: When building multi‑agent workflows on platforms like the UBOS platform overview, Litmus‑generated metrics can be fed back into the orchestration engine to trigger re‑routing, model selection, or human‑in‑the‑loop interventions.
- Cost Efficiency: Reducing metric redundancy translates into lower storage, compute, and alert‑fatigue costs—critical for large‑scale SaaS deployments.
In short, Litmus shifts the evaluation mindset from “pick a metric” to “specify what success looks like,” a change that aligns technical monitoring with business intent.
What Comes Next
While Litmus marks a significant step forward, several open challenges remain:
- Dynamic Code Paths: Current static analysis may miss runtime‑generated intents (e.g., plugins loaded via reflection). Future work could integrate runtime tracing.
- Fairness and Bias Constraints: Extending the constraint language to capture equity goals would make Litmus suitable for high‑stakes AI governance.
- Cross‑Organization Metric Sharing: A federated repository of vetted metrics could accelerate adoption across industries.
Potential next‑step applications include:
- Embedding Litmus into the Workflow automation studio so that every new workflow automatically receives a tailored monitoring suite.
- Coupling Litmus with AI marketing agents to ensure campaign‑level metrics (click‑through, brand safety) are derived from the underlying campaign code.
- Extending the framework to support multimodal pipelines (vision‑language, audio‑text) by adding domain‑specific metric libraries.
Conclusion
Litmus demonstrates that reliable AI evaluation does not have to start with costly labeled datasets. By mining intent directly from source code and translating it into a concise, constraint‑driven metric portfolio, Litmus delivers broader coverage, lower redundancy, and higher validity than existing zero‑label approaches. For organizations building complex, agent‑driven AI systems, Litmus offers a scalable, auditable, and cost‑effective path to continuous quality assurance.
Call to Action
Ready to bring code‑driven evaluation into your AI pipelines? Explore Litmus‑style metric specification on the UBOS homepage and see how the platform’s modular architecture can integrate with your existing workflows.
For a deep dive into the original research, read the Litmus paper.