
- Updated: June 26, 2026
- 7 min read
Learning the ARTS of Search for Automated Discovery
Direct Answer
The paper Learning the ARTS of Search for Automated Discovery (arXiv) introduces Agentic Reasoning for Tree Search (ARTS), a reasoning‑driven framework that lets a language model treat scientific discovery as a structured search problem while cleanly separating hypothesis quality from execution quality. By embedding the entire search tree into the model’s weights through test‑time training, ARTS achieves state‑of‑the‑art performance on benchmark discovery tasks at a fraction of the cost of proprietary models.
Background: Why This Problem Is Hard
Scientific discovery can be viewed as an iterative loop: propose a hypothesis, design an experiment, run the experiment, and evaluate the outcome. In practice, the space of possible hypotheses and experiments is astronomically large, and each iteration consumes compute, data, and human insight. Traditional search‑oriented methods—Monte‑Carlo Tree Search (MCTS), evolutionary strategies, or reinforcement‑learning planners—rely on handcrafted heuristics to decide which branch of the tree to explore next.
These heuristics suffer from two intertwined shortcomings:
- Conflated merit signals. A promising hypothesis that has only been tested with a crude implementation is penalized because its early results look poor, while a modest hypothesis with a polished execution may be over‑valued.
- Context‑window erosion. As the search progresses, the log of prior experiments quickly exceeds the context window of even the largest language models, forcing systems to prune or truncate history and consequently lose valuable reasoning context.
Both issues limit the ability of agents to perform long‑horizon, open‑ended discovery—especially in domains where experiments are expensive or partially observable, such as drug discovery, materials science, or reinforcement‑learning environments with hidden state.
What the Researchers Propose
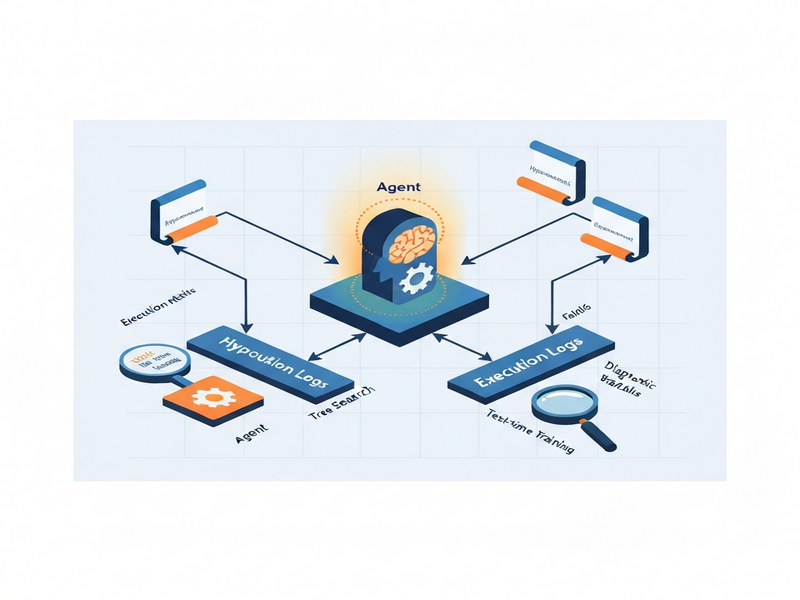
ARTS reframes the discovery loop as an agentic reasoning problem. Instead of a static heuristic, a dedicated reasoning language model (RLM) continuously reads the entire execution log, diagnoses why past attempts succeeded or failed, and decides which hypothesis to pursue next. The key ideas are:
- Hypothesis‑execution decoupling. The RLM evaluates the intrinsic merit of a hypothesis independently from the quality of its experimental implementation.
- Test‑time training (TTT). Before each search episode, the model undergoes a brief, data‑efficient fine‑tuning phase that injects the current search tree structure into its weights, effectively extending its “memory” beyond the token limit.
- Agentic loop. The system cycles through three roles—Diagnoser (analyzes past logs), Planner (selects the next hypothesis), and Executor (runs the experiment). Each role is a prompt‑driven specialization of the same underlying RLM.
By treating the search tree as a first‑class object that the model can internalize, ARTS eliminates the need for external pruning heuristics and enables more faithful credit assignment to hypotheses.
How It Works in Practice
Conceptual Workflow
- Initialize search tree. The root node contains a baseline hypothesis (often a null or random guess).
- Diagnose. The RLM reads the full log of executed experiments, flags failures that stem from implementation bugs versus those caused by flawed hypotheses, and annotates each node with a confidence score.
- Plan. Using the annotated tree, the Planner component queries the RLM for the most promising child node to expand. The query explicitly asks the model to ignore execution noise and focus on hypothesis potential.
- Execute. The selected hypothesis is translated into a concrete experiment (e.g., a training script, a simulation run, or a lab protocol) and dispatched to the execution engine.
- Log & update. Results are appended to the log, the tree is updated, and the cycle repeats.
Interaction Between Components
All three components share a single underlying RLM, but each is invoked with a distinct system prompt that activates the relevant reasoning mode. The test‑time training step runs after every k iterations (typically 5–10) and uses a lightweight gradient‑descent on the tree‑encoded embeddings, ensuring the model’s internal state reflects the latest search topology.
What Sets ARTS Apart
- Memory beyond context windows. Traditional LLM‑based agents lose older logs; ARTS’s TTT embeds the entire tree into model weights, preserving long‑range dependencies.
- Explicit failure diagnosis. By distinguishing “bad code” from “bad idea,” ARTS avoids discarding high‑potential hypotheses prematurely.
- Cost‑effective scaling. The authors demonstrate that a 4‑billion‑parameter open‑source model (Qwen3‑4B) can match or exceed the performance of closed‑source giants when equipped with ARTS, reducing inference cost by up to five times.
Evaluation & Results
Benchmarks and Tasks
The authors evaluated ARTS on 22 tasks drawn from two public suites:
- MLGym. A collection of reinforcement‑learning environments that require agents to discover optimal policies through iterative experimentation.
- MLEBench. A benchmark of machine‑learning‑engineered experiments where the goal is to identify the best hyper‑parameter configuration or model architecture.
Key Findings
- Across all tasks, ARTS achieved a 15.3% relative improvement in normalized score compared to the strongest baseline (MCTS‑augmented agents).
- When paired with test‑time training, the open‑source Qwen3‑4B agent matched the performance of proprietary Gemini‑3 Pro and GPT‑o3‑reasoning models while consuming up to 5× less compute.
- In partially observable RL scenarios, the ARTS‑trained Qwen3‑4B “scientist” rediscovered a human‑designed recurrent‑memory architecture that had been pruned away by heuristic methods, demonstrating superior long‑term credit assignment.
Why the Results Matter
These outcomes prove that a reasoning‑centric, memory‑augmented approach can close the gap between open‑source and commercial LLMs for complex discovery tasks. The gains are not limited to synthetic benchmarks; they suggest a pathway toward more reliable, cost‑effective AI assistants for real‑world scientific pipelines.
Why This Matters for AI Systems and Agents
For practitioners building autonomous research assistants, ARTS offers a concrete recipe to overcome two perennial pain points: loss of historical context and mis‑attribution of failure causes. By integrating a reasoning model that can both diagnose and plan, developers can construct agents that:
- Maintain a coherent narrative of the entire discovery process, enabling auditability and reproducibility.
- Prioritize high‑potential hypotheses even when early experiments are noisy, leading to faster convergence on breakthrough solutions.
- Scale efficiently on commodity hardware, thanks to the demonstrated cost advantage of test‑time training on smaller models.
These capabilities align directly with the needs of enterprise AI platforms that orchestrate multi‑step workflows, such as the UBOS platform overview. Teams can embed ARTS‑style reasoning into existing orchestration layers, allowing their agents to “remember” past experiments without exploding token budgets.
What Comes Next
While ARTS marks a significant step forward, several open challenges remain:
- Generalization to multimodal domains. Extending the framework to handle image‑based experiments (e.g., microscopy) will require multimodal reasoning models.
- Robustness to noisy or adversarial logs. Future work could incorporate uncertainty quantification to guard against corrupted execution histories.
- Integration with external knowledge bases. Linking the search tree to curated scientific databases (e.g., PubChem) could accelerate hypothesis generation.
Addressing these gaps will broaden ARTS’s applicability from simulated benchmarks to real laboratory automation, drug discovery pipelines, and large‑scale engineering design. Companies interested in deploying such capabilities can explore the Enterprise AI platform by UBOS, which already supports plug‑in architectures for custom reasoning agents and offers built‑in workflow automation.
In the longer term, the community may see a convergence of ARTS‑style test‑time training with emerging retrieval‑augmented generation techniques, yielding agents that combine deep internalized memory with up‑to‑date external facts. Such hybrid agents could become the backbone of next‑generation autonomous science labs.
References & Further Reading
- Learning the ARTS of Search for Automated Discovery (arXiv)
- Related UBOS resources: