
- Updated: June 21, 2026
- 7 min read
Learning Compositional Latent Structure with Vector Networks
Direct Answer
Vector Networks (VNs) replace the monolithic weight matrices of conventional deep nets with a reusable library of rank‑1 weight atoms, allowing each input to assemble its own low‑rank transformation on the fly. This architectural shift makes compositional generalization a built‑in property rather than a fragile byproduct of training.
Background: Why This Problem Is Hard
Modern deep learning models excel at fitting massive datasets, yet they struggle when a familiar pattern must be recombined in a novel configuration. The root cause is the shared‑parameter paradigm: a single dense matrix must encode many distinct sub‑computations, forcing the optimizer to entangle unrelated behaviours. When a new combination of known factors appears—think a new recipe made from familiar ingredients—the model often fails to extrapolate because the underlying weight matrix cannot be selectively re‑used.
Existing attempts to address compositionality fall into three camps:
- Modular networks that hard‑wire separate sub‑modules, but they require explicit routing logic and scale poorly with the number of factors.
- Neural program synthesis that learns to generate code‑like structures, yet training is unstable and inference is computationally heavy.
- Low‑rank factorization methods that compress weights but do not provide a mechanism for dynamic recombination of factors at test time.
All three approaches either impose rigid architectural constraints or rely on brittle post‑hoc tricks, leaving a gap for a truly compositional, scalable, and inference‑driven solution.
What the Researchers Propose
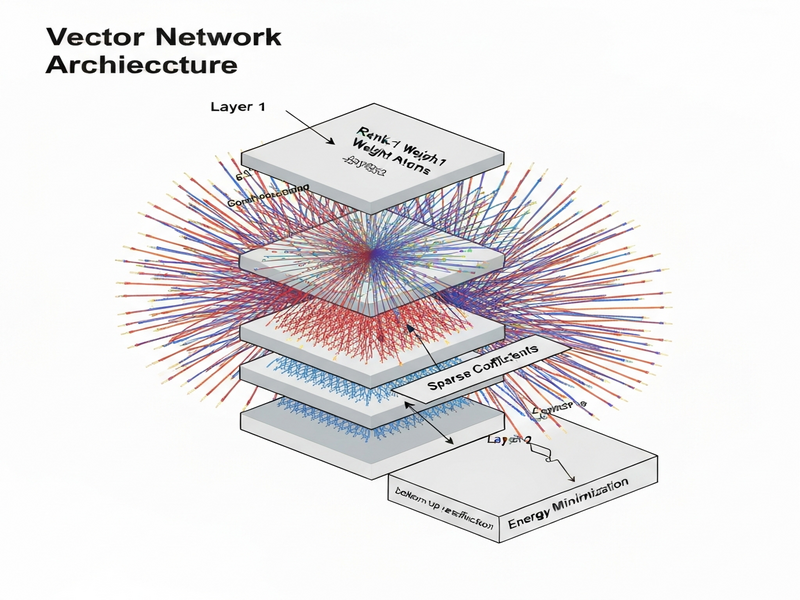
The authors introduce the Vector Network, a hierarchical recurrent architecture that treats each layer as a library of rank‑1 weight atoms. Instead of a fixed matrix, a layer maintains a pool of simple outer‑product vectors. For any given input, the network solves a small, layer‑local energy minimization problem that selects a sparse subset of atoms and assigns them coefficients. These coefficients then reconstruct an input‑specific low‑rank weight matrix, which is used for the forward pass.
Key components of the VN framework include:
- Weight atom library: a shared set of rank‑1 vectors that can be reused across samples and layers.
- Sparse inference engine: an optimization routine that balances bottom‑up reconstruction error with top‑down feedback consistency, yielding a compact active set of atoms.
- Local residual learning: after inference converges, only the selected atoms receive gradient updates, scaled by their inferred coefficients.
This design makes the compositional structure explicit: the same atom can participate in many different contexts, and new contexts are built by simply re‑combining existing atoms.
How It Works in Practice
The VN workflow can be broken down into three stages that repeat across layers:
- Bottom‑up encoding: The input signal is projected onto the atom library, producing an initial reconstruction error.
- Sparse selection: An energy function—penalizing reconstruction error and encouraging sparsity—is minimized using a few iterations of coordinate descent or a learned optimizer. The result is a set of active atoms and their scalar coefficients.
- Top‑down feedback: The selected atoms generate a low‑rank weight matrix that is applied to the input, producing an updated representation that is fed to the next layer. Consistency constraints ensure that the feedback does not diverge from the bottom‑up signal.
What distinguishes VNs from prior low‑rank tricks is the dynamic nature of the atom selection. The same pool of atoms serves every sample, but each forward pass assembles a unique matrix tailored to the current context. This on‑the‑fly composition eliminates the need for a separate routing network or explicit program synthesis.
Training proceeds with standard back‑propagation, but gradients are filtered through the sparse mask: only the atoms that were active for a given sample receive updates, and the magnitude of each update is modulated by the corresponding coefficient. This localized learning reduces interference between unrelated tasks and preserves the reusability of atoms.
Visually, the process resembles a craftsman selecting a handful of tools from a shared toolbox to build a custom piece, rather than forcing a single, monolithic machine to perform every possible job.
Evaluation & Results
The authors benchmarked VNs on four compositional tasks that span different data modalities:
- 1D signal synthesis: Re‑combining sinusoidal components in unseen phase‑amplitude configurations.
- 2D spatial decoding: Reconstructing images from a set of primitive shapes arranged in novel layouts.
- N‑body dynamics: Predicting particle trajectories when known interaction rules are mixed in new ways.
- Compositional MNIST: Classifying digits formed by overlaying multiple handwritten characters.
Across all benchmarks, VNs matched or exceeded strong baselines (standard CNNs, modular networks, and low‑rank factorized models) on in‑distribution test sets. More importantly, when the test distribution required novel recombinations of familiar factors—i.e., out‑of‑distribution (OOD) compositional generalization—VNs achieved error rates roughly ten times lower than the best baselines.
These results demonstrate two critical points:
- The atom library successfully captures reusable sub‑structures, enabling the network to “plug‑and‑play” them in new configurations without retraining.
- The sparse inference mechanism provides a principled way to select the right subset of atoms, avoiding the over‑generalization that plagues dense weight matrices.
Qualitative visualizations showed that the same atom could be traced across multiple samples, confirming that the network learns truly shared components rather than memorizing whole inputs.
Why This Matters for AI Systems and Agents
Compositional generalization is a cornerstone for building robust AI agents that can adapt to evolving environments. Vector Networks offer a concrete pathway to achieve this:
- Modular reasoning: Agents can store reusable “knowledge atoms” that are recombined on demand, reducing the need for exhaustive retraining when new tasks appear.
- Efficient fine‑tuning: Because only a sparse subset of atoms is updated during learning, fine‑tuning on a downstream task becomes faster and less prone to catastrophic forgetting.
- Scalable orchestration: In multi‑agent systems, a shared atom library can serve as a common knowledge base, simplifying coordination and reducing memory footprints.
Practically, developers can embed VNs into existing pipelines using the UBOS platform overview, which already supports custom neural components. For teams building conversational assistants, the AI marketing agents can benefit from VNs by reusing sentiment‑analysis atoms across campaigns, cutting down on model size while improving adaptability. Early‑stage startups looking for a compositional edge can experiment with VNs through the UBOS for startups program, gaining access to pre‑configured training loops and atom‑library management tools.
What Comes Next
While Vector Networks mark a significant step forward, several open challenges remain:
- Scalability of atom libraries: As tasks grow more complex, the number of required atoms may increase. Efficient indexing and retrieval mechanisms are needed to keep inference fast.
- Learning atom semantics: Currently, atoms are learned implicitly. Future work could enforce semantic constraints (e.g., “shape” vs. “color” atoms) to improve interpretability.
- Integration with reinforcement learning: Extending VNs to policy networks could enable agents that compose action primitives on the fly.
- Hardware acceleration: Rank‑1 outer‑product operations map well to modern tensor cores, but dedicated kernels would further reduce latency.
Addressing these topics will likely involve cross‑disciplinary effort, blending ideas from sparse coding, meta‑learning, and systems engineering. Organizations interested in pioneering this frontier can explore the Enterprise AI platform by UBOS, which offers scalable compute clusters and built‑in support for custom layer definitions. For rapid prototyping, the Workflow automation studio lets engineers stitch together atom‑selection pipelines without writing low‑level code. Finally, teams can evaluate cost‑effectiveness and plan deployments using the UBOS pricing plans, ensuring that the added architectural complexity aligns with budget constraints.
References
Learning Compositional Latent Structure with Vector Networks (arXiv)