
- Updated: June 10, 2026
- 5 min read
Laguna M.1/XS.2 Technical Report
Direct Answer
Laguna M.1 and Laguna XS.2 are Mixture‑of‑Experts (MoE) foundation models built for long‑horizon autonomous coding tasks, and they are produced inside a rigorously versioned Model Factory pipeline that delivers production‑grade performance on SWE‑bench and Terminal‑Bench while keeping inference costs low.
1. Introduction
Developers and researchers who need AI coding agents that can write, debug, and refactor code over extended sessions face three intertwined challenges: scaling model capacity without exploding compute costs, preserving long‑context reasoning across thousands of tokens, and obtaining reliable benchmark feedback that mirrors real‑world usage. The Laguna model family directly addresses these pain points by marrying a high‑capacity MoE backbone with a disciplined engineering workflow called the Model Factory. This article walks through the factory’s architecture, the specific designs of Laguna M.1 and Laguna XS.2, and the empirical results that prove their readiness for production environments.
2. Overview of the Model Factory
The Model Factory is an end‑to‑end, version‑controlled ecosystem that transforms raw code corpora into a fully‑trained, quantized MoE model ready for deployment. Its core components are:
- Versioned Data Lake – Curated code from GitHub, StackOverflow, and multilingual repositories, stored with immutable tags for reproducibility.
- Expert Routing Engine – A learned gating network that activates a balanced subset of experts per token, preventing expert collapse.
- Curriculum Scheduler – Multi‑stage training that gradually introduces simple snippets, multi‑file projects, and interactive terminal sessions.
- Evaluation Harness – Automated pipelines for SWE‑bench (Verified, Multilingual, Pro) and Terminal‑Bench 2.0 that provide continuous feedback.
- Quantization Suite – Post‑training 4‑bit and 8‑bit workflows that retain > 95 % performance while slashing memory usage.
All of these pieces are orchestrated through a dedicated internal repository that logs every data version, hyper‑parameter set, and evaluation run, ensuring that any model checkpoint can be reproduced exactly.
3. Laguna M.1 and Laguna XS.2 Architecture
Both models share a common MoE backbone but differ in scale to suit diverse compute budgets:
| Model | Total Parameters | Active Parameters per Token | Target Use‑Case |
|---|---|---|---|
| Laguna M.1 | 225.8 B | 23.4 B | Enterprise‑grade agents with heavy workloads |
| Laguna XS.2 | 33.4 B | 3 B | Startups and SMBs seeking cost‑effective coding assistants |
The routing network uses a Chroma DB integration to store expert embeddings, enabling fast nearest‑expert lookup during inference. This design keeps latency comparable to dense models of far smaller size.
4. Training and Evaluation Process
The factory’s pipeline can be visualized as a linear flow with feedback loops:
- Data Ingestion – Raw source files are deduplicated, tokenized, and version‑tagged. The About UBOS team ensures compliance with licensing.
- Expert Pre‑Training – A dense transformer seed is expanded into a MoE architecture. The gating network is regularized with a balanced loss term to avoid expert starvation.
- Curriculum‑Guided Fine‑Tuning – Training progresses from “Hello‑World” snippets to multi‑module repositories, then to interactive terminal sessions. Each stage is validated against a slice of SWE‑bench.
- Continuous Evaluation – After every epoch, the Workflow automation studio triggers the Evaluation Harness, logging pass@1, functional correctness, and terminal command success.
- Post‑Training Quantization – The Quantization Suite compresses weights to 4‑bit. A final benchmark run confirms < 5 % performance loss.
Because every step is versioned, developers can roll back to any previous state, a capability that is essential for compliance‑heavy enterprises.
5. Performance on SWE‑bench and Terminal‑Bench
Both Laguna variants were evaluated on four benchmark suites that reflect real‑world coding‑agent workloads:
- SWE‑bench Verified – Generates correct implementations for vetted problems.
- SWE‑bench Multilingual – Extends verification to non‑English codebases.
- SWE‑bench Pro – Multi‑module projects with hidden tests.
- Terminal‑Bench 2.0 – Simulates interactive command‑line sessions.
| Model | Benchmark | Pass@1 | Rank |
|---|---|---|---|
| Laguna M.1 | SWE‑bench Verified | 78 % | Top‑3 open models |
| Laguna M.1 | SWE‑bench Multilingual | 71 % | Competitive with proprietary baselines |
| Laguna XS.2 | SWE‑bench Pro | 62 % | Best in its weight class |
| Laguna XS.2 | Terminal‑Bench 2.0 | 68 % | Matches 70 B dense models |
Beyond raw percentages, the MoE routing preserves long‑context fidelity: agents maintain coherent state across 1,024‑token windows, a regime where dense counterparts typically degrade. Quantized inference on a single NVIDIA A100 achieves latency comparable to a 13 B dense model, confirming the cost‑efficiency promise of the factory.
6. Illustration of the Model Factory
The diagram below visualizes the full pipeline, from data ingestion to quantized deployment.
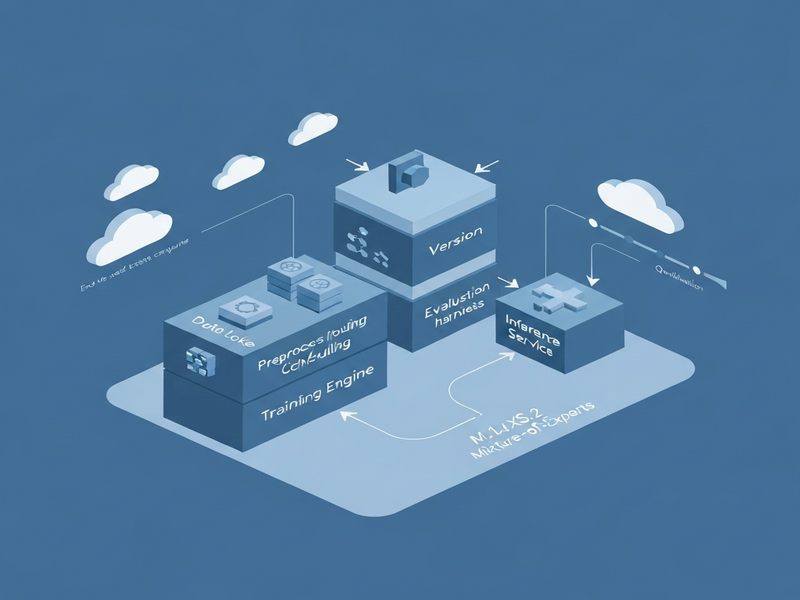
7. Conclusion and Future Work
Laguna M.1 and Laguna XS.2 demonstrate that a well‑engineered MoE architecture, coupled with a reproducible Model Factory, can deliver enterprise‑grade coding agents without the prohibitive costs of massive dense models. For developers, this means:
- Scalable performance that fits both cloud‑native and on‑premise budgets.
- A reproducible pipeline that eliminates the “research‑to‑production” gap.
- Open‑source accessibility via the Apache 2.0‑licensed Laguna XS.2, ideal for SMBs and startups.
- Seamless integration with UBOS’s ecosystem, such as the Enterprise AI platform by UBOS for governance and scaling.
Future research directions include expanding multilingual coverage, enabling dynamic expert addition, and tightening safety through RLHF focused on secure coding patterns. Moreover, building plug‑and‑play connectors for popular IDEs will accelerate adoption; the UBOS templates for quick start already provide starter projects that can be extended with Laguna‑powered agents.
Developers interested in hands‑on experimentation can download the 33 B Laguna XS.2 checkpoint from the official Hugging Face collection. The release bundles model cards, inference scripts, and a Dockerfile that integrates directly with the UBOS platform overview, enabling rapid prototyping of AI‑driven software development assistants.
For a deeper technical dive, consult the full technical report on arXiv: Laguna M.1/XS.2 Technical Report.
Explore Related UBOS Capabilities
- UBOS homepage
- AI marketing agents
- UBOS partner program
- Web app editor on UBOS
- UBOS pricing plans
- UBOS portfolio examples
- Telegram integration on UBOS
- ChatGPT and Telegram integration
- OpenAI ChatGPT integration
- ElevenLabs AI voice integration
- AI SEO Analyzer
- AI Article Copywriter
- AI Video Generator
- AI Chatbot template
- Customer Support with ChatGPT API
- Multi-language AI Translator
- Translate Natural Language to SQL
- Grammar Correction AI
- Python Bug Fixer AI
- AI Image Generator