
- Updated: June 15, 2026
- 6 min read
LACUNA: Safe Agents as Recursive Program Holes
Direct Answer
LACUNA introduces a programming model that lets large‑language‑model (LLM) agents fill typed “holes” in a host runtime with generated code, while a static type‑checker guarantees safety before execution. By treating each agent action as a compile‑time‑checked unit, LACUNA preserves the expressive power of code‑generating agents without exposing the system to the classic injection and inconsistency failures that have plagued earlier designs.
Background: Why This Problem Is Hard
Modern LLM agents often operate in a two‑stage loop: a runtime orchestrates the interaction (prompting, tool selection, result aggregation) and the model emits snippets of code that perform the next step. This split creates a hidden dependency chain. The runtime owns the control flow, but the model‑generated code can silently diverge, call the wrong tool, or leave the environment in a partially updated state. Prompt‑injection attacks, tool‑misuse, and incomplete roll‑backs are concrete failure modes that become amplified when the generated code can reshape the runtime itself.
Existing approaches mitigate risk by sandboxing the model’s output, limiting it to single‑action APIs, or manually reviewing generated scripts. While these safeguards reduce exposure, they also cripple the agent’s ability to compose complex, multi‑step plans, parallelize work, or dynamically create sub‑agents. The core tension is therefore between expressiveness (letting the model drive the program) and safety (preventing the model from corrupting the host).
What the Researchers Propose
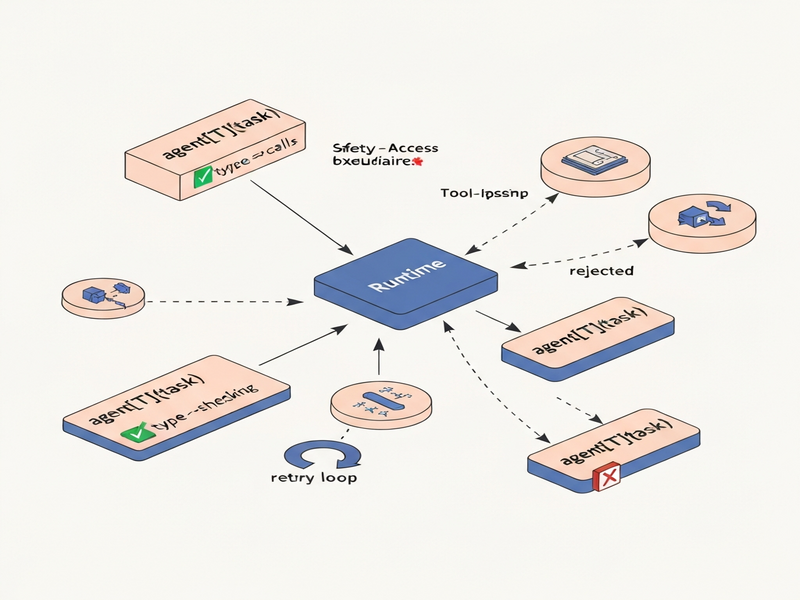
The LACUNA framework reframes every agent interaction as a typed function call of the form agent[T](task). When execution reaches such a call, the LLM is asked to fill the hole with concrete code that satisfies the declared return type T. Before the code runs, a conventional type‑checker validates it against the surrounding program, ensuring that:
- All referenced tools and data sources are permitted by the type signature.
- The generated fragment respects the runtime’s invariants (e.g., no stray side‑effects).
- Any type errors are reported back to the LLM, which can retry with a corrected implementation.
Because the check happens atomically, a rejected hole leaves the environment untouched, eliminating partial updates. The same type system also serves as a policy language, bounding which external APIs the agent may invoke and how data may flow between calls.
How It Works in Practice
At a high level, a LACUNA‑enabled agent follows this workflow:
- Task Decomposition: The runtime receives a user request and creates a top‑level
agenthole with a goal type (e.g.,Stringfor a summary). - Code Generation: The LLM fills the hole with a concrete program fragment—potentially a sequence of tool calls, conditional logic, or even nested
agentholes for sub‑tasks. - Static Validation: The host compiler type‑checks the fragment. If the fragment violates the declared type or policy, diagnostics are sent back to the model.
- Retry Loop: The model receives the diagnostics and attempts a new fill. This loop continues until the fragment type‑checks or a maximum retry budget is exhausted.
- Execution: A successfully validated fragment runs inside a sandboxed environment. Its result is returned to the caller, possibly satisfying the original request or spawning further holes.
This pattern can express classic ReAct loops (reason‑act‑observe), hierarchical sub‑agents, skill libraries, parallel decomposition, and multi‑model planning—all without special‑case code in the runtime. The key differentiator is that safety is enforced *before* any side‑effects occur, and the runtime never relinquishes control of the loop.
Evaluation & Results
The authors benchmarked LACUNA on two suites:
BrowseComp‑Plus
BrowseComp‑Plus is a web‑navigation benchmark that requires agents to locate, extract, and synthesize information from live pages. LACUNA rejected 8.6 % of generated fragments before execution, prompting an average of 0.7 retries per query. Despite the extra safety checks, the agent achieved a 27.1 % overall accuracy—comparable to state‑of‑the‑art baselines that run unchecked code.
τ²‑bench
τ²‑bench comprises 392 tasks across four domains (e.g., data wrangling, API orchestration, planning). With a capable LLM, LACUNA solved 76.0 % of the tasks, matching the performance of a strong baseline agent that does not enforce pre‑execution type safety. The results demonstrate that the safety layer does not materially degrade capability while providing deterministic failure handling.
Collectively, the experiments show that LACUNA can preserve or even improve success rates in realistic agent workloads, all while guaranteeing that no malformed code ever touches the live environment.
Why This Matters for AI Systems and Agents
For practitioners building production‑grade AI agents, LACUNA offers a concrete pathway to combine the flexibility of code‑generating LLMs with the reliability expectations of enterprise software. By making safety a compile‑time concern, developers can:
- Enforce fine‑grained tool access policies without writing custom guards for each model output.
- Guarantee that partial failures never corrupt shared state, simplifying debugging and observability.
- Reuse existing static analysis pipelines (e.g., linters, type checkers) to audit generated code automatically.
- Scale agent orchestration across teams, since each
agenthole is a well‑defined contract that can be versioned and audited.
These capabilities align directly with the needs of Enterprise AI platform by UBOS, where safety and compliance are non‑negotiable. Moreover, the typed‑hole abstraction can be layered on top of existing workflow engines, enabling “no‑code” AI assistants that still respect corporate governance.
What Comes Next
While LACUNA establishes a solid safety foundation, several open challenges remain:
- Dynamic Policy Evolution: Current type signatures are static; future work could explore runtime‑adjustable policies that react to emerging threats.
- Cross‑Model Coordination: The framework supports multi‑model planning, but efficient scheduling and cost‑aware selection of models are still nascent.
- Human‑in‑the‑Loop Feedback: Integrating real‑time user corrections into the retry loop could reduce the number of automated retries.
- Formal Verification: Extending the type system with richer contracts (e.g., temporal logic) would enable provable guarantees about long‑running agent behaviors.
Addressing these directions will broaden LACUNA’s applicability to domains such as autonomous robotics, regulated finance, and large‑scale knowledge bases. Developers interested in experimenting with typed agent holes can start by exploring the UBOS platform overview, which already supports plug‑in runtimes and custom type definitions.
For a deeper dive into the original research, see the LACUNA paper on arXiv.