- Updated: June 29, 2026
- 6 min read
IPO Finance Agent: Evaluation of LLM Financial Analysts beyond Finance Agent v2, with Automated Rubric Generation — the Case of the SpaceX (SPCX) IPO
Direct Answer
The paper introduces the IPO Finance Agent, an extended evaluation framework that equips large language models (LLMs) to act as financial analysts for initial public offering (IPO) due‑diligence tasks. By combining contextual retrieval for long SEC S‑1 filings with an automated rubric‑generation pipeline, the authors demonstrate that cost‑efficient LLMs can answer complex IPO questions more accurately than the prior Finance Agent v2 benchmark.
Background: Why This Problem Is Hard
IPO due‑diligence sits at the intersection of deep financial analysis, regulatory compliance, and narrative storytelling. Unlike quarterly 10‑K or 10‑Q reports, an SEC S‑1 filing can exceed 200 pages and weaves together:
- Historical audited statements and pro‑forma projections.
- Governance disclosures, risk factors, and underwriting terms.
- Common‑control accounting treatments that require expert interpretation.
Traditional LLM‑based finance agents, such as Finance Agent v2, rely on naive chunk‑based retrieval that assumes relatively short documents. When faced with the sheer length and structural complexity of an S‑1, these agents either miss critical sections or hallucinate facts because the retrieval window truncates essential context.
From an industry perspective, investment banks, venture capital firms, and corporate development teams spend weeks manually parsing S‑1s, building financial models, and drafting risk assessments. Automating even a fraction of this workflow would cut costs dramatically and accelerate capital‑raising cycles. Yet the technical bottleneck—efficiently surfacing the right paragraph from a massive filing and then reasoning over it—has remained unsolved.
What the Researchers Propose
The authors extend the Finance Agent v2 paradigm along two orthogonal axes:
- Domain Expansion: Shift the benchmark from periodic reporting to IPO due‑diligence, creating a new dataset of 1,000 questions that probe financial, legal, and strategic aspects of an S‑1 filing. A public subset of 70 SpaceX (SPCX) questions is released for reproducibility.
- Retrieval Architecture Upgrade: Replace naive chunking with a contextual retrieval pipeline that indexes the entire S‑1, performs relevance ranking, and dynamically stitches together multi‑paragraph evidence before feeding it to the LLM.
To evaluate model answers, the paper introduces an evaluator‑optimizer pipeline that automatically drafts rubrics. The pipeline extracts candidate facts from an ensemble of model responses, consolidates them into draft criteria, and then runs a series of LLM‑driven audits to prune hallucinations, fill omissions, and eliminate redundancy. Human experts only intervene at the final rubric‑approval stage, dramatically reducing manual labeling effort.
How It Works in Practice
Conceptual Workflow
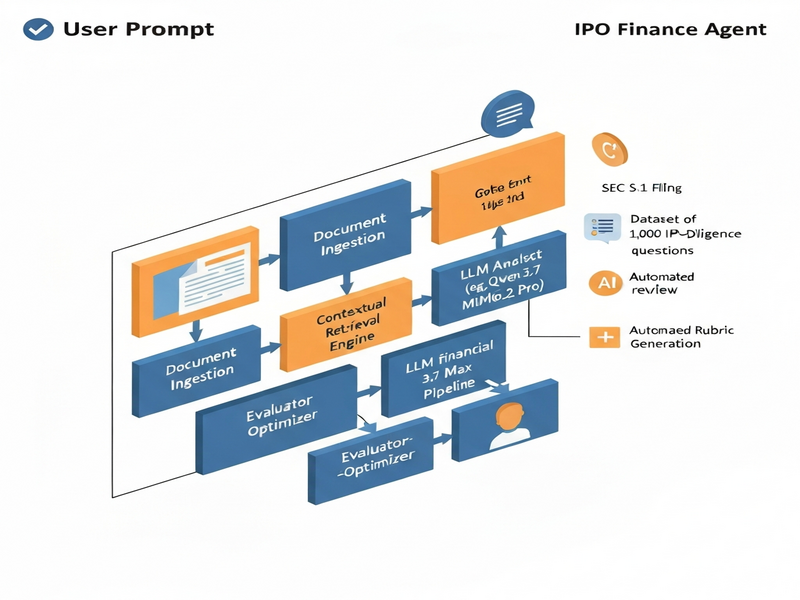
The IPO Finance Agent operates as a closed‑loop system composed of three logical layers:
- Document Ingestion & Indexing: The full SEC S‑1 is parsed into hierarchical sections (e.g., Business Overview, Financial Statements, Risk Factors). Each section is embedded using a dense vector model and stored in a vector database.
- Contextual Retrieval Engine: When a user poses a due‑diligence question, a lightweight retriever first selects the top‑k relevant sections. A second‑stage cross‑encoder re‑ranks these candidates, and the top passages are concatenated with a sliding‑window strategy to respect the LLM’s token limit.
- LLM Analyst & Rubric Generator: The retrieved context is fed to the target LLM (e.g., Qwen 3.7 Max, MiMo‑2.5 Pro). The model produces a concise answer, which is then passed to the rubric‑generation module. This module synthesizes evaluation criteria automatically, runs an LLM‑based audit, and outputs a final rubric that can be used for scoring.
Key Differentiators
- Length‑aware Retrieval: Unlike Finance Agent v2’s fixed‑size chunks, the new pipeline adapts to the variable length of S‑1 sections, ensuring that critical footnotes and tables are not dropped.
- Automated Rubric Creation: The evaluator‑optimizer eliminates the need for hand‑crafted scoring sheets, which are costly and often biased.
- Cost‑Efficiency Focus: By benchmarking models across a Pareto frontier of accuracy vs. per‑query cost, the study surfaces “budget‑friendly” LLMs that still meet enterprise‑grade performance.
Evaluation & Results
The authors benchmarked a suite of open‑source and commercial LLMs on the 70‑question SpaceX S‑1 subset. Evaluation metrics included:
- Answer accuracy (percentage of rubric‑approved facts).
- Per‑query monetary cost (derived from model pricing at the time of testing).
- Latency (average time from question to answer).
Key findings:
- Alibaba Qwen 3.7 Max achieved the highest accuracy at 79.4 % while costing $0.30 per query.
- Xiaomi MiMo‑2.5 Pro delivered a near‑top accuracy of 76.8 % at a dramatically lower cost of $0.05 per query, establishing the most cost‑effective point on the Pareto curve.
- Both models outperformed the previous Finance Agent v2 ceiling (Google Gemini 3.5 Flash at 57.9 % accuracy for $2.51 per query) and even beat the cheapest Finance Agent v2 entry (MiniMax M3 at 48.3 % for $0.32).
- Latency remained under 5 seconds for all tested models, confirming that the contextual retrieval overhead does not cripple real‑time usage.
These results demonstrate that, when paired with a robust retrieval layer and automated rubric generation, relatively inexpensive LLMs can rival or surpass premium offerings on complex financial tasks.
Why This Matters for AI Systems and Agents
For AI practitioners building enterprise‑grade agents, the IPO Finance Agent offers a blueprint for tackling “long‑document” challenges that are common across domains such as legal contract analysis, medical literature review, and policy compliance.
- Scalable Retrieval Integration: The contextual retrieval architecture can be plugged into existing agent frameworks, enabling them to handle documents an order of magnitude larger than before.
- Automated Evaluation Pipelines: The rubric‑generation workflow reduces the human‑in‑the‑loop burden, allowing teams to iterate rapidly on prompt engineering and model selection.
- Cost‑Driven Model Selection: By visualizing accuracy vs. cost, product managers can make data‑backed decisions about which LLM tier to deploy for a given SLA.
These capabilities align directly with the needs of modern AI‑enabled finance platforms, where compliance, speed, and budget constraints intersect. For example, integrating the IPO Finance Agent into a UBOS platform overview could empower financial analysts to query S‑1 filings via a conversational UI, while the backend automatically selects the most cost‑effective model for each request.
What Comes Next
While the study marks a significant step forward, several open challenges remain:
- Generalization Across Industries: The current benchmark focuses on a single high‑profile IPO (SpaceX). Extending the dataset to biotech, fintech, and emerging‑market offerings will test the framework’s adaptability.
- Multi‑Modal Evidence: S‑1 filings often embed tables, charts, and footnotes. Future work should incorporate OCR and table‑parsing modules to enrich the retrieval context.
- Dynamic Updates: IPO filings evolve during the roadshow process. A real‑time sync mechanism would keep the vector index fresh, ensuring agents answer with the latest disclosures.
Potential applications beyond finance include:
- Regulatory compliance bots for ESG reporting.
- Academic literature assistants that navigate multi‑gigabyte research corpora.
- Legal counsel agents that parse lengthy contracts and summarize risk clauses.
Developers interested in building such agents can explore the Workflow automation studio to orchestrate retrieval, LLM inference, and rubric generation as modular steps. For teams seeking to add conversational front‑ends, the ChatGPT and Telegram integration provides a low‑friction channel for end‑users to ask due‑diligence questions from their mobile devices.
References