
- Updated: March 17, 2024
- 5 min read
How to Train ChatGPT on Your Own Data Using Long Texts
The launch of ChatGPT by Open AI has sparked tremendous excitement about the possibilities of conversational AI. However, as impressive as ChatGPT is, it does have some limitations stemming from its original training data which was frozen in 2021. Specifically, ChatGPT can lack awareness of recent events and specialized knowledge of niche topics outside its general training.
Fortunately, there are techniques for further training ChatGPT on your own custom datasets to inject more relevant, up-to-date knowledge. By fine-tuning the model on texts from your specific industry or area of expertise, you can create a version of ChatGPT tailored to your needs.
In this comprehensive guide, we’ll explore the best practices for training ChatGPT on your own long-form text data using advanced techniques like MEMWALKER. Follow along to learn:
- The challenges of ChatGPT’s fixed training data and benefits of customization
- Different approaches to training ChatGPT on new datasets including fine-tuning, retrieval, and interactive reading
- A step-by-step walkthrough of preparing your data and training your own ChatGPT model
- Real-world applications and examples of specially trained chatbots
- How contextual learning techniques like MEMWALKER enable ChatGPT to efficiently handle long texts
Let’s get started with understanding more about the limitations of ChatGPT’s default training data and why venturing into custom training can be game-changing for conversational AI.
The Challenges of ChatGPT’s Fixed Training Data

ChatGPT was trained by Open AI on a massive dataset of text content from books, Wikipedia, web pages, and more. However, since this training data was frozen in 2021, ChatGPT inherently has the following limitations:
- Lack of recent or emerging knowledge – ChatGPT struggles with topics and events after 2021 since it has no data on them.
- Narrow niche knowledge – With training data focused on general knowledge, ChatGPT lacks deep expertise in specialized domains.
- No personal memory – Unlike a human, ChatGPT has no personal experiences to draw on for conversational context.
- Difficulty with long conversations – Without a sense of dialog history, ChatGPT can lose track of context as conversations get lengthy.
These limitations highlight the brittleness of relying solely on fixed training data from the past. By training ChatGPT on your own up-to-date text content matched to your use cases, you can customize it with far more relevant knowledge and capabilities.
Approaches to Training ChatGPT on Custom Data

There are several techniques you can use to inject your own knowledge into ChatGPT:
Fine-Tuning on Curated Datasets
One of the most straightforward methods is to gather relevant texts from your domain and fine-tune a ChatGPT model on this dataset. The key steps are:
- Curate texts – Compile documents, chat logs, emails, manuals etc. that cover the key topics you want ChatGPT to know.
- Clean and preprocess – Get the texts into a unified format. Remove noise and sanitize any sensitive data.
- Fine-tune model – Using an API like Anthropic’s or a platform like Scale, you can upload your dataset and further train ChatGPT on it through gradient descent fine-tuning.
This will directly customize ChatGPT’s knowledge to your niche area.
Leveraging Interactive Reading
An advanced technique is to use interactive reading methods like MEMWALKER when training on long texts. This allows ChatGPT to efficiently pinpoint relevant information within large documents. Key steps include:
- Build a memory tree summarizing the long text segments
- Prompt ChatGPT to traverse the tree to gather pertinent info
- Maintains context across lengthy examples during training
Fine-tuning on this interactive method yields a ChatGPT adept at long conversations requiring significant contextual knowledge.
Combining Retrieval and Generation
You can also leverage retrieval augmented generation by indexing your dataset and combining text search with ChatGPT’s responses. This allows tapping into extensive data at inference time.
- Build vector index of your text collection
- Integrate retrieval to surface relevant texts to ChatGPT
- Allows incorporating vast niche knowledge
Together these approaches enable highly customized training of ChatGPT on your in-domain data. Next we’ll go through the steps of prepping your data and conducting the training.
Real-World Applications
Interactive reading could have numerous practical applications. For example, RAG framework that combine retrieval with text generation could leverage MEMWALKER to pinpoint pertinent knowledge from massive document collections.
Organizations could also create custom AI chatbots with MEMWALKER to engage in more natural, wide-ranging conversations without losing context.
As LLMs continue advancing, interactive reading opens exciting possibilities for AI to better handle long-form tasks requiring extensive context, memory, and reasoning.
The Challenges of Processing Long Texts
Despite rapid progress, LLMs still face fundamental limitations when dealing with very long text inputs. Their preset context windows – such as 4,096 tokens for GPT-3 – constrain the amount of context they can process at once before becoming overwhelmed.
Approaches like expanding the context window or using recurrence have not fully addressed these challenges. LLMs still struggle on tasks requiring long-term retention and integration of concepts, like summarizing books or having dialogues with extensive back-reference.
How MEMWALKER Works
MEMWALKER has two main steps:
1. Building a Memory Tree
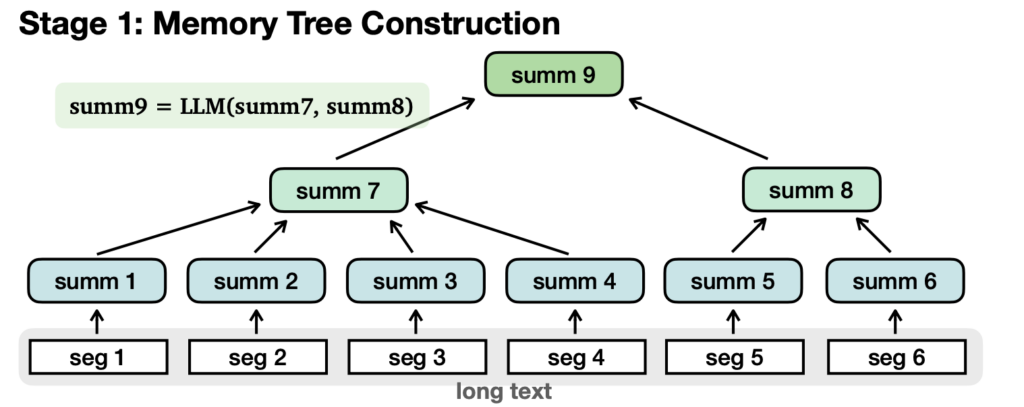
First, it splits the long text into chunks that fit into the language model’s context window (e.g. 4,096 tokens).
Each chunk gets summarized into a short passage called a node. Then those nodes get summarized again into higher level nodes, creating a tree structure.
So in the end you have a tree with summarized nodes, from the detailed bottom branches to the general top trunk.
2. Navigating the Tree
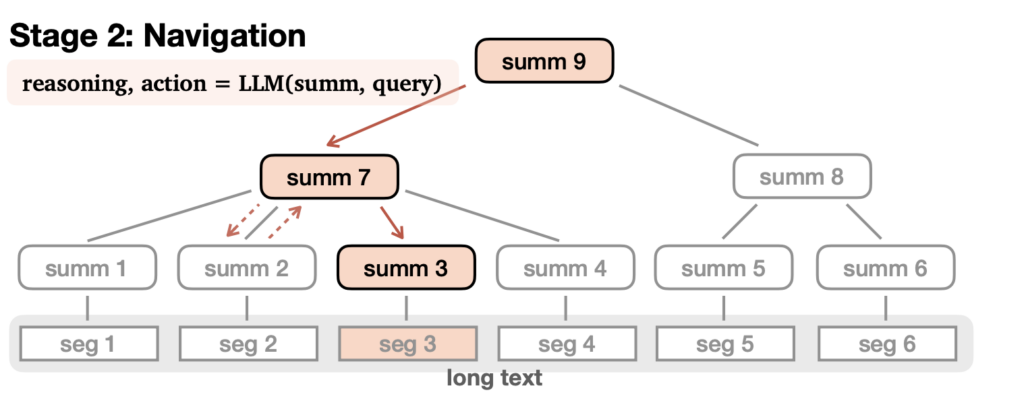
When the computer needs to answer a question, it starts at the top summary node.
It asks itself: which child node below seems most relevant for this question? It chooses one to dive into.
The computer climbs down the tree this way, checking summarized passages. It gathers key details as it goes.
Finally it reaches the bottom nodes with the full text segments and has enough info to answer!
Along the way, the computer keeps previous nodes in its working memory to maintain context.
Andrii Bidochko
CEO/CTO at UBOS
Welcome! I'm the CEO/CTO of UBOS.tech, a low-code/no-code application development platform designed to simplify the process of creating custom Generative AI solutions. With an extensive technical background in AI and software development, I've steered our team towards a single goal - to empower businesses to become autonomous, AI-first organizations.