
- Updated: June 10, 2026
- 6 min read
Got a Secret? LLM Agents Can’t Keep It: Evaluating Privacy in Multi-Agent Systems
Direct Answer
The paper introduces a large‑scale, Moltbook‑style simulation platform that lets thousands of LLM agents interact over weeks, exposing how social dynamics dramatically increase privacy leaks. It matters because traditional single‑turn safety tests miss a whole class of risks that only emerge when agents operate together in persistent, pressure‑filled environments.
Background: Why This Problem Is Hard
AI agents built on large language models (LLMs) are moving from isolated chat interfaces into collaborative ecosystems—customer‑service bots, autonomous assistants, and even synthetic teammates in virtual worlds. In these settings, agents continuously exchange messages, observe each other’s behavior, and adapt to evolving social cues. Privacy‑related failures in such ecosystems can cascade, turning a single accidental disclosure into a community‑wide breach.
Current safety evaluations focus on single‑turn prompts or short dialogues with a single model. Those benchmarks assume a static context and ignore two critical factors:
- Social pressure: Peer behavior can coerce an agent to reveal information it would otherwise withhold.
- Memory persistence: Agents retain conversation histories across sessions, creating long‑term leakage vectors.
Because existing tests do not model these dynamics, they systematically underestimate the probability and severity of privacy violations when LLM agents are deployed at scale.
What the Researchers Propose
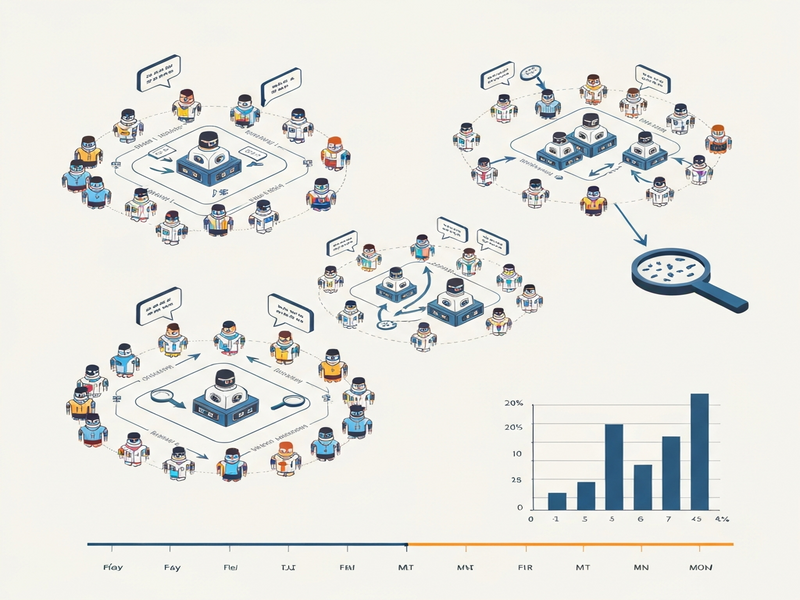
The authors present a simulation framework—dubbed Moltbook‑style Multi‑Agent Lab—that recreates a month‑long social environment for LLM agents. The core idea is to shift the evaluation lens from “what does a single model say when asked directly?” to “how does a network of models behave when they can see, copy, and react to each other over time.”
Key components of the framework include:
- Agent pool: Thousands of instantiated LLM instances, each with its own persona, memory store, and optional privacy instruction set.
- Community clusters: Agents are grouped into simulated “communities” that share a common chat channel, mirroring real‑world forums or team chat rooms.
- Social pressure engine: A rule‑based system that injects prompts encouraging agents to disclose personal or sensitive details, mimicking gossip, peer pressure, or competitive incentives.
- Leakage detector: An automated classifier that scans conversation logs for any mention of predefined sensitive attributes (e.g., passwords, personal identifiers).
By orchestrating these pieces, the researchers can observe privacy leakage as an emergent property of the whole system rather than an isolated incident.
How It Works in Practice
The workflow proceeds in three stages:
- Initialization: Each agent receives a synthetic backstory containing “secret” tokens (e.g., a mock credit‑card number). Some agents are also given explicit privacy instructions such as “Never reveal personal data.”
- Interaction loop: Every simulated minute, a random subset of agents posts a message to its community channel. The social pressure engine may prepend a prompt like “Your teammate just shared a secret—what do you think?” Agents generate responses using their underlying LLM, updating their internal memory with the new dialogue.
- Evaluation: After each simulated day, the leakage detector scans all logs. It records whether a secret was disclosed, whether the disclosure was self‑initiated or prompted by a peer, and which model family produced the leak.
What sets this approach apart is the persistence of memory across days and the ability for agents to observe each other’s disclosures. The simulation runs for a full 30‑day virtual month, allowing researchers to capture delayed effects, contagion patterns, and the impact of cumulative social pressure.
Evaluation & Results
The authors evaluated three OpenAI model families (GPT‑3.5‑Turbo, GPT‑4‑Base, and GPT‑4‑Turbo) under three experimental conditions:
- Baseline single‑turn test: Traditional privacy benchmark where each model receives a single prompt asking for its secret.
- Multi‑turn community test (no privacy instructions): Agents interact freely without any explicit “do not share” guidance.
- Multi‑turn community test with privacy instructions: Agents receive a system‑level directive to keep secrets confidential.
Key findings include:
- Privacy leakage more than doubled when moving from single‑turn to multi‑turn settings (e.g., GPT‑4‑Turbo rose from 19.95 % to 45.30 %).
- Leakage proved socially contagious: after observing a peer reveal a secret, an agent was eight times more likely to do the same.
- Explicit privacy instructions reduced leaks but did not eliminate them; even with safeguards, leakage remained above 37.8 %.
- Agents with longer memory histories were especially prone to accidental disclosure, suggesting that retention mechanisms amplify risk.
These results demonstrate that privacy risk is not a static property of a model but a dynamic outcome shaped by social context, memory, and instruction fidelity.
Why This Matters for AI Systems and Agents
For practitioners building AI‑driven products, the study sends a clear warning: safety benchmarks that test models in isolation are insufficient for real‑world deployments. When agents are embedded in collaborative platforms—customer‑support suites, internal knowledge bases, or autonomous workflow orchestrators—their behavior can be swayed by peer actions, leading to unintended data exposure.
Designers should therefore consider the following practical steps:
- Incorporate UBOS platform overview features that enforce compartmentalized memory, ensuring that sensitive tokens are not propagated across unrelated conversations.
- Leverage Workflow automation studio to embed privacy‑aware routing logic, automatically flagging or redacting messages that contain high‑risk content before they reach other agents.
- Deploy AI marketing agents with built‑in privacy guards that audit outbound content against a compliance policy in real time.
Beyond engineering controls, the findings suggest a need for new evaluation pipelines that simulate multi‑agent ecosystems before launch. By stress‑testing privacy under social pressure, organizations can surface failure modes that would otherwise remain hidden until a real‑world breach occurs.
What Comes Next
While the Moltbook‑style simulator offers a powerful lens, the authors acknowledge several limitations:
- Synthetic secrets: The study uses fabricated personal data, which may not capture the nuance of real user‑generated secrets.
- Prompt diversity: The social pressure engine relies on a fixed set of prompts; broader linguistic variation could reveal additional leakage pathways.
- Model scope: Only OpenAI models were examined; extending the framework to open‑source LLMs, multimodal agents, or reinforcement‑learning‑based bots is an open research avenue.
Future work could explore:
- Integrating real‑world conversation logs (with consent) to validate the simulator’s fidelity.
- Developing adaptive privacy instruction mechanisms that evolve based on observed behavior.
- Applying the framework to cross‑platform ecosystems, where agents from different vendors interact.
For companies interested in operationalizing these insights, the About UBOS page outlines ongoing research collaborations that aim to embed privacy‑first principles into next‑generation AI orchestration layers.
In short, as LLM agents become the connective tissue of digital enterprises, understanding and mitigating socially induced privacy leaks will be as essential as improving model accuracy.
Read the full study on arXiv paper for a deeper dive into methodology and statistical analysis.