
- Updated: June 24, 2026
- 6 min read
Fara-1.5: Scalable Learning Environments for Computer Use Agents
Direct Answer
Fara‑1.5 introduces a modular, scalable pipeline—FaraGen1.5—that automatically generates high‑quality computer‑use demonstrations for training native computer‑use agents (CUAs). By coupling live web environments, synthetic sandboxes, multi‑model solvers, and three complementary verifiers, the system produces data that lets agents of 4 B, 9 B, and 27 B parameters achieve state‑of‑the‑art performance on demanding browser‑automation benchmarks.
Background: Why This Problem Is Hard
Training agents that can reliably interact with graphical user interfaces (GUIs) and web browsers has long been bottlenecked by data scarcity. Human‑generated demonstrations are expensive, slow to collect, and often incomplete—especially for tasks that require authentication, irreversible actions, or multi‑step reasoning. Existing pipelines typically rely on:
- Static datasets scraped from public tutorials, which miss edge‑case flows.
- Manual annotation pipelines that cannot keep pace with the rapid evolution of web services.
- Single‑model solvers that struggle with complex, multi‑turn interactions, leading to low‑quality trajectories.
These limitations manifest as poor generalization, brittle error handling, and an inability to scale training data to the billions of steps modern foundation models demand. As enterprises look to embed AI agents in customer‑support bots, internal tooling, and autonomous browsing assistants, the need for a reproducible, high‑throughput data generation framework becomes critical.
What the Researchers Propose
The authors present FaraGen1.5, a three‑layered pipeline that decouples environment simulation, solution generation, and outcome verification. The core idea is to treat each component as a plug‑and‑play module, allowing the system to:
- Environments: Run tasks on both live websites (preserving real‑world dynamics) and synthetic replicas that faithfully emulate authentication flows, payment gateways, or irreversible state changes.
- Solvers: Harness a harness that can invoke multiple language models—including frontier models such as GPT‑5.4—while also supporting a lightweight user‑simulator for multi‑turn rollouts.
- Verifiers: Apply three orthogonal checks—task correctness, efficiency (step count), and critical‑point adherence (e.g., respecting login tokens)—to score each trajectory.
By separating concerns, the pipeline can iterate rapidly: new solvers can be swapped in without re‑engineering the environment, and verifiers can be tuned to prioritize safety or speed depending on downstream deployment constraints.
How It Works in Practice
The end‑to‑end workflow follows a clear, repeatable sequence:
- Task Specification: A high‑level description (e.g., “book a flight on AirlineX”) is fed into the system.
- Environment Instantiation: The pipeline selects either a live site or spins up a synthetic clone that mirrors the target domain’s UI and backend constraints.
- Solver Invocation: The solver harness queries one or more LLMs to propose an action sequence. If the task requires multi‑turn interaction, the user‑simulator feeds the model’s intermediate outputs back as observations.
- Trajectory Generation: The proposed actions are executed step‑by‑step in the chosen environment, producing a raw demonstration trace.
- Verification Pass: Three verifiers independently assess the trace:
- Correctness Verifier: Checks whether the final state matches the task goal.
- Efficiency Verifier: Measures unnecessary clicks or redundant navigation.
- Critical‑Point Verifier: Ensures that sensitive operations (e.g., password entry) follow security best practices.
- Scoring & Curation: Trajectories receive a composite score; high‑scoring examples are added to the training corpus, while low‑scoring ones trigger a feedback loop to improve the solver.
The following diagram (illustrated by the included image) visualizes the modular flow:
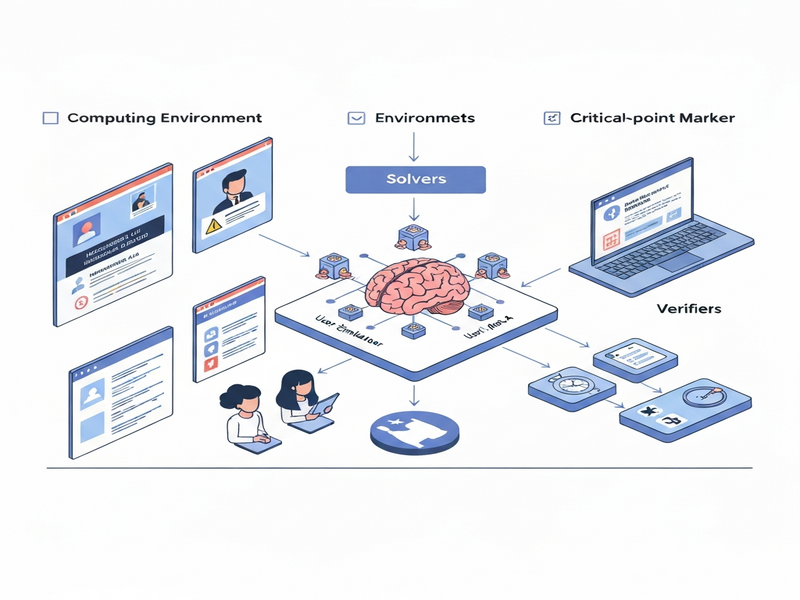
What distinguishes FaraGen1.5 from prior data generators is its ability to blend authentic web interactions with safe, reproducible synthetic environments, all while leveraging a multi‑model solver stack that can be upgraded as newer LLMs become available.
Evaluation & Results
To validate the pipeline, the researchers trained three variants of the Fara‑1.5 agent family on the Qwen3.5 backbone (4 B, 9 B, and 27 B parameters). The evaluation focused on two widely‑cited browser‑automation benchmarks:
- Online‑Mind2Web: A suite of 1,000 multi‑step web tasks ranging from form filling to complex navigation.
- WebVoyager: A harder set emphasizing long‑horizon planning and dynamic content handling.
Key findings include:
- The 9 B model achieved 63.4 % success on Online‑Mind2Web and 86.6 % on WebVoyager, surpassing all prior open‑source agents of comparable size.
<li The 27 B variant reached 72.3 % on Online‑Mind2Web, a performance level previously only reported by proprietary systems with 50 B+ parameters.
<li Ablation studies showed that removing the synthetic environment component dropped success rates by up to 12 %, confirming its role in covering edge cases.
<li Introducing the three‑verifier scoring scheme improved data quality, leading to a 5‑7 % lift in downstream task accuracy compared to a single‑verifier baseline.
These results demonstrate that a well‑engineered data pipeline can close the gap between modest‑scale models and massive proprietary systems, offering a cost‑effective path for enterprises to deploy capable CUAs.
For a deeper dive into the methodology and raw numbers, see the Fara‑1.5 paper.
Why This Matters for AI Systems and Agents
From a practitioner’s perspective, FaraGen1.5 reshapes three core aspects of agent development:
- Data Scalability: By automating the generation of high‑fidelity demonstrations, teams can amass millions of training steps without hiring large annotation crews.
- Safety & Compliance: The multi‑verifier architecture enforces security constraints (e.g., proper handling of credentials) at data‑creation time, reducing downstream risk.
- Model Agnosticism: Because solvers are interchangeable, organizations can experiment with emerging LLMs—such as GPT‑5.4 or open‑source alternatives—without redesigning the entire pipeline.
These capabilities align directly with the needs of modern AI‑driven enterprises that require:
- Rapid iteration on internal workflow automation (Workflow automation studio).
- Integration of agents into existing communication channels, like Telegram bots or ChatGPT extensions (ChatGPT and Telegram integration).
- Secure handling of proprietary data through vetted synthetic environments.
In short, the pipeline offers a reproducible foundation for building production‑grade CUAs that can be deployed across SaaS platforms, internal tooling, and customer‑facing bots.
What Comes Next
While FaraGen1.5 marks a significant leap, several open challenges remain:
- Domain Generalization: Extending synthetic environment generators to cover niche enterprise software (e.g., ERP systems) will require tighter coupling with internal APIs.
- Real‑Time Adaptation: Current solvers operate in a batch mode; integrating online reinforcement signals could enable agents to self‑correct during live deployments.
- Evaluation Diversity: Benchmarks like Online‑Mind2Web focus on web tasks; future work should incorporate desktop GUI, mobile app, and multimodal interactions.
Future research directions include:
- Developing a meta‑solver that dynamically selects the best LLM for each sub‑task based on cost‑performance trade‑offs.
- Embedding privacy‑preserving synthetic data generators that can mimic proprietary UI flows without exposing real user data.
- Creating a community‑driven repository of verified synthetic environments, akin to model zoos, to accelerate cross‑organization collaboration.
Enterprises interested in adopting this approach can explore the Enterprise AI platform by UBOS, which already supports modular agent pipelines, synthetic sandbox provisioning, and multi‑model orchestration out of the box.
As the ecosystem matures, the line between “data collection” and “model training” will blur, enabling a virtuous cycle where agents continuously generate, verify, and learn from their own interactions—paving the way for truly autonomous, trustworthy AI assistants.