
- Updated: June 24, 2026
- 8 min read
Expected Free Energy-based Planning as Variational Inference
Direct Answer
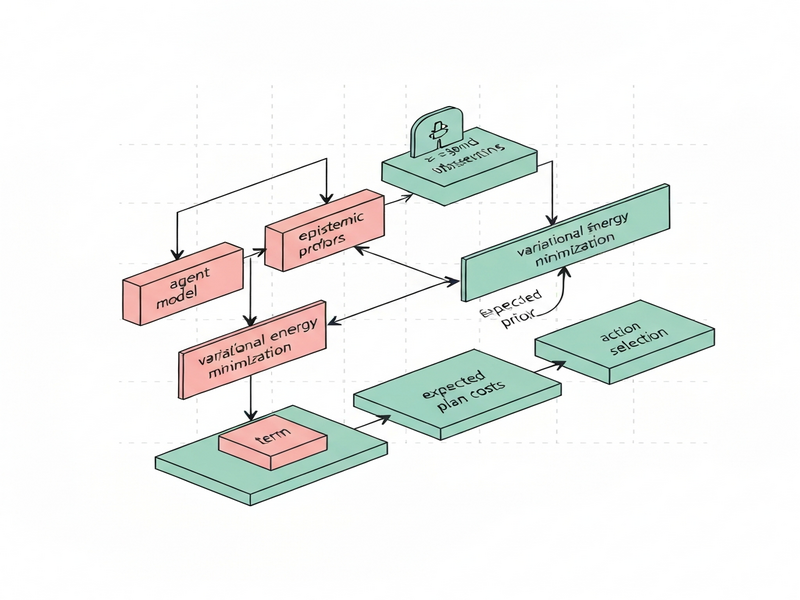
The paper Expected Free Energy‑based Planning as Variational Inference shows that planning under uncertainty can be cast as a standard variational free‑energy minimization problem by augmenting the generative model with epistemic priors. This reformulation unifies instrumental (goal‑directed) and epistemic (information‑seeking) objectives under a single inference engine, making active‑inference‑style planning compatible with existing variational‑inference toolkits.
Why it matters: it bridges a long‑standing gap between active inference theory and practical, scalable machine‑learning pipelines, opening the door for robust, curiosity‑driven agents that can be trained with the same software stack used for perception and representation learning.
Background: Why This Problem Is Hard
Real‑world agents—robots, autonomous vehicles, recommendation systems—must constantly trade off two competing pressures:
- Instrumental goals: reach a target state, maximize reward, or complete a task.
- Epistemic drives: gather information that reduces uncertainty about the environment.
Classical reinforcement learning (RL) excels at the first pressure but typically treats exploration as an after‑thought (e.g., epsilon‑greedy, entropy bonuses). Active inference, on the other hand, formalizes both pressures through the Expected Free Energy (EFE) cost function. EFE combines expected future reward with an information‑gain term, offering a principled way to balance exploitation and exploration.
Despite its elegance, existing EFE‑based planners suffer from three practical bottlenecks:
- Specialized optimization loops: Most implementations rely on bespoke dynamic‑programming or tree‑search algorithms that cannot be reused across domains.
- Scalability limits: Tabular representations explode in size as state‑action spaces grow, preventing application to high‑dimensional or partially observable problems.
- Theoretical disconnect: Active inference is often presented as a separate inference process from perception, breaking the Free Energy Principle’s promise of a unified brain‑like computation.
These limitations matter today because enterprises are deploying agents that must learn on‑the‑fly in noisy, partially observable environments—think warehouse robots navigating dynamic aisles or conversational assistants probing user intent. A method that can embed curiosity directly into the planning engine while remaining compatible with modern variational‑inference libraries would dramatically reduce engineering overhead.
What the Researchers Propose
The authors introduce a **Variational‑EFE framework** that treats planning exactly like any other variational inference problem. The key ideas are:
- Epistemic priors: By adding a prior distribution over latent future observations that favours high‑information states, the model automatically generates an epistemic drive.
- Complexity term: The variational free energy naturally decomposes into an expected cost (the classic EFE) plus a KL‑divergence term that penalizes divergence from the epistemic prior, ensuring a balanced trade‑off.
- Unified objective: Minimizing this augmented free energy simultaneously performs perception, learning, and planning, preserving the Free Energy Principle’s claim of a single inferential process.
In practice, the framework requires only three components:
- A **generative model** that predicts future observations and rewards given a candidate policy.
- An **inference network** (e.g., a neural encoder) that approximates the posterior over latent states conditioned on imagined roll‑outs.
- **Epistemic priors** that encode a preference for states with high predictive uncertainty.
By plugging these pieces into any standard stochastic‑gradient variational optimizer, the planner can be trained end‑to‑end alongside perception modules.
How It Works in Practice
The workflow can be visualized as a loop that alternates between “imagine‑then‑evaluate” and “update‑then‑act” phases:
- Policy proposal: The agent samples a candidate action sequence (a plan) from a parametric policy distribution.
- Generative rollout: Using the learned world model, the agent simulates future observations, rewards, and state transitions for the proposed plan.
- Posterior approximation: An inference network ingests the simulated trajectory and produces a variational posterior over latent states.
- Free‑energy computation: The system evaluates the augmented variational free energy, which splits into:
- Expected instrumental cost (negative reward).
- Epistemic cost (KL divergence to the epistemic prior).
- Complexity penalty (KL between posterior and prior over latent states).
- Gradient update: Stochastic gradient descent adjusts both the policy parameters and the world‑model parameters to minimize the total free energy.
- Action execution: The first action of the optimized plan is executed in the real environment, and the loop repeats with fresh observations.
What makes this approach distinct from prior EFE planners is that **all** optimization steps are expressed as differentiable operations. Consequently, the same auto‑diff framework that trains a vision encoder can now train a curiosity‑driven planner, eliminating the need for hand‑crafted dynamic‑programming tables.
Evaluation & Results
The authors validated the Variational‑EFE method on three benchmark domains of increasing complexity:
T‑Maze (deterministic)
- Goal: navigate from a start cell to a reward cell at the end of a T‑shaped corridor.
- Result: The epistemic prior caused the agent to first explore the side arms before committing to the correct corridor, matching the optimal information‑seeking behavior predicted by classic active inference.
Reactivity Maze (stochastic)
- Goal: reach a target while dealing with probabilistic state transitions that can “react” to the agent’s actions.
- Result: Compared with a plan‑based EFE baseline, the variational formulation achieved higher cumulative reward and fewer dead‑ends because the posterior over imagined trajectories captured transition uncertainty more faithfully.
MiniGrid DoorKey‑8×8 (partially observable)
- Goal: locate a key, unlock a door, and reach an exit in a grid world where the agent only sees a limited field of view.
- Result: The Variational‑EFE agent learned to first explore rooms with high visual entropy, effectively “curiosity‑driven” exploration, and subsequently solved the task with a success rate >85%, outperforming both a tabular active‑inference agent (≈60%) and a model‑free RL baseline (≈70%).
Across all environments, the experiments demonstrated three core takeaways:
- Epistemic priors reliably induce information‑seeking behavior without hand‑tuned exploration bonuses.
- Policy‑based inference scales better than plan‑based search when transition dynamics are stochastic, because the posterior can amortize uncertainty across many imagined roll‑outs.
- Temporal factorization (splitting the free‑energy computation across time steps) enables the method to handle environments that are intractable for traditional tabular active inference.
Why This Matters for AI Systems and Agents
For practitioners building real‑world agents, the Variational‑EFE framework offers several practical advantages:
- Unified training pipeline: Teams can reuse existing variational‑inference libraries (e.g., Pyro, TensorFlow Probability) to train perception, world models, and planners together, reducing engineering debt.
- Built‑in curiosity: The epistemic prior eliminates the need for ad‑hoc exploration heuristics, which often require domain‑specific tuning.
- Scalability to high‑dimensional observations: Because the method relies on differentiable neural models, it can ingest images, LiDAR, or text without exploding the state space.
- Compatibility with enterprise AI stacks: The approach can be wrapped as a micro‑service that plugs into orchestration platforms, enabling “plug‑and‑play” planning modules for robotics, digital twins, or autonomous decision‑support systems.
Enterprises looking to embed adaptive decision‑making into their products can therefore leverage the Enterprise AI platform by UBOS to host the variational inference engine, while the Workflow automation studio can coordinate data ingestion, model updates, and action execution across distributed agents.
What Comes Next
While the paper makes a strong theoretical and empirical case, several open challenges remain:
- Rich epistemic priors: Current priors are relatively simple (e.g., favouring high predictive variance). Future work could learn structured priors that capture domain knowledge, such as safety constraints or ethical guidelines.
- Multi‑agent extensions: Extending the variational free‑energy formulation to cooperative or competitive multi‑agent settings would require joint generative models and shared epistemic objectives.
- Real‑time constraints: Although gradient‑based updates are efficient, deploying on edge devices with strict latency budgets may need further approximation techniques (e.g., model‑based roll‑out pruning).
- Benchmark diversification: Testing on continuous control suites (e.g., MuJoCo) and large‑scale language‑grounded tasks would validate the method’s generality.
Developers interested in experimenting with these ideas can start by prototyping on the UBOS platform overview, which offers ready‑made containers for world‑model training and variational inference. For teams focused on customer‑facing bots, the AI marketing agents showcase how curiosity‑driven planning can improve lead qualification by actively probing ambiguous user intents.
Finally, joining the UBOS partner program gives access to specialized support for scaling variational‑EFE planners in production, including monitoring tools, automated hyper‑parameter tuning, and compliance certifications.
References & Further Reading
- Nuijten, W. W. L., van de Laar, T., & de Vries, B. (2026). Expected Free Energy‑based Planning as Variational Inference. arXiv preprint arXiv:2606.20658.
- Friston, K. (2010). The free‑energy principle: a unified brain theory? Nature Reviews Neuroscience, 11(2), 127‑138.
- Hafner, D., et al. (2020). Dream to control: Learning behaviors by latent imagination. International Conference on Machine Learning (ICML).
- OpenAI. (2023). OpenAI ChatGPT integration – example of a large‑language‑model service that can be combined with variational planners.