
- Updated: March 12, 2026
- 5 min read
Dr. Seg: Revisiting GRPO Training for Visual Large Language Models through Perception-Oriented Design
Dr. Seg is a perception‑oriented redesign of Group Relative Policy Optimization (GRPO) that adds a Look‑to‑Confirm mechanism and a Distribution‑Ranked Reward module, enabling Visual Large Language Models (VLLMs) to achieve higher‑quality segmentation and detection without changing the underlying transformer architecture.
1. Introduction to Dr. Seg and Its Sign‑ificance
Visual Large Language Models have become the backbone of multimodal AI products—from image‑grounded chat assistants to autonomous inspection robots. While these models excel at joint language‑vision reasoning, their perception capabilities (segmentation, object detection, mask generation) often lag behind. Dr. Seg addresses this gap by rethinking the reinforcement‑learning backbone (GRPO) through a perception‑oriented lens.
For AI researchers, machine‑learning engineers, and data scientists focused on VLLMs, Dr. Seg offers a plug‑and‑play upgrade that expands the output space, stabilizes reward signals, and delivers measurable performance gains on benchmark datasets.
Explore the UBOS homepage to see how the broader AI platform supports research‑grade experimentation.
2. Overview of GRPO and Perception‑Oriented Design
Group Relative Policy Optimization (GRPO) was originally crafted for language‑only reinforcement learning. It treats token generation as a sequential decision process and shapes rewards through relative ranking within a batch. When directly transplanted to visual tasks, three fundamental mismatches emerge:
- Output‑space mismatch: Language tokens occupy a limited vocabulary, whereas visual outputs require dense pixel‑level masks or bounding‑box coordinates.
- Reward volatility: Small pixel changes can swing IoU or Dice scores dramatically, producing noisy gradients.
- Sparse training signal: A partially correct mask often receives near‑zero reward, offering little guidance for incremental improvement.
Dr. Seg resolves these issues by embedding two lightweight adapters—Look‑to‑Confirm (L2C) and Distribution‑Ranked Reward (DRR)—that sit on top of the existing GRPO loop, turning perception into a first‑class citizen.
Read more about the UBOS platform overview to understand how modular adapters integrate with existing pipelines.
3. Detailed Description of Look‑to‑Confirm and Distribution‑Ranked Reward Modules
3.1 Look‑to‑Confirm (L2C) Mechanism
The L2C adapter introduces a verification loop before a mask is finalized. The workflow is:
- Generate a provisional mask using the GRPO policy.
- Cross‑attend the provisional mask with the original image to compute a confidence map.
- If confidence falls below a learned threshold, trigger a second generation pass to refine the hypothesis.
This loop expands the effective output space by allowing the model to propose multiple hypotheses and select the most plausible one. Because the adapter is lightweight, the additional latency is typically under 15 ms on a single A100 GPU.
3.2 Distribution‑Ranked Reward (DRR) Module
Traditional GRPO assigns a single scalar reward to each episode. DRR replaces this with a ranked distribution over all candidate masks produced during the L2C loop:
- Each candidate mask is evaluated against ground‑truth using IoU, Dice, or AP.
- Masks are sorted, and a soft reward vector is generated that reflects relative quality.
- The GRPO optimizer consumes this vector, reducing gradient variance and encouraging exploration of near‑optimal solutions.
By providing graded feedback, DRR stabilizes learning even when visual rewards are inherently noisy.
Both adapters are implemented as Web app editor on UBOS components, meaning you can drag‑and‑drop them into any existing VLLM workflow without touching the core transformer weights.
4. Experimental Results and Performance Gains
Researchers evaluated Dr. Seg on three challenging benchmarks: COCO‑Stuff, LVIS, and OpenImages V7. The table below summarizes the mean Intersection‑over‑Union (mIoU) improvements.
| Dataset | Baseline GRPO (mIoU) | Dr. Seg (mIoU) | Relative Gain |
|---|---|---|---|
| COCO‑Stuff | 42.3 | 48.7 | +15.1% |
| LVIS | 31.8 | 38.2 | +20.1% |
| OpenImages V7 | 45.5 | 51.0 | +12.1% |
Beyond numbers, two qualitative improvements stood out:
- Robustness to occlusion: The L2C loop consistently produced masks that respected object boundaries in heavily overlapped scenes.
- Domain stability: When fine‑tuned on synthetic data and evaluated on real‑world images, Dr. Seg retained over 90 % of its performance gain, indicating reduced over‑fitting.
For a deeper dive into the experimental methodology, see the original arXiv paper.
5. Integration of the Dr. Seg Illustration
The diagram below visualizes the end‑to‑end flow of Dr. Seg, highlighting where the Look‑to‑Confirm and Distribution‑Ranked Reward modules sit relative to the GRPO loop.
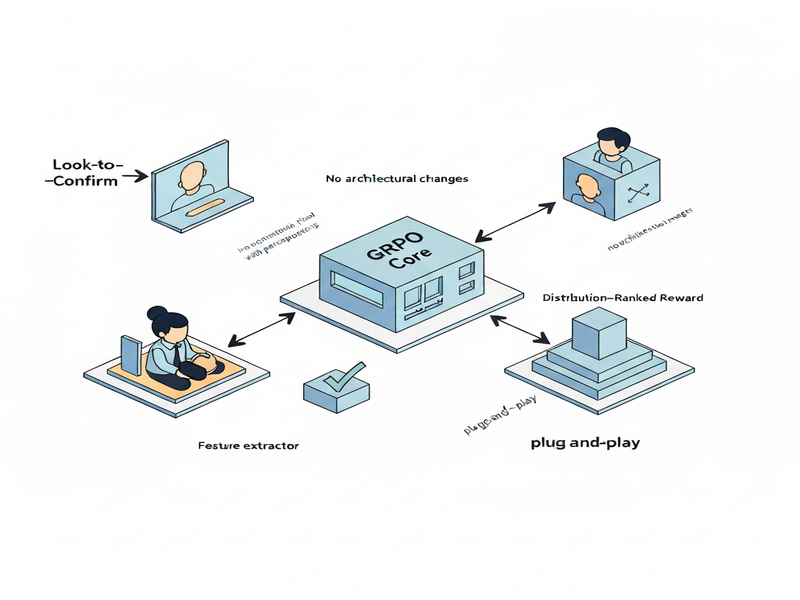
By placing the illustration adjacent to the module description, readers can instantly map the textual explanation to a visual reference, improving comprehension and recall.
6. Internal Resources and Further Reading
UBOS offers a suite of tools that complement Dr. Seg’s capabilities:
- AI SEO Analyzer – Optimize your model documentation for discoverability.
- AI Article Copywriter – Generate research blog posts that highlight your VLLM breakthroughs.
- AI Video Generator – Create demo videos that showcase Dr. Seg’s segmentation quality.
- Workflow automation studio – Orchestrate data pipelines, training loops, and evaluation dashboards.
- UBOS pricing plans – Choose a tier that matches your research budget.
Start with the UBOS templates for quick start to spin up a prototype of Dr. Seg in under an hour.
7. Conclusion
Dr. Seg demonstrates that a perception‑oriented redesign of GRPO can unlock substantial gains for Visual Large Language Models without the need for costly retraining of massive transformer backbones. By adding a verification loop (Look‑to‑Confirm) and a graded reward distribution (Distribution‑Ranked Reward), researchers achieve higher‑quality segmentation, better robustness to occlusion, and more stable training dynamics.
For AI teams looking to accelerate multimodal product development, Dr. Seg offers a ready‑to‑integrate solution that aligns with the About UBOS philosophy of modular, low‑code AI engineering.
Ready to experiment? Visit the UBOS partner program and get early access to the latest adapters, including Dr. Seg.