
- Updated: June 23, 2026
- 6 min read
DEMM-Bench: A Cross-Regime Benchmark for Agent‑Runtime Governance‑Evidence Sufficiency
Direct Answer
DEMM‑Bench is a cross‑regime benchmark that measures how well agent‑runtime evidence—traces, ledgers, provenance graphs, and related artifacts—supports the reconstruction of decision‑level properties. It matters because it provides the first systematic way to evaluate whether the data emitted by autonomous AI agents is sufficient for governance, compliance, and auditability across heterogeneous runtime environments.
Background: Why This Problem Is Hard
Modern AI agents operate in complex ecosystems: they invoke tools, delegate tasks, cache results, and interact with policy engines. Each interaction leaves a digital footprint—logs, tokens, provenance edges—but these footprints are often siloed, incomplete, or formatted for debugging rather than governance. Organizations that need to answer questions such as “Who authorized this action?” or “What policy justified the resource allocation?” face three intertwined challenges:
- Heterogeneity of evidence sources. Traces, ledgers, and policy logs differ in schema, granularity, and trust assumptions.
- Evidence relevance vs. presence. A log entry may exist (presence) but still lack the contextual detail required to infer a decision’s authority or verification strength.
- Regime‑specific degradation. Real‑world deployments experience data loss, redaction, or intentional obfuscation, which can cripple downstream audits.
Existing evaluation frameworks focus on surface‑level completeness—whether a trace file exists—without probing whether the evidence can answer concrete governance questions. Consequently, system designers lack a quantitative yardstick to compare runtime observability across platforms, and regulators have no common benchmark to demand evidence sufficiency.
What the Researchers Propose
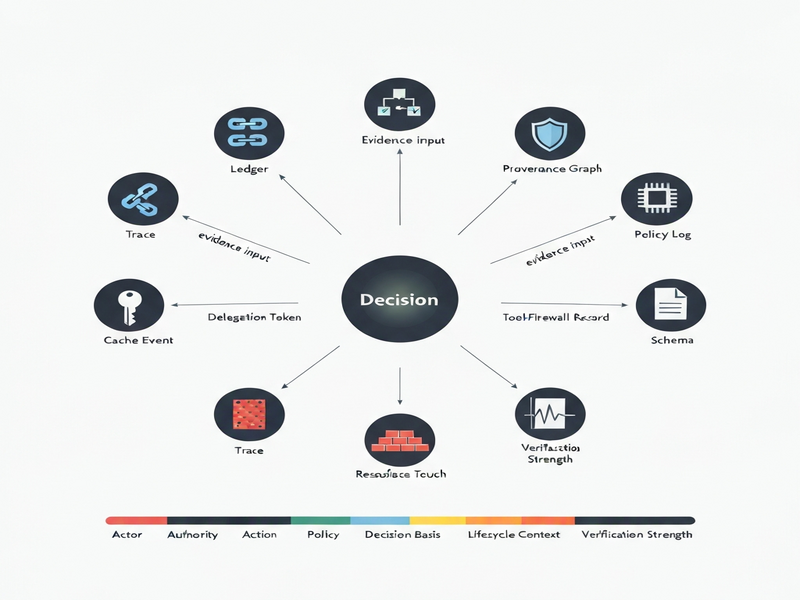
The authors introduce DEMM‑Bench, a benchmark grounded in the Decision Evidence Maturity Model (DEMM). DEMM defines eight evidence regimes (e.g., trace‑present, ledger‑present, schema‑present) and eight decision‑level properties (actor, authority, action, policy, decision basis, resource touch, lifecycle context, verification strength). DEMM‑Bench evaluates whether the combination of evidence across regimes can reconstruct each property without over‑claiming—i.e., without asserting a property that the evidence cannot substantiate.
Key components of the framework include:
- Adapters. Normalization layers that translate heterogeneous evidence formats into a common representation.
- Property‑level candidate scorer. An algorithm that attempts to infer each decision property from the normalized evidence.
- Deterministic degradation conditions. Eight systematic ways to corrupt or redact evidence (e.g., removing timestamps, anonymizing actors) to test robustness.
- Construction‑oracle labels. Human‑curated ground truth for 64 manuscript cases that define the correct property set for each decision.
By measuring “Property Sufficiency Accuracy” (the proportion of correctly inferred properties without over‑claim), DEMM‑Bench quantifies evidence maturity in a way that is comparable across platforms and runtime configurations.
How It Works in Practice
The practical workflow of DEMM‑Bench can be broken down into four stages:
- Evidence Collection. An agent‑runtime system emits its native artifacts—logs, provenance graphs, delegation tokens, cache events, etc.
- Adapter Normalization. Each artifact passes through a regime‑specific adapter that maps fields to a unified schema (e.g., mapping “user_id” in a trace to the canonical “actor” field).
- Property Scoring. The candidate scorer consumes the normalized evidence and attempts to answer the eight property questions. It produces a confidence score for each property and flags any inference that exceeds the evidence’s support.
- Evaluation under Degradation. The benchmark applies the eight deterministic degradation conditions to the evidence set, reruns the scorer, and records changes in property accuracy and over‑claim rates.
What distinguishes this approach from prior “trace‑presence” checks is the explicit separation of evidence presence from evidence sufficiency. Instead of a binary “trace exists?” test, DEMM‑Bench asks “Can the existing evidence answer this governance question?” and penalizes any answer that cannot be justified by the data.
Evaluation & Results
The authors evaluated DEMM‑Bench on a curated dataset of 64 manuscript cases drawn from real‑world AI agent deployments. Each case includes a full suite of evidence across the eight regimes, as well as oracle labels for the eight decision properties.
Three baseline configurations were compared against the property‑level candidate scorer:
- Trace‑present baseline. Assumes any available trace suffices for all properties.
- Schema‑present baseline. Relies on the existence of a data schema without inspecting actual records.
- Ledger‑present baseline. Treats a blockchain‑style ledger as fully sufficient.
Key findings:
- Both trace‑present and schema‑present baselines over‑claimed in 75 % of cases, demonstrating that mere presence is a poor proxy for governance readiness.
- The ledger‑present baseline over‑claimed in 50 % of cases, indicating that even immutable ledgers can lack contextual detail.
- The candidate scorer achieved a mean Property Sufficiency Accuracy of 56.25 % with zero over‑claims, proving that a disciplined, evidence‑aware approach can avoid false assurances.
- When deterministic degradations removed timestamps or anonymized actors, accuracy dropped predictably, confirming that the benchmark sensitively captures evidence loss.
These results validate DEMM‑Bench as a discriminating tool: it can differentiate between superficial evidence collections and truly governance‑ready data pipelines.
Why This Matters for AI Systems and Agents
For AI practitioners, DEMM‑Bench offers a concrete metric to assess whether their agent‑runtime observability meets compliance and audit requirements. The benchmark’s regime‑agnostic adapters mean it can be plugged into existing orchestration stacks—whether the system uses a custom provenance graph or a commercial ledger—without extensive re‑engineering.
From a product perspective, the ability to demonstrate “zero over‑claim” is a competitive differentiator for AI platforms that market themselves as trustworthy or regulated. Companies can embed DEMM‑Bench into CI/CD pipelines to automatically flag insufficient evidence before deployment, reducing the risk of costly post‑mortems.
Moreover, the benchmark aligns with emerging governance frameworks (e.g., EU AI Act, ISO/IEC 42001) that require demonstrable decision provenance. By providing a reproducible, open‑source evaluation suite, DEMM‑Bench helps bridge the gap between technical observability and legal accountability.
Organizations looking to accelerate AI adoption can leverage the UBOS platform overview to integrate DEMM‑Bench into their workflow automation studio, ensuring that every autonomous action is backed by verifiable evidence.
What Comes Next
While DEMM‑Bench marks a significant step forward, several limitations remain:
- Scope of evidence regimes. The current eight regimes cover common artifacts but omit emerging sources such as model‑explainability traces or federated learning audit logs.
- Scalability of adapters. Normalizing high‑volume streams in real time may require specialized streaming processors.
- Human‑in‑the‑loop validation. The oracle labels were curated by experts; scaling this to large, continuously evolving systems will need semi‑automated labeling techniques.
Future research directions include extending DEMM‑Bench to cover:
- Dynamic policy evolution, where governance rules change during runtime.
- Cross‑organizational evidence sharing, enabling audits across supply‑chain AI agents.
- Integration with AI‑driven monitoring tools that can predict evidence insufficiency before it occurs.
Practitioners interested in building enterprise‑grade governance pipelines can explore the Enterprise AI platform by UBOS, which already supports provenance capture, policy enforcement, and can host DEMM‑Bench adapters as micro‑services.
Finally, the authors have released the full 64‑case dataset, construction‑oracle labels, and baseline implementations under an open license. This openness invites the community to contribute additional regimes, improve adapters, and benchmark new agent architectures, fostering a collaborative ecosystem around decision evidence maturity.
References
DEMM‑Bench: A Cross‑Regime Benchmark for Agent‑Runtime Governance‑Evidence Sufficiency (arXiv)