
- Updated: June 29, 2026
- 8 min read
DART: Draft-Agreement Routing for Training-Free Adaptive Thinking Budgets in Hybrid Reasoning Models
Direct Answer
DART (Draft‑Agreement Routing) is a training‑free routing framework that lets hybrid reasoning models decide, on a per‑query basis, whether to answer immediately or to allocate extra “thinking” tokens. It matters because it cuts token waste on easy questions while boosting accuracy on hard problems, all without any labeled data or gradient updates.
Background: Why This Problem Is Hard
Large language models (LLMs) have become the backbone of AI‑driven agents, from customer‑service bots to autonomous code generators. Many of these agents operate in a hybrid reasoning mode: they can either emit a direct answer or invoke a multi‑step chain‑of‑thought (CoT) that consumes additional tokens. The trade‑off is stark. Over‑thinking cheap queries inflates API costs and latency; under‑thinking hard queries leads to hallucinations or outright failures.
Existing routers attempt to balance this trade‑off by training a classifier on a curated dataset of “easy” vs. “hard” prompts. That approach suffers from three systemic bottlenecks:
- Label dependency: Curating high‑quality difficulty labels is labor‑intensive and quickly becomes stale as models evolve.
- Static budgets: Many systems pre‑allocate a fixed token budget for CoT, ignoring the fact that difficulty varies not only across prompts but also across answer candidates.
- Evidence blind spots: Traditional routers ignore the model’s own confidence signals—such as draft entropy or internal disagreement—that could serve as real‑time evidence of difficulty.
In production environments where API usage is metered and latency budgets are tight, these shortcomings translate into higher operating costs and lower user satisfaction. A router that can adapt on the fly, without the overhead of data collection or fine‑tuning, would therefore be a game‑changer for any AI‑first product.
What the Researchers Propose
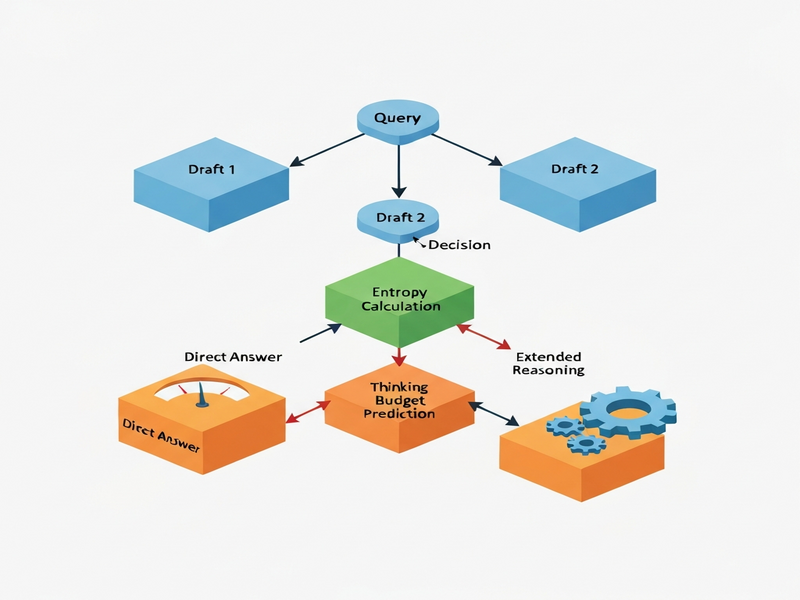
The DART framework reframes routing as a two‑stage draft‑agreement problem. Instead of training a separate classifier, DART leverages the LLM itself to generate two cheap “no‑think” drafts for each query. The core ideas are:
No‑Think Draft Sampling
For any incoming prompt, DART asks the model to produce two independent answers using a minimal token budget (e.g., 16‑32 tokens). These drafts are deliberately short, avoiding any explicit chain‑of‑thought reasoning.
Agreement Detection and Direct Answering
If the two drafts converge—meaning they are identical or semantically equivalent—DART treats this agreement as strong evidence that the problem is easy. The system then returns the draft as the final answer, bypassing any further computation.
Entropy‑Based Budget Prediction
When the drafts diverge, DART measures the entropy (i.e., uncertainty) of each draft’s token distribution. Higher entropy signals greater ambiguity. DART feeds this entropy signal into a lightweight budget predictor that decides how many extra thinking tokens to allocate for a full CoT pass. The predictor is a simple rule‑based function, not a learned model, keeping the entire pipeline training‑free.
By grounding routing decisions in the model’s own output signals, DART eliminates the need for external labels, static budgets, or gradient updates. The framework is agnostic to model size, architecture, or deployment modality (cloud API vs. on‑premise).
How It Works in Practice
The operational flow of DART can be broken down into four deterministic stages, each of which can be implemented as a microservice or a step in a workflow orchestration engine.
- Input Reception: The user query arrives at the router via an API gateway.
- Draft Generation: The router invokes the LLM twice with a “no‑think” prompt template (e.g., “Answer briefly in one sentence”). Both calls run with a low temperature and a strict token ceiling.
- Agreement Check: A lightweight string‑matching or semantic similarity module compares the two drafts. If similarity exceeds a predefined threshold (often 0.95 for exact match), the router returns the draft immediately.
- Budget Allocation: If the drafts differ, the router computes the average token‑level entropy across the two outputs. A simple mapping—such as “entropy 2.0 → 256 tokens”—determines the thinking budget. The router then launches a full‑scale CoT generation with the allocated budget and returns the final answer.
What distinguishes DART from prior routers is its reliance on internal evidence rather than external supervision. The system treats the model’s own uncertainty as a first‑class signal, turning the LLM into both the problem solver and the difficulty estimator.
Below is a schematic illustration of the DART pipeline:
Because each stage is stateless and inexpensive, DART can be wrapped around any existing LLM endpoint—OpenAI, Anthropic, or self‑hosted models—without altering the underlying model weights.
Evaluation & Results
The authors benchmarked DART across two canonical hybrid‑reasoning domains: high‑school and Olympiad‑level math problems, and code‑generation tasks that require execution‑based equivalence checking. The evaluation protocol mirrors real‑world usage: a mixed bag of easy and hard queries, token‑budget constraints, and a cost‑aware metric that combines accuracy with token consumption.
Math Reasoning Improvements
On a suite of 1,200 math problems ranging from elementary algebra to International Mathematical Olympiad (IMO) style proofs, DART achieved up to a 9‑point accuracy lift on the hardest tier while slashing thinking‑token usage by 15‑69 %. The key insight is that many “easy” problems—simple arithmetic or direct formula recall—were resolved after the first draft agreement, freeing tokens for the truly challenging proofs.
Code Reasoning Gains
For code synthesis, the authors used a benchmark where the model must generate a function and then pass a hidden test suite. DART’s entropy‑driven budget predictor allocated more tokens to ambiguous prompts, leading to a 22.5‑point boost in execution‑based correctness. Simultaneously, token consumption dropped by 51‑63 % because straightforward snippets (e.g., a one‑line list comprehension) were answered directly.
Cross‑Model Generalization
DART was tested on models spanning three orders of magnitude—from 0.6 B to 32 B parameters—and across distinct families (decoder‑only, encoder‑decoder). The agreement signal remained robust, and the entropy‑budget mapping required only minor calibration. Even in API‑only settings where the router cannot inspect internal logits, a proxy entropy estimate derived from token probabilities proved sufficient.
Overall, the experiments demonstrate that DART preserves or improves the “always‑think” baseline accuracy while delivering substantial token savings—a win‑win for both performance and cost.
Why This Matters for AI Systems and Agents
From a systems‑engineering perspective, DART offers a plug‑and‑play solution to a problem that has traditionally required bespoke engineering effort. Its training‑free nature means that product teams can adopt the router without a data‑labeling pipeline, reducing time‑to‑market for new AI features.
For AI agents that operate under strict latency budgets—such as real‑time customer support bots or autonomous workflow assistants—DART’s early‑exit capability can shave milliseconds off response times for the majority of queries. This directly translates into higher user satisfaction scores and lower infrastructure spend.
Moreover, the token‑efficiency gains align with the economics of large‑scale LLM deployments. Companies that bill per‑token (e.g., OpenAI’s usage model) can see immediate cost reductions, especially when scaling to millions of daily interactions.
Practically, DART can be integrated into existing orchestration layers. For example, the Workflow automation studio can embed DART as a conditional node that decides whether to invoke a heavyweight reasoning chain or return a lightweight draft. Similarly, the UBOS platform overview highlights modular components that map neatly onto DART’s stages, enabling rapid prototyping of token‑aware agents.
What Comes Next
While DART marks a significant step forward, several open challenges remain:
- Dynamic Thresholding: The current agreement threshold is static. Future work could explore adaptive thresholds that consider user intent, domain specificity, or historical success rates.
- Multi‑Draft Extensions: Sampling more than two drafts might provide a richer uncertainty signal, especially for ambiguous prompts.
- Cross‑Modal Reasoning: Extending DART to multimodal models (vision‑language, audio‑text) will require new draft generation strategies that respect modality‑specific token budgets.
- Feedback Loops: Incorporating post‑answer user feedback could refine the entropy‑budget mapping over time without formal retraining.
From an application standpoint, DART opens the door to smarter AI marketing agents that can decide when a quick tagline suffices versus when a full campaign brief needs deeper reasoning. It also dovetails with the UBOS partner program, inviting ecosystem partners to build custom routers that respect their own cost and latency constraints.
For developers eager to experiment, the framework can be prototyped using the OpenAI ChatGPT integration or the ChatGPT and Telegram integration, allowing rapid validation on real user traffic.
In summary, DART demonstrates that intelligent routing does not have to rely on massive labeled datasets or costly fine‑tuning. By listening to the model’s own drafts, it achieves a pragmatic balance between accuracy, speed, and cost—an equilibrium that many AI‑first enterprises are still chasing.
For the full technical details, see the DART paper on arXiv.