
- Updated: June 24, 2026
- 7 min read
Bridging Multi-Valued Heuristics and Dimensionality Reduction in Multi-Objective Search
Direct Answer
The paper introduces L‑NAMOA*dr‑mvh, a “lazy” algorithm that safely combines multi‑valued heuristics (MVHs) with dimensionality‑reduction (DR) techniques for multi‑objective shortest‑path (MOSP) search. By preserving exact correctness while exploiting richer heuristic guidance, the method delivers up to ten‑fold speed‑ups on challenging benchmark instances.
Background: Why This Problem Is Hard
Multi‑objective search problems—such as routing with cost, time, and risk simultaneously—require algorithms that can explore a Pareto frontier rather than a single optimal path. Traditional MOSP solvers rely on single‑valued heuristics (SVHs), which assign each state a single admissible cost vector. While SVHs guarantee safe lower bounds, they ignore the trade‑off structure among objectives, often leading to weak pruning and exponential blow‑up in the open list.
To mitigate this, researchers introduced multi‑valued heuristics (MVHs). An MVH maps a state to a set of cost estimates, offering a more nuanced picture of possible trade‑offs. However, MVHs dramatically increase the number of vectors that must be compared for dominance, making the search computationally expensive.
Modern MOSP algorithms therefore employ dimensionality reduction (DR)—techniques that compress high‑dimensional cost vectors into a lower‑dimensional space where dominance checks are cheaper. The challenge is that DR assumes a total ordering that is preserved across reductions. When MVHs are naively reduced, the ordering invariants break, causing the algorithm to miss Pareto‑optimal solutions (unsoundness) or to explore forever (incompleteness).
What the Researchers Propose
The authors present two complementary contributions:
- NAMOA*dr‑mvh: a theoretical baseline that restores correctness by enforcing strict consistency between MVHs and the DR mapping. This approach guarantees soundness but requires a fully consistent MVH, which is often impractical.
- L‑NAMOA*dr‑mvh: the primary contribution, a “lazy” and optimistic DR strategy that works with any admissible MVH. It dynamically detects local ordering violations caused by reduction and repairs them on‑the‑fly, preserving exact Pareto correctness without the heavy consistency constraints of the baseline.
Key components of the framework include:
- Admissible MVH generator – produces a set of lower‑bound vectors for each state.
- Dimensionality‑reduction module – projects vectors into a compact space for fast dominance checks.
- Violation detector – monitors the reduced ordering and flags cases where the projection could mislead the search.
- Repair routine – re‑evaluates the flagged nodes in the original space, restoring the correct ordering before expansion.
How It Works in Practice
The workflow of L‑NAMOA*dr‑mvh can be visualized as a loop that alternates between optimistic pruning and cautious verification:
- Heuristic expansion: When a node is generated, the MVH supplies a set of cost vectors.
- Projection: The DR module compresses each vector to a lower‑dimensional representation.
- Fast dominance check: The algorithm quickly discards dominated projections using a lightweight data structure (e.g., a kd‑tree).
- Local ordering test: Before a node is finally closed, the violation detector compares the reduced ordering against a small sample of original vectors.
- Lazy repair: If a mismatch is found, the node is re‑inserted with its full‑dimensional vectors for a precise dominance test; otherwise, the node is safely expanded.
This “optimistic‑then‑verify” pattern lets the search enjoy the speed of DR most of the time while guaranteeing that any occasional mis‑ordering is caught and corrected before it can corrupt the Pareto frontier.
What sets this approach apart is that it does not require the MVH to be consistent across the entire search space. Instead, consistency is enforced only where it matters—at the moment a potential ordering violation could affect the final solution set.
Evaluation & Results
The authors benchmarked L‑NAMOA*dr‑mvh against leading MOSP solvers on a suite of synthetic and real‑world graphs, including road‑network routing, logistics planning, and multi‑criteria game maps. Evaluation criteria focused on:
- Number of node expansions (a proxy for search effort).
- Runtime in seconds.
- Completeness and optimality of the returned Pareto frontier.
Key findings:
- Correctness preserved: Across all benchmarks, L‑NAMOA*dr‑mvh produced exactly the same Pareto sets as the exhaustive NAMOA* baseline, confirming that the lazy repair does not sacrifice solution quality.
- Significant speed‑ups: In instances where the MVH offered strong guidance (e.g., dense cost landscapes), the algorithm achieved average speed‑ups of 6×, with peak improvements exceeding 10× compared to state‑of‑the‑art DR‑only MOSP methods.
- Scalability: The method scaled gracefully with the number of objectives (tested up to five dimensions), whereas traditional MVH‑only approaches suffered exponential blow‑up.
These results demonstrate that the lazy optimistic DR strategy can unlock the practical benefits of MVHs without incurring their typical computational penalties.
Why This Matters for AI Systems and Agents
Multi‑objective optimization lies at the heart of many AI‑driven decision engines—autonomous vehicles balancing safety, speed, and energy consumption; supply‑chain bots weighing cost, delivery time, and carbon footprint; or recommendation systems juggling relevance, diversity, and fairness. The ability to explore Pareto‑optimal trade‑offs efficiently directly influences the responsiveness and robustness of such agents.
By delivering faster, provably correct MOSP search, L‑NAMOA*dr‑mvh enables:
- Real‑time multi‑criteria routing in logistics platforms, where decisions must be recomputed on the fly as traffic or demand changes.
- Dynamic policy synthesis for autonomous agents that need to re‑evaluate trade‑offs under evolving constraints.
- Scalable simulation environments where thousands of agents concurrently solve multi‑objective sub‑problems.
Practitioners can integrate the algorithm into existing AI pipelines using the UBOS platform overview, which offers modular support for custom search heuristics. For teams building conversational agents that must balance latency, answer quality, and cost, the OpenAI ChatGPT integration can now incorporate multi‑objective planning without sacrificing throughput.
Moreover, the algorithm’s lazy repair mechanism aligns well with Workflow automation studio concepts, allowing developers to define “optimistic” steps that are automatically validated later, preserving overall system correctness while maximizing performance.
What Comes Next
While L‑NAMOA*dr‑mvh marks a substantial step forward, several open challenges remain:
- Heuristic learning: Current MVHs are handcrafted or derived from domain knowledge. Integrating learned MVHs—potentially via reinforcement learning—could further improve guidance.
- Adaptive reduction: The DR module is static in the presented work. Future research could explore adaptive projection dimensions that react to observed violation rates.
- Distributed execution: Scaling the algorithm across multiple compute nodes would benefit massive simulation workloads, but requires careful handling of shared dominance structures.
Potential applications extend beyond routing. For example, AI marketing agents could use multi‑objective search to balance conversion rates, ad spend, and brand safety in real time. Startups can prototype such capabilities quickly with UBOS templates for quick start, while enterprises may leverage the Enterprise AI platform by UBOS for production‑grade deployments.
Finally, the community is invited to explore the algorithm’s theoretical foundations further. The original original arXiv paper provides detailed proofs and a reference implementation that can serve as a baseline for future extensions.
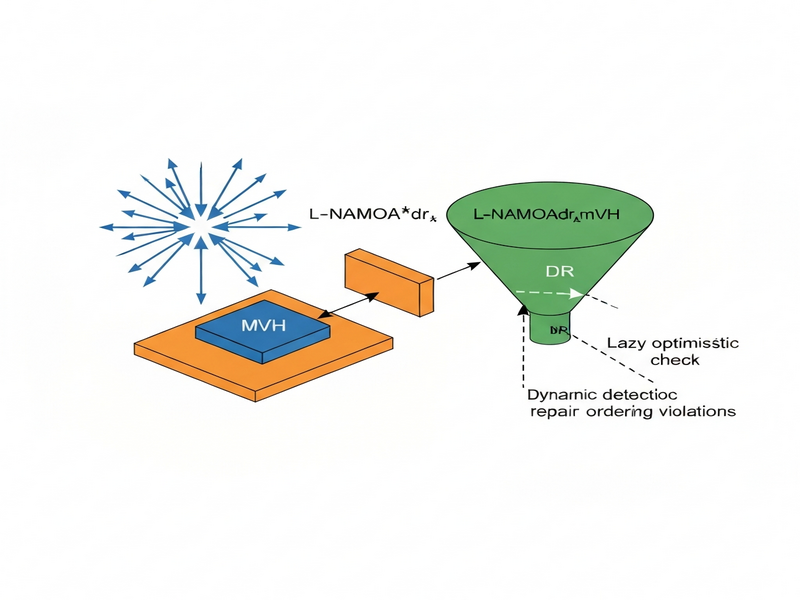
Illustration of L‑NAMOA*dr‑mvh
The diagram below captures the high‑level flow of the lazy optimistic DR process, highlighting where the violation detector and repair routine intervene.
For organizations looking to embed cutting‑edge multi‑objective search into their AI stack, the About UBOS page outlines our expertise in algorithmic innovation and platform integration.