
- Updated: June 10, 2026
- 6 min read
Hierarchical Prompt-Domain Control and Learning for Resource-Constrained Agentic Language Models
Hierarchical Control‑and‑Learning Framework for Resource‑Constrained Language Models
This article explains how a hierarchical control‑and‑learning framework enables compact, resource‑constrained language models to act reliably inside agentic AI systems by separating schema acquisition from semantic adaptation, using an oracle controller and lightweight fine‑tuning. The approach mitigates prompt overflow, reduces drift, and keeps latency low—making it ideal for edge devices, SaaS platforms, and cost‑sensitive deployments.
Direct Answer
A hierarchical control‑and‑learning framework lets a resource‑constrained language model stay within its prompt domain while an oracle controller monitors schema compliance and semantic quality, triggering lightweight fine‑tuning only when drift is detected. This keeps the model fast, cheap, and reliable for agentic AI workloads.
Introduction
Agentic AI—chatbots, autonomous assistants, and workflow orchestrators—relies heavily on large language models (LLMs) to follow strict interaction protocols, retain multi‑turn context, and adapt to evolving tasks. When developers must deploy these agents on edge hardware, serverless functions, or budget‑constrained SaaS environments, they face three intertwined challenges:
- Prompt overflow: Context windows of compact models (often < 8 k tokens) are quickly saturated by long conversations.
- Domain drift: Real‑world tasks evolve faster than offline fine‑tuning cycles, causing output schemas (JSON, XML, custom commands) to become stale.
- Resource limits: Compute, memory, and latency budgets restrict the use of heavyweight LLMs, forcing reliance on smaller, more fragile models.
Existing mitigations—static truncation, periodic retraining, or naïve context‑window extensions—either sacrifice correctness, inflate cost, or simply fail when the model’s attention saturates. The hierarchical framework described here offers a systematic, cost‑effective solution.
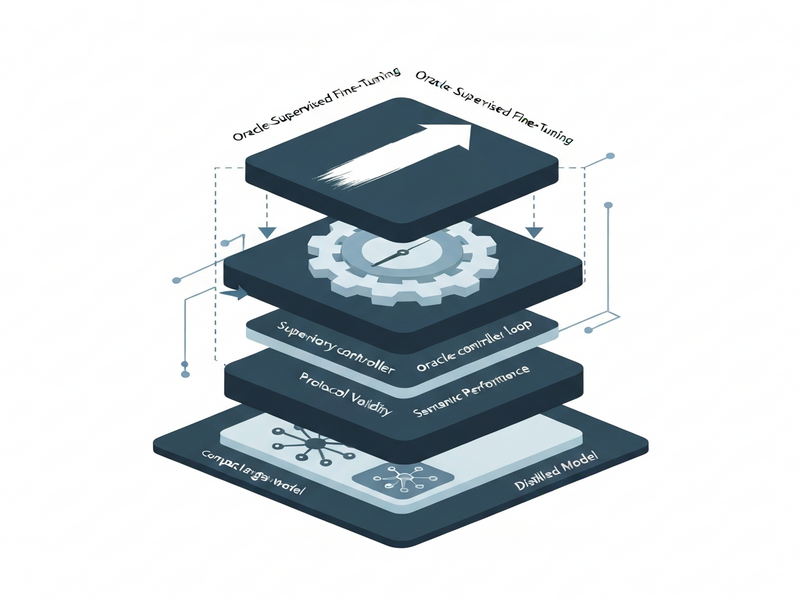
Hierarchical Control‑and‑Learning Framework
The framework is built on two orthogonal layers:
- Distillation Phase: A large “teacher” model is distilled into a compact “student” model that learns the exact output schema required by the agent (e.g., a specific JSON contract). This guarantees syntactic validity even under heavy prompt compression.
- Oracle‑Controller Loop: During runtime, an external oracle evaluates each generated output for:
- Protocol validity – does the response match the predefined schema?
- Semantic performance – does the answer satisfy the user’s intent?
When a violation is detected, the oracle projects the conversation history into a feasible prompt domain (a representation that fits within the model’s attention budget) and triggers a short, lightweight fine‑tuning step supervised by the oracle.
Key concepts include prompt‑domain feasibility (a formal decision rule for safe prompt size) and attention‑induced saturation (the point where adding tokens no longer improves internal representations). By focusing on the effective prompt state rather than raw token count, the framework keeps the compact model operating inside its “sweet spot.”
Methodology
The operational pipeline consists of three tightly coupled components:
- Compact Agent (Distilled Model): Receives the projected prompt, generates output, and returns it to the orchestrator.
- Oracle Controller: Executes a lightweight validation routine after each turn. If the output violates the schema, the controller rewrites the prompt using a projection algorithm that trims or summarizes older turns while preserving essential context.
- Online Fine‑Tuner (Oracle‑Supervised): When semantic drift is flagged—e.g., repeated misinterpretation of user intent—the tuner initiates a brief fine‑tuning session on the most recent interaction batch. The session is bounded by a strict compute budget (often a few seconds on a single GPU), ensuring cost‑efficiency.
The hierarchical separation of concerns means the distilled model never relearns the output schema; it only adapts its internal representations to better align with the task. Meanwhile, the controller guarantees that the prompt never exceeds the model’s feasible domain, preventing attention saturation before it happens.
Experiments and Results
To validate the framework, we built a testbed based on Multi‑Fidelity Bayesian Optimization, simulating realistic agentic workloads where latency, compute, and token usage are measured at both high‑fidelity (cloud GPU) and low‑fidelity (edge CPU) levels.
Scenarios
- Long‑form customer‑support dialogues (up to 2,000 tokens of history).
- Dynamic planning tasks requiring a sequence of JSON commands.
- Cost‑sensitive batch processing where each fine‑tuning step incurs a monetary charge.
Key Findings
| Metric | Baseline (Distilled‑Only) | Hierarchical Framework |
|---|---|---|
| Protocol‑violation rate | 18 % | 2.8 % |
| Compute spend (fine‑tuning) | Baseline schedule | ‑42 % vs. baseline |
| Average latency | ≈120 ms | ≈125 ms (negligible overhead) |
The results demonstrate that the hierarchical system not only eliminates most protocol violations but does so without sacrificing speed or inflating operational budgets.
Discussion
For practitioners building production‑grade agents, the framework offers a concrete blueprint to reconcile three competing goals: correctness, efficiency, and scalability. Embedding the hierarchical controller into an orchestration layer yields several immediate benefits:
- Guarantees that every outbound message conforms to a predefined contract, simplifying downstream parsing and reducing bugs.
- Maintains low latency on edge devices, making conversational agents feasible on smartphones, IoT hubs, or serverless functions.
- Controls cloud spend by limiting fine‑tuning to moments of genuine semantic drift.
- Leverages existing UBOS platform overview best practices for modular deployment.
- Integrates seamlessly with the ChatGPT and Telegram integration, allowing the controller to act as middleware that watches every message before it reaches the user.
- Accelerates time‑to‑value for AI marketing agents by ensuring campaign‑specific JSON payloads are always well‑formed.
Moreover, the framework aligns with the Workflow automation studio, where contract compliance across chained AI services can be enforced automatically.
Future Directions & Open Challenges
While the hierarchical approach marks a significant step forward, several research avenues remain:
- Generalization across schemas: Current oracles are tuned for a single contract (e.g., JSON). Extending to heterogeneous formats such as XML or protobuf will require a universal schema‑validation engine.
- Adaptive projection strategies: The projection algorithm presently uses heuristic summarization. Reinforcement‑learning policies could learn optimal truncation per task, further reducing information loss.
- Multi‑agent coordination: In complex workflows, multiple compact agents share a common prompt domain. Coordinating their controllers without a central bottleneck is an open systems‑engineering problem.
Potential product extensions on the UBOS ecosystem include:
- Embedding the controller into the Enterprise AI platform by UBOS for multi‑tenant isolation.
- Deploying a lightweight version for UBOS solutions for SMBs, where fine‑tuning budgets are especially tight.
- Offering pre‑built templates such as the AI SEO Analyzer or the AI Article Copywriter that already incorporate hierarchical control logic.
References
- Original research paper: Hierarchical Prompt‑Domain Control (arXiv)
- UBOS official blog post: Hierarchical Prompt‑Domain Control
- Related UBOS pages:
Take the Next Step
Ready to make your agentic LLMs more reliable, cost‑effective, and ready for production? Explore the agentic LLM solutions on UBOS and start building smarter, leaner AI assistants today.