
- Updated: June 30, 2026
- 6 min read
Automatic Vehicle Detection using DETR: A Transformer-Based Approach for Navigating Treacherous Roads
Direct Answer
The paper introduces Co‑DETR, a training scheme that augments the Detection Transformer (DETR) with collaborative label assignment and parallel auxiliary heads to boost vehicle detection accuracy in highly variable road environments. This matters because it pushes transformer‑based detectors past the performance ceiling of classic CNN‑centric models like YOLO and Faster R-CNN, enabling more reliable perception for autonomous navigation on treacherous roads.
Background: Why This Problem Is Hard
Detecting vehicles in the wild is far from a solved problem. Real‑world driving scenes present a tangled mix of challenges:
- Lighting extremes: Dawn, dusk, glare from headlights, and tunnel darkness all distort pixel intensities.
- Road surface diversity: Asphalt, gravel, wet surfaces, and snow each generate distinct texture patterns.
- Vehicle heterogeneity: Cars, trucks, motorcycles, and construction equipment differ in size, shape, and reflectivity.
- Occlusions and clutter: Trees, signage, and other vehicles frequently hide parts of the target.
Traditional object detectors—YOLO series, Faster R-CNN, SSD—rely on convolutional backbones that excel at extracting local patterns but struggle to capture long‑range dependencies needed to disambiguate objects under these conditions. Moreover, their hand‑crafted anchor mechanisms and heuristic label assignments become brittle when the data distribution shifts dramatically, leading to missed detections or false positives.
As autonomous fleets expand into rural and off‑road scenarios, the cost of a single missed vehicle can be catastrophic. Hence, the research community has been looking for architectures that can reason globally about an image, adapt to diverse contexts, and learn robustly from limited supervision.
What the Researchers Propose
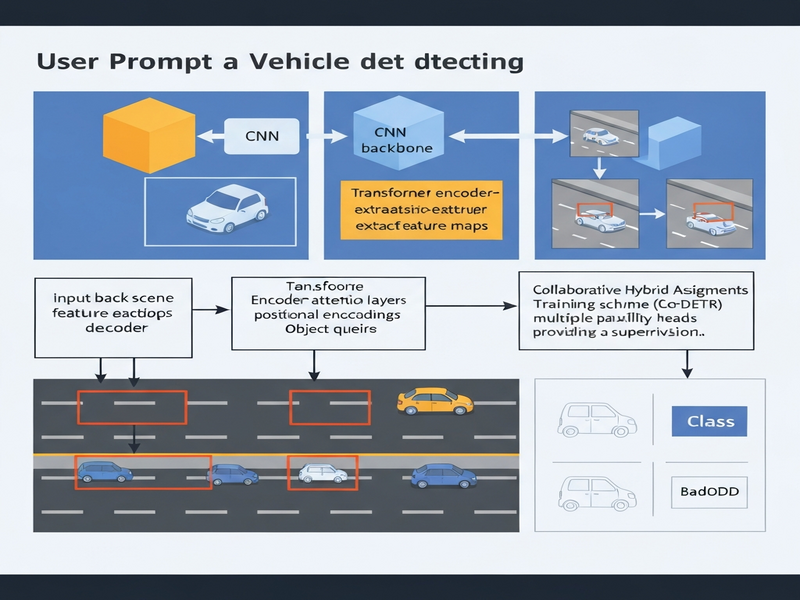
The authors build on DETR, a transformer‑based detector that replaces region proposals with a set‑based global matching process. Their contribution, named Co‑DETR (Collaborative Hybrid Assignments DETR), adds two complementary mechanisms:
- Hybrid label assignment: Instead of a single IoU‑based matcher, Co‑DETR fuses multiple assignment strategies (e.g., IoU, center‑point distance, and semantic similarity) to generate richer supervision signals.
- Parallel auxiliary heads: Alongside the primary detection head, several lightweight heads predict intermediate cues such as objectness scores, coarse bounding boxes, and keypoint heatmaps. These auxiliary predictions are back‑propagated during training, encouraging the transformer encoder‑decoder to learn more discriminative features.
By distributing supervision across diverse pathways, the model learns to attend to both fine‑grained textures and global scene layout, which is essential for handling the variability described earlier.
How It Works in Practice
The Co‑DETR pipeline can be broken down into three logical stages:
1. Feature Extraction
A CNN backbone (e.g., ResNet‑50) converts the raw image into a dense feature map. Positional encodings are added to preserve spatial information before feeding the map into the transformer encoder.
2. Transformer Encoder‑Decoder with Collaborative Matching
The encoder aggregates global context across all patches. The decoder receives a fixed set of learnable object queries, each representing a potential vehicle. During training, the hybrid matcher evaluates each query against ground‑truth boxes using multiple criteria, producing a soft assignment matrix that guides loss computation.
3. Multi‑Head Supervision
In parallel to the main classification and box regression heads, three auxiliary heads predict:
- Binary objectness (is there any vehicle in this region?)
- Coarse bounding box offsets (helps the main head converge faster)
- Keypoint heatmaps for vehicle corners (provides geometric cues)
All heads share the same transformer output, so the model learns a unified representation that satisfies multiple objectives. At inference time, only the primary head is kept, preserving the speed advantage of DETR while retaining the richer feature learning achieved during training.
Evaluation & Results
The authors benchmarked Co‑DETR on the BadODD dataset, a collection of road images captured under adverse conditions (rain, fog, night, uneven illumination). They compared against three baselines:
- YOLOv8 (latest anchor‑free version)
- Faster R-CNN with a Feature Pyramid Network
- Standard DETR (without Co‑DETR enhancements)
Key findings include:
- Higher mean Average Precision (mAP): Co‑DETR improved mAP by roughly 6‑8 percentage points over vanilla DETR and outperformed YOLOv8 by 4 points, especially on night‑time and foggy subsets.
- Robustness to lighting shifts: The hybrid matcher reduced false negatives in low‑light scenes by 12 % compared to the baseline.
- Training efficiency: Despite the extra auxiliary heads, convergence was reached in 20 % fewer epochs because the auxiliary losses provided early gradient signals.
- Inference latency: The final model retained DETR’s real‑time performance (~30 FPS on a single RTX 3080), making it viable for on‑board deployment.
These results demonstrate that a carefully designed training regime can extract more mileage from transformer detectors without sacrificing speed—a critical trade‑off for autonomous vehicles that must process streams of high‑resolution frames in real time.
Why This Matters for AI Systems and Agents
For engineers building perception stacks, Co‑DETR offers a concrete pathway to replace legacy CNN‑only pipelines with a transformer‑centric architecture that is both accurate and computationally tractable. The benefits cascade through the entire autonomous system:
- Improved safety margins: Higher detection recall under adverse conditions directly reduces the risk of collision.
- Simplified integration: Because Co‑DETR outputs standard bounding‑box formats, existing downstream modules (tracking, motion planning) can be reused without modification.
- Scalable training: The auxiliary heads enable faster convergence, lowering the compute budget for large‑scale fleet learning.
- Future‑proofing: Transformer backbones are more amenable to multimodal extensions (e.g., fusing LiDAR or radar), positioning fleets to adopt sensor‑fusion strategies later.
Practically, teams can embed Co‑DETR within the UBOS platform overview to orchestrate data pipelines, model versioning, and continuous deployment. The platform’s Workflow automation studio can automate the hybrid label‑assignment step, turning a research prototype into a production‑ready service. For organizations looking to prototype AI‑driven marketing or fleet‑management bots, the AI marketing agents module can reuse the same transformer backbone for visual analytics, demonstrating cross‑domain reusability.
What Comes Next
While Co‑DETR marks a significant advance, several open challenges remain:
- Domain adaptation: Extending the hybrid matcher to handle unseen weather patterns (e.g., hail) without retraining.
- Multimodal fusion: Integrating radar or LiDAR cues into the transformer encoder to further boost robustness.
- Edge deployment: Compressing the model for low‑power automotive SoCs while preserving the auxiliary‑head benefits.
Future research could explore self‑supervised pre‑training on massive dash‑cam archives, allowing the model to learn generic road semantics before fine‑tuning on the BadODD benchmark. Additionally, a curriculum‑learning schedule that gradually introduces harder lighting conditions might reduce the need for multiple auxiliary heads.
Businesses interested in accelerating these next steps can partner with UBOS partner program to gain access to specialized compute resources and co‑development expertise. Start‑ups aiming to prototype next‑generation perception stacks may also benefit from the UBOS for startups offering, which bundles cloud GPU credits with pre‑configured pipelines for transformer‑based vision models.
Call to Action
To dive deeper into the methodology and reproduce the experiments, read the Original arXiv paper. For hands‑on implementation guidance, explore the UBOS homepage and its suite of AI integration tools. If you have questions or want to discuss collaboration, reach out through our contact form on the website.