
- Updated: June 29, 2026
- 7 min read
A Stackelberg Framework for Resource-Aware LLM Agents: Learning, Repair, and Conditional Guarantees

Direct Answer
The paper introduces a Stackelberg‑game‑based framework that lets a high‑level controller (the “leader”) allocate computational resources—context length, prompt verbosity, and tool usage—to a large language model (LLM) agent (the “follower”) while guaranteeing conditional performance bounds. This matters because it offers a principled, learn‑and‑repair loop that cuts token costs without sacrificing answer quality, addressing a core bottleneck in deploying multi‑turn LLM agents at scale.
Background: Why This Problem Is Hard
Modern LLM agents are no longer single‑shot question‑answerers; they engage in multi‑turn dialogues, retrieve external data, and invoke tools such as browsers or code interpreters. Each turn consumes tokens, API calls, and compute cycles, all of which translate directly into monetary cost and latency. The difficulty stems from three intertwined factors:
- Dynamic task heterogeneity. A single session may shift from a brief factual lookup to a lengthy code‑generation sub‑task, demanding different amounts of context and prompting detail.
- Finite budgets. Cloud‑based LLM providers charge per token and per tool invocation, so uncontrolled growth quickly exceeds operational budgets, especially for enterprise‑scale deployments.
- Static throttling is brittle. Simple heuristics—e.g., “always truncate context to 2 k tokens” or “limit tool calls to three per session”—ignore the evolving state of the conversation and can cause premature truncation, loss of critical information, or unnecessary API calls.
Existing resource‑management approaches either treat the LLM as a black box with fixed limits or rely on handcrafted rules that lack adaptability. Consequently, developers face a trade‑off between safety (never overspend) and effectiveness (maintain answer quality). A more flexible, data‑driven governance mechanism is needed to navigate this trade‑off in real time.
What the Researchers Propose
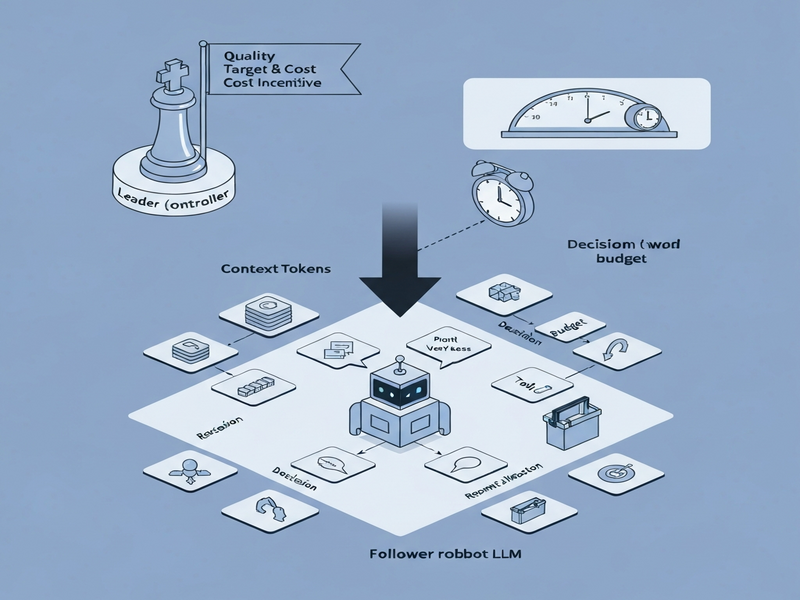
The authors cast resource governance as a contextual Stackelberg game. In this two‑player game:
- The leader (a controller module) first announces a quality target—the minimum acceptable answer fidelity—and a cost incentive that quantifies how much token usage it wishes to penalize.
- The follower (the LLM executor) observes the announced target and incentive, then selects concrete resource actions for the upcoming turn: how many previous tokens to retain, how verbose the prompt should be, and whether to invoke external tools.
Key components of the proposal include:
- Conditional response model. A learned surrogate that predicts the follower’s quality and token cost given any leader policy and current session state.
- Leader policy optimization. Using the surrogate, the controller solves a bilevel optimization problem to find the incentive that best balances cost and quality.
- Policy repair. After training in a simulated environment, the controller is calibrated against the real API, then projected onto a safe action set that respects empirical constraints (e.g., maximum allowed tokens per turn).
Crucially, the framework provides conditional theoretical guarantees—existence of equilibrium, stability of the follower’s response, and bounded transfer error from the surrogate to the real system—under assumptions that are verified empirically.
How It Works in Practice
The operational workflow can be broken down into three stages that repeat for every turn of a conversation:
- State observation. The system records the current dialogue history, recent tool calls, and cumulative token usage.
- Leader decision. Based on the observed state, the leader consults the optimized policy to emit a pair
(q, λ)whereqis the desired quality threshold (e.g., a confidence score) andλis a scalar cost incentive. - Follower response. The LLM executor receives
(q, λ)and selects concrete actions:- Context trimming: decide how many prior tokens to keep.
- Prompt shaping: adjust verbosity, include or omit system instructions.
- Tool gating: enable or suppress calls to external APIs such as search or code execution.
The executor then generates the next response, and the loop repeats.
What distinguishes this approach from prior rule‑based pipelines is the *learned* mapping from leader incentives to follower actions, which adapts to the evolving conversation. The “repair” step ensures that the policy, once deployed against the real OpenAI or Anthropic API, respects observed limits (e.g., maximum token budget per request) by projecting the raw policy output onto a feasible set derived from calibration data.
Evaluation & Results
The authors validated the framework on a real‑API testbed comprising 300 multi‑turn interactions across heterogeneous tasks (knowledge retrieval, code synthesis, and creative writing). Two baselines were compared:
- Conservative static policy. Fixed context window of 1 k tokens, no tool gating, and a high‑verbosity prompt.
- Proposed repaired controller. The Stackelberg leader after repair, operating under the same budget constraints.
Key findings:
- Token cost reduction. The repaired controller achieved a 17.4 % lower average token consumption per turn (Welch’s t‑test, p=0.022), indicating a statistically significant efficiency gain.
- Quality preservation. Measured answer quality—using a combination of human ratings and automated similarity metrics—showed no statistically significant drop (p=0.44), suggesting the cost savings did not come at the expense of usefulness.
- Stability of follower response. Across the 300 turns, the follower’s actions remained within the projected safe set, confirming the effectiveness of the repair step.
While the experiments did not estimate the theoretical regret bounds or the exact transfer constants, the empirical evidence demonstrates that a carefully calibrated Stackelberg controller can find a “sweet spot” where resource usage is trimmed without harming user‑perceived quality.
Why This Matters for AI Systems and Agents
For practitioners building production‑grade LLM agents, the framework offers a concrete pathway to embed economic awareness directly into the decision loop. The benefits cascade across several dimensions:
- Cost predictability. By tying token usage to a leader‑issued incentive, organizations can forecast monthly spend more reliably, a critical factor for budgeting in SaaS‑based AI services.
- Dynamic adaptability. Unlike static throttles, the Stackelberg controller reacts to the conversation’s context, preserving depth when needed (e.g., during complex code debugging) and trimming aggressively when the task is simple.
- Modular integration. The leader can be swapped out for a business‑specific policy (e.g., higher quality targets for premium customers) without retraining the entire LLM, thanks to the decoupled follower response model.
- Safety and compliance. The repair step guarantees that the deployed policy never exceeds empirically observed limits, reducing the risk of unexpected over‑usage spikes that could violate service‑level agreements.
These capabilities align closely with the needs of enterprises that rely on the Enterprise AI platform by UBOS to orchestrate large‑scale agent workflows. By plugging a Stackelberg‑style controller into the Workflow automation studio, teams can automatically balance performance and cost across dozens of concurrent agents.
What Comes Next
Despite the promising results, several open challenges remain:
- Scalability of the surrogate model. Training a conditional response model that generalizes across vastly different domains (legal, medical, creative) may require larger, domain‑specific datasets.
- Regret quantification. Future work should derive tighter bounds on the regret incurred by the leader’s approximate policy, especially when the follower’s behavior drifts over time.
- Multi‑leader extensions. In complex ecosystems, multiple controllers (e.g., cost manager, latency manager) may need to coordinate, suggesting a need for hierarchical or cooperative game formulations.
- Real‑time calibration. Automating the repair step so that the controller continuously updates its safe action set as API pricing or latency changes would further reduce manual overhead.
Addressing these gaps could unlock broader adoption in sectors where resource constraints are non‑negotiable, such as finance, healthcare, and autonomous robotics. Developers interested in experimenting with resource‑aware agents can start by exploring the OpenAI ChatGPT integration on the UBOS platform overview, then layer a custom Stackelberg controller using the platform’s Web app editor to prototype policy repair pipelines.
For a deeper dive into the theoretical underpinnings, readers should consult the original arXiv paper. The community is encouraged to extend the codebase, share calibration datasets, and benchmark against alternative governance mechanisms such as reinforcement‑learning‑based budget managers.
Ready to make your LLM agents both smarter and cheaper? Visit the UBOS homepage to explore ready‑made templates, pricing plans, and partner programs that can accelerate your journey toward resource‑aware AI.