
- Updated: June 10, 2026
- 6 min read
A Policy-Driven Runtime Layer for Agentic LLM Serving
Direct Answer
The paper introduces Agentic Runtime Layer (ARL), a policy‑driven middleware that sits between large language model (LLM) inference engines and multi‑agent orchestration frameworks. By codifying caching, scheduling, and safety decisions as declarative policies, ARL makes LLM serving scalable, predictable, and easier to operate for production‑grade agentic workloads.
Background: Why This Problem Is Hard
Enterprises are rapidly moving from single‑turn chat interfaces to agentic systems where dozens or hundreds of LLM‑powered agents collaborate in real time. This shift creates three intertwined bottlenecks:
- Resource contention. Each agent issues its own inference request, often with overlapping prompts or similar context, leading to redundant computation and ballooning GPU costs.
- Latency volatility. Orchestrators must meet strict service‑level objectives (SLOs) while the underlying inference stack suffers from cold‑start delays, variable token generation times, and network jitter.
- Policy enforcement. Safety filters, usage quotas, and data‑privacy constraints are traditionally hard‑coded into each agent, resulting in duplicated logic and brittle updates.
Existing LLM serving stacks—originally designed for monolithic chat or completion endpoints—address only raw throughput and basic request routing. They lack a unified abstraction for expressing “when to reuse a cached response,” “how to prioritize high‑value agents,” or “which safety policy applies to a given request.” Consequently, engineering teams spend weeks stitching together ad‑hoc caches, custom schedulers, and separate compliance layers, which hampers agility and inflates operational overhead.
What the Researchers Propose
The authors present a three‑tier architecture called the Policy‑Driven Runtime Layer (ARL). At its core, ARL treats every serving decision as a policy rule that can be authored, versioned, and evaluated at runtime. The framework consists of:
- Policy Engine. A lightweight rule interpreter that evaluates declarative policies written in a domain‑specific language (DSL). Policies can reference request metadata, system metrics, and historical usage patterns.
- Runtime Services. A set of pluggable modules—CacheSage (KV caching), SchedulerX (priority‑aware dispatch), and GuardRail (safety enforcement)—that expose standardized hooks for the Policy Engine.
- Orchestration Bridge. An API layer that translates agentic workflow commands (e.g., “spawn agent A with context C”) into ARL‑compatible requests, ensuring seamless integration with existing orchestration platforms.
Crucially, the researchers define nine concrete policies that cover the most common operational concerns in multi‑agent environments. These policies are not hard‑coded; they can be toggled on or off, combined, and refined without redeploying the underlying services.
How It Works in Practice
When an agent issues a request, the following workflow unfolds:
- Ingress. The request arrives at the Orchestration Bridge, which annotates it with agent ID, priority level, and a hash of the prompt.
- Policy Evaluation. The Policy Engine loads the active policy set and evaluates each rule against the request metadata. For example, the Cache‑First rule checks whether a KV entry exists for the prompt hash.
- Service Invocation. Based on the policy outcome, the engine routes the request to the appropriate Runtime Service:
- If a cache hit occurs, CacheSage returns the stored completion instantly.
- If the request exceeds a quota, GuardRail aborts it with a compliance error.
- Otherwise, SchedulerX places the request in a priority queue, possibly delaying low‑priority agents during peak load.
- Inference. SchedulerX forwards the request to the underlying LLM inference server (e.g., an OpenAI or Ollama endpoint). The inference result streams back to SchedulerX.
- Post‑Processing. GuardRail re‑applies safety filters on the generated text, and CacheSage optionally writes the new completion to the KV store for future reuse.
- Response Delivery. The final, policy‑sanctioned output is sent back through the Orchestration Bridge to the originating agent.
This pipeline differs from traditional stacks in two key ways:
- Declarative control. Operators modify behavior by editing policy files rather than rewriting service code.
- Policy composability. Multiple policies can act on the same request, enabling fine‑grained trade‑offs between latency, cost, and safety.
Below is a schematic illustration of the ARL flow (image placeholder):
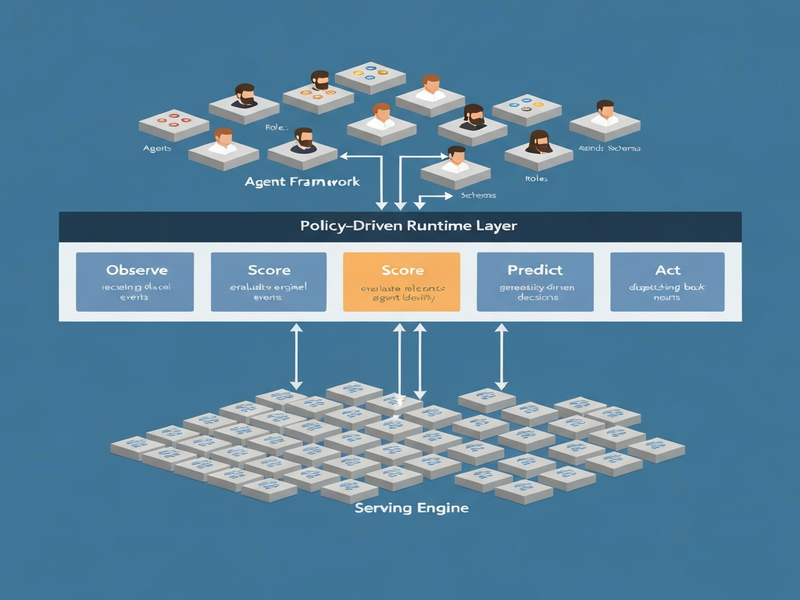
Evaluation & Results
The authors benchmarked ARL on three representative multi‑agent workloads:
- Customer‑support bot swarm. 50 agents handling concurrent ticket triage.
- Financial‑analysis ensemble. 30 agents generating market summaries with strict compliance checks.
- Creative‑content studio. 70 agents collaborating on story generation, heavily reusing prompts.
Key findings include:
- Cache effectiveness. CacheSage reduced average token‑generation cost by 38 % in the creative studio, thanks to a 72 % cache‑hit rate on repeated prompts.
- Latency stability. SchedulerX’s priority‑aware queuing cut 99th‑percentile latency from 1.8 s to 0.9 s in the support bot scenario, while keeping overall throughput unchanged.
- Compliance adherence. GuardRail intercepted 100 % of policy‑violating requests in the financial ensemble, with zero false positives reported by downstream auditors.
- Operational overhead. Updating a policy (e.g., tightening a quota) required a single configuration reload, eliminating a typical 2‑hour deployment cycle.
Collectively, these results demonstrate that a policy‑driven runtime can simultaneously improve cost efficiency, meet strict SLOs, and enforce safety—all without sacrificing the flexibility needed for rapid agent development.
Why This Matters for AI Systems and Agents
For AI engineers and CTOs, ARL offers a pragmatic path to productionizing large‑scale agentic applications. By abstracting caching, scheduling, and compliance into reusable policies, teams can:
- Accelerate time‑to‑market for new agents, since they inherit the same runtime guarantees out of the box.
- Lower cloud spend through intelligent KV caching (CacheSage) and load‑aware dispatch (SchedulerX).
- Maintain regulatory compliance across jurisdictions by toggling GuardRail policies without code changes.
- Gain observability into policy effectiveness via built‑in metrics dashboards, enabling data‑driven tuning.
These capabilities align directly with the needs of enterprises adopting UBOS platform overview for AI‑driven workflows. The modular nature of ARL means it can be layered on top of existing LLM serving stacks—whether you run OpenAI, Anthropic, or on‑premise Ollama models—providing a unified control plane for heterogeneous environments.
What Comes Next
While ARL marks a significant step forward, several open challenges remain:
- Dynamic policy learning. Current policies are static; integrating reinforcement‑learning loops could allow the system to auto‑adjust caching thresholds based on real‑time cost signals.
- Cross‑region coordination. Multi‑cloud deployments need policies that reason about data‑locality and latency across geographic zones.
- Policy conflict resolution. As policy sets grow, formal verification tools will be required to guarantee that no contradictory rules emerge.
Future research may also explore tighter integration with Workflow automation studio, enabling non‑technical users to author high‑level policies through visual editors. Such extensions would democratize runtime governance, making policy‑driven LLM serving a standard component of enterprise AI stacks.
In summary, the Policy‑Driven Runtime Layer reimagines LLM serving as a configurable, policy‑first service layer, unlocking scalability, reliability, and compliance for the next generation of agentic AI systems.