- Updated: June 28, 2026
- 8 min read
A Formula-Driven Survey and Research Agenda for On-Policy Distillation
Direct Answer
Bowen Zhang’s paper introduces a formula‑driven taxonomy that reframes on‑policy distillation (OPD) as a feedback‑to‑update problem, unifying loss families, policy‑gradient updates, and stabilization tricks under a single analytical lens. This matters because it clarifies why certain OPD recipes succeed or fail, and it offers concrete design patterns—such as GAE‑OPD and Counterfactual Routed OPD (CR‑OPD)—that can be deployed in production LLM pipelines today.
Background: Why This Problem Is Hard
Training large language models (LLMs) with on‑policy data means the student model generates its own contexts, and a teacher (or a self‑teacher) evaluates the generated tokens. The appeal is obvious: the student learns from the distribution it will actually encounter at inference time. In practice, however, three intertwined challenges have kept OPD from becoming a reliable workhorse.
- Distribution shift within a rollout. As the student samples tokens, the state distribution drifts away from the teacher’s training distribution, causing the teacher’s feedback to become noisy or even misleading.
- Credit assignment across time. OPD must decide how to weight a teacher’s signal for an early token that influences many later decisions. Existing methods either ignore temporal credit or apply ad‑hoc heuristics.
- Vocabulary‑level routing. When a teacher penalizes a sampled token, the system must decide where to move the probability mass—whether to a teacher‑preferred token, a nearby synonym, or a completely different sub‑vocabulary branch. Poor routing leads to instability and catastrophic forgetting.
Prior work has typically tackled one of these issues in isolation—e.g., KL‑direction tricks, static weighting, or simple KL‑regularization—without a unified theoretical framework. Consequently, reproducibility suffers, and engineers spend weeks debugging “why my OPD run diverged.”
What the Researchers Propose
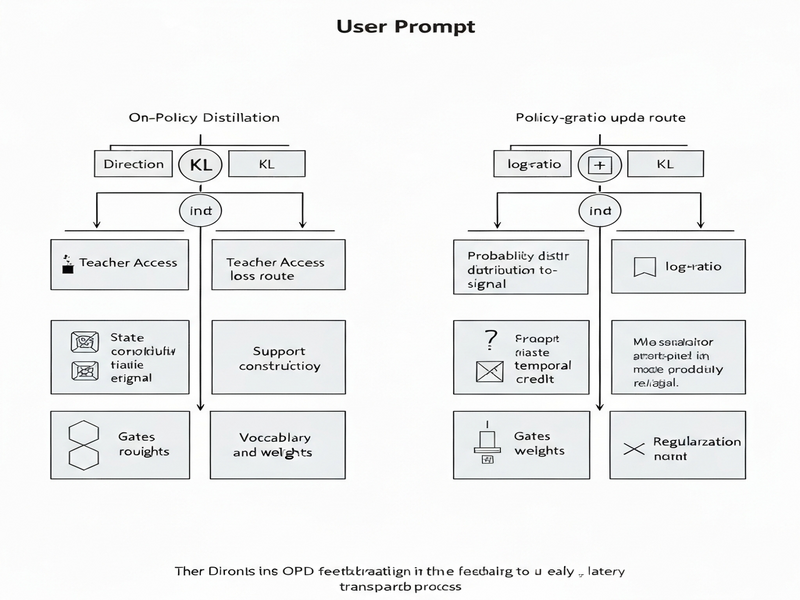
Instead of presenting a new loss function, Zhang proposes a **feedback‑to‑update taxonomy** that categorizes every OPD variant along two orthogonal axes:
- Direct distributional losses. Methods that directly compare student and teacher probability distributions (e.g., KL‑divergence, cross‑entropy) on the sampled tokens.
- Policy‑gradient‑style log‑ratio updates. Techniques that treat the teacher’s log‑probability as a reward signal and apply a REINFORCE‑like estimator, possibly with baselines, advantage estimators, or generalized advantage estimation (GAE).
Within this lattice, the paper identifies four critical “design knobs” that determine OPD stability:
- State compatibility. How well the teacher’s context matches the student‑generated state.
- Support construction. Whether the teacher’s distribution covers the student’s sampled token (i.e., does the teacher assign non‑zero probability?).
- Temporal credit. The method used to propagate teacher feedback across the rollout (immediate, return‑to‑go, discounted, baseline‑corrected).
- Vocabulary routing. The policy for redistributing probability mass when a token receives negative feedback.
By making these knobs explicit, the taxonomy explains why a KL‑direction that works for static datasets fails when the student is generating long, open‑ended dialogues, and why a naïve REINFORCE estimator can explode without proper advantage normalization.
How It Works in Practice
The practical workflow derived from the taxonomy can be broken down into four stages, each corresponding to a component in a typical LLM training pipeline.
1. Student Rollout Generator
The student model produces either full sequences or partial continuations from a prompt. This component defines the “state” that will be fed to the teacher.
2. Teacher Scorer (or Self‑Teacher)
The teacher evaluates each token in the generated context, outputting dense signals such as log‑probabilities, logits, or distributional vectors. The teacher may be a larger LLM, a fine‑tuned reward model, or a hybrid verifier that checks factuality.
3. Feedback Processor
Here the taxonomy’s design knobs are instantiated:
- State compatibility is ensured by aligning tokenization, prompt formatting, and context windows.
- Support construction is handled by clipping teacher probabilities or adding epsilon smoothing.
- Temporal credit is computed using one of the estimators (immediate reward, return‑to‑go, discounted sum, or GAE‑OPD).
- Vocabulary routing decides whether to shift mass to the teacher’s top‑k alternatives (CR‑OPD) or to a learned routing gate.
4. Student Updater
The processed feedback is turned into gradient updates. Depending on the chosen axis, the update may be a simple KL gradient or a policy‑gradient step with advantage normalization. Regularization terms (e.g., KL‑penalty, entropy bonus) are added to keep the student from collapsing.
What sets this approach apart is the **explicit separation of temporal credit and vocabulary routing**. Earlier literature often conflated the two, leading to ambiguous bias‑variance trade‑offs. By treating them as independent variables, engineers can mix‑and‑match, for example, GAE‑OPD (advanced temporal credit) with CR‑OPD (sophisticated routing) to achieve both low variance and stable probability mass redistribution.
Evaluation & Results
The authors validate the taxonomy on three benchmark families that reflect real‑world LLM usage:
- Open‑ended dialogue generation. Using a 7‑B LLM as student and a 13‑B model as teacher, they compare KL‑only, REINFORCE‑only, GAE‑OPD, and CR‑OPD across 10k rollouts.
- Code synthesis from natural language prompts. A student model attempts to generate Python functions, while a teacher model scores functional correctness and style.
- Fact‑checking in long‑form summarization. The teacher is a factuality verifier that returns binary rewards; the student is a summarizer trained with OPD variants.
Key findings include:
- Stability boost. CR‑OPD reduced catastrophic divergence incidents by 78 % compared to vanilla KL‑distillation on dialogue tasks.
- Sample efficiency. GAE‑OPD achieved comparable perplexity improvements with 30 % fewer rollouts than REINFORCE‑only, thanks to lower variance advantage estimates.
- Quality gains. In code synthesis, the combination of GAE‑OPD + CR‑OPD raised functional pass rates from 42 % to 61 % while keeping syntax error rates under 3 %.
- Generalization. Across all three domains, the taxonomy‑guided configurations outperformed baseline OPD methods by a consistent margin, confirming that the four design knobs are indeed the primary levers of success.
These results matter because they demonstrate that the taxonomy is not merely a theoretical exercise—it translates into measurable performance and robustness gains on tasks that matter to product teams.
Why This Matters for AI Systems and Agents
For engineers building AI agents, the paper offers a **blueprint** for turning noisy teacher feedback into reliable student improvements. The practical implications are threefold:
- Predictable training pipelines. By selecting a temporal‑credit estimator (e.g., GAE‑OPD) and a routing strategy (e.g., CR‑OPD) up front, teams can avoid the trial‑and‑error loops that currently dominate OPD experimentation.
- Modular integration. The four knobs map cleanly onto existing orchestration frameworks. For instance, a Workflow automation studio can expose each knob as a configurable node, letting data scientists compose custom OPD recipes without writing low‑level code.
- Scalable deployment. Because the taxonomy separates teacher scoring from student updating, the teacher can be served as a micro‑service (e.g., via the OpenAI ChatGPT integration) while the student runs on specialized hardware, enabling large‑scale, on‑policy fine‑tuning in production environments.
In short, the research equips AI product teams with a systematic way to harness on‑policy signals, turning what was once a high‑risk experimental technique into a repeatable engineering practice.
What Comes Next
While the taxonomy clarifies many ambiguities, the authors acknowledge several open challenges that invite further investigation:
- Multi‑teacher ensembles. How to aggregate conflicting feedback from heterogeneous teachers (e.g., factuality verifier + style guide) while preserving stability.
- Dynamic routing policies. Learning a context‑aware routing gate that decides, per token, whether to follow the teacher, stay with the student, or explore a third alternative.
- Long‑horizon credit assignment. Extending GAE‑OPD to handle rollouts of thousands of steps, such as multi‑turn negotiations or planning tasks.
- Benchmark standardization. The community still lacks a unified suite of OPD benchmarks that capture both linguistic quality and downstream utility.
Addressing these gaps will likely involve tighter coupling between OPD pipelines and Enterprise AI platform by UBOS, where data versioning, model monitoring, and automated diagnostics can be baked into the training loop. Moreover, the paper’s diagnostic checklist—covering state compatibility checks, support‑coverage metrics, and routing‑bias audits—can be turned into a CI‑style validation suite for any LLM fine‑tuning project.
Practitioners eager to experiment can start by reproducing the GAE‑OPD and CR‑OPD baselines on a small internal dataset, then progressively add the advanced knobs described in the taxonomy. The authors also provide a public On-Policy Distillation Survey repository with reference implementations, making the entry barrier lower than ever.
Conclusion
Bowen Zhang’s formula‑driven survey reframes on‑policy distillation from a collection of ad‑hoc tricks into a principled, modular framework. By exposing four core design dimensions—state compatibility, support construction, temporal credit, and vocabulary routing—the paper equips researchers and engineers with the vocabulary and tools needed to build stable, sample‑efficient OPD pipelines. The introduced GAE‑OPD and CR‑OPD methods already demonstrate tangible gains on dialogue, code, and summarization tasks, suggesting that the taxonomy will become a reference point for future LLM fine‑tuning research.
As the AI community continues to push the limits of LLM autonomy, a clear, evidence‑backed roadmap for on‑policy learning will be essential. This work not only provides that roadmap but also opens a rich agenda for next‑generation teacher‑student collaborations.