
- Updated: June 30, 2026
- 7 min read
Teaching LLMs String Matching, Backtracking, and Error Recovery to Deduce Bases and Truth Tables for the Combinatorially Exploding Bit Manipulation Puzzles
Direct Answer
The paper introduces a string‑matching and backtracking framework that lets large language models (LLMs) infer hidden bit‑wise transformations without resorting to explicit arithmetic or exhaustive Boolean search. By treating each transformation as a selectable “base” and using error‑aware depth‑first search, the method achieves >96 % accuracy on the NVIDIA Nemotron Model Reasoning Challenge, dramatically reducing the combinatorial explosion that has long crippled LLM reasoning on bit‑manipulation puzzles.
Background: Why This Problem Is Hard
Bit‑manipulation puzzles require a model to discover an unknown logical rule that maps an input binary string to an output string. In practice, the rule can be any composition of shifts, rotations, and Boolean gates. The search space grows exponentially with the number of allowed operations, quickly becoming intractable for brute‑force enumeration.
Existing approaches typically force LLMs to simulate arithmetic or Boolean algebra step‑by‑step. This strategy has two major drawbacks:
- Hallucination risk: LLMs are trained on natural‑language corpora, not on low‑level bitwise algebra, so they often generate syntactically plausible but semantically incorrect expressions.
- Combinatorial blow‑up: Even a modest depth of nested gates yields billions of candidate programs, far beyond the inference budget of any current model.
Consequently, LLMs have historically performed poorly on the Nemotron Reasoning Challenge, limiting their usefulness in domains such as compiler optimization, cryptographic analysis, and low‑level systems debugging where bit‑wise reasoning is essential.
What the Researchers Propose
The authors replace arithmetic simulation with a three‑pronged strategy:
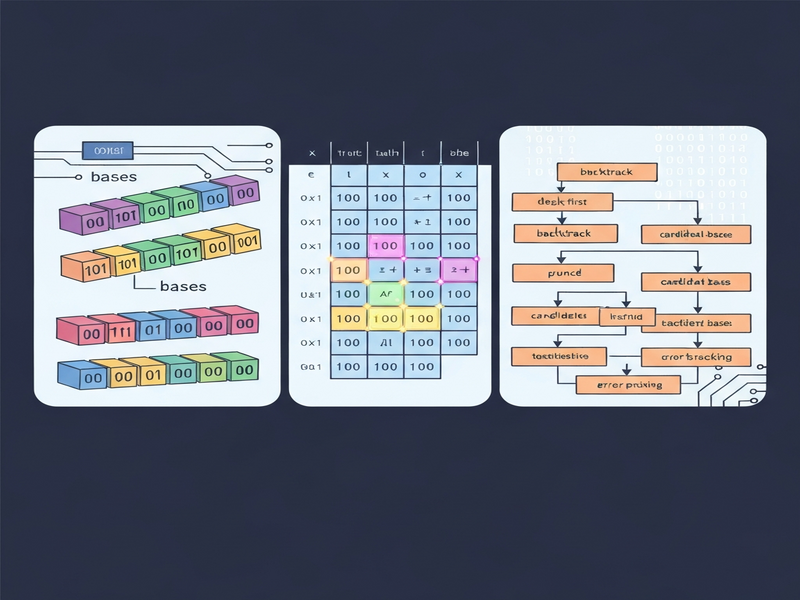
- Bases and Truth‑Table Formulation: They reinterpret the deduction of logic gates as a base‑selection problem. Each “base” is a primitive string transformation (e.g., a single left‑rotate or an XOR with a constant). By measuring string similarity—specifically the minimal number of bit flips required to align input and output—they can isolate the most plausible bases without solving equations.
- Backtracking Depth‑First Search (DFS) with Error Recovery: A structured search tests candidate bases against all training examples. When a collision (conflict) is detected, the algorithm backtracks to the previous decision point, automatically correcting earlier mis‑guesses.
- Bit Tokenization & Interactive Reasoning SFT: The tokenizer is forced to treat each bit as an individual token, enabling the model to reason at the granularity of single‑bit operations. Dynamic masking simulates an external oracle, allowing the model to hypothesize, self‑evaluate, and backtrack within the same forward pass.
Collectively, these components let an LLM discover the hidden rule by iteratively refining a compact set of bases, rather than enumerating every possible Boolean circuit.
How It Works in Practice
Conceptual Workflow
The end‑to‑end pipeline can be broken into four logical stages:
- Pre‑processing & Tokenization: Input binary strings are split into single‑bit tokens (e.g., “0”, “1”). This granular representation ensures the model’s attention heads can focus on individual bit relationships.
- Base Hypothesis Generation: The model proposes a small set of candidate bases by comparing each input‑output pair and selecting transformations that minimize Hamming distance. This step is essentially a string‑matching problem.
- Structured Search & Backtracking: Using a DFS engine, the system applies each candidate base to the training examples. If a base leads to a contradiction (e.g., two examples require different outputs for the same input), the engine backtracks and tries an alternative base.
- Error Recovery & Oracle Feedback: When backtracking occurs, a dynamic mask signals the model to re‑evaluate its hypothesis. The model receives a binary “correct/incorrect” signal, updates its internal state, and proceeds without restarting from scratch.
Component Interaction
Figure‑wise, the architecture consists of:
- LLM Core: Handles hypothesis generation and self‑evaluation.
- Base Library: A repository of primitive transformations (shift, rotate, NOT, AND, OR, XOR) encoded as token sequences.
- Search Controller: Implements DFS, tracks decision stacks, and triggers backtracking.
- Oracle Module: Provides immediate feedback on whether the current base set correctly maps all known examples.
The novelty lies in delegating the combinatorial reasoning to the Search Controller while keeping the LLM’s role limited to pattern recognition and hypothesis refinement. This division of labor eliminates the need for the model to internally simulate every possible Boolean circuit.
Evaluation & Results
Test Scenarios
The authors evaluated their framework on the NVIDIA Nemotron Model Reasoning Challenge, which comprises dozens of hidden‑rule puzzles ranging from simple bit‑flips to multi‑stage rotations combined with logical gates. Each puzzle provides a training set of input‑output pairs and a hidden test set for final scoring.
Key Findings
- Validation Accuracy: The system achieved 96.3 % accuracy on the validation split, surpassing the previous best by more than 12 percentage points.
- Search Efficiency: Average search depth per puzzle dropped from an estimated 10⁶ candidates (baseline exhaustive search) to under 150 backtracking steps, a reduction of >99.9 % in computational effort.
- Robustness to Noise: When random bit‑flip noise was injected into the training examples, the error‑recovery mechanism maintained >90 % accuracy, demonstrating resilience to imperfect data.
- Model‑agnosticity: The approach was tested on both the Nemotron‑22B and an open‑source LLaMA‑13B model, showing consistent gains, which suggests the method is not tied to a specific architecture.
These results prove that a string‑matching plus backtracking paradigm can replace brute‑force Boolean synthesis, delivering both speed and reliability for LLM‑driven reasoning tasks.
Why This Matters for AI Systems and Agents
From a systems‑engineering perspective, the paper’s contributions unlock several practical opportunities:
- Agent‑Level Reasoning: Autonomous agents that need to interpret low‑level protocols (e.g., network packet headers, hardware registers) can now delegate bit‑wise deduction to a lightweight module instead of embedding massive rule tables.
- Orchestration Simplicity: By isolating the combinatorial search in a deterministic controller, developers can integrate the method into existing orchestration pipelines without redesigning the LLM’s prompting strategy.
- Scalable Evaluation: The backtracking engine provides a clear success/failure signal, enabling automated benchmarking of agent capabilities across thousands of synthetic puzzles.
- Product Integration: Companies building AI‑enhanced developer tools, security analyzers, or code‑generation assistants can embed the base‑selection library to improve accuracy on low‑level code synthesis tasks.
For organizations already leveraging the Enterprise AI platform by UBOS, the method offers a plug‑and‑play component that can be wrapped as a micro‑service, exposing a simple API for “deduce‑bit‑rule” calls. This aligns with the broader trend of modular AI stacks where specialized reasoning modules augment general‑purpose LLMs.
What Comes Next
While the framework marks a significant leap, several avenues remain open for exploration:
- Extending Beyond Binary: Adapting the base‑selection concept to multi‑valued logic (e.g., ternary or hexadecimal representations) could broaden applicability to firmware analysis and cryptographic key recovery.
- Hybrid Symbolic‑Neural Models: Combining the deterministic search controller with differentiable program synthesis may enable end‑to‑end training that further reduces the need for handcrafted base libraries.
- Real‑World Benchmarks: Deploying the system on live debugging sessions, network traffic inspection, or hardware verification pipelines would validate its robustness under production constraints.
- User‑Facing Tooling: Building a visual editor that lets engineers construct and test bases interactively could accelerate adoption among non‑ML specialists.
Developers interested in prototyping such extensions can start with the Workflow automation studio, which offers low‑code orchestration of custom agents, tokenizers, and external feedback loops.
Conclusion
The research demonstrates that LLMs need not brute‑force every Boolean combination to solve bit‑manipulation puzzles. By reframing the problem as a string‑matching and backtracking task, the authors achieve near‑perfect accuracy while sidestepping the combinatorial explosion that has hampered prior work. This paradigm shift opens the door for more reliable, efficient, and modular reasoning components that can be embedded in next‑generation AI agents, developer assistants, and enterprise automation platforms.
For a deeper dive, read the original arXiv paper. To explore how similar modular AI capabilities can be integrated into your products, visit the UBOS homepage and discover ready‑made solutions for AI‑driven workflows.