
- Updated: June 28, 2026
- 8 min read
CLI-Universe: Towards Verifiable Task Synthesis Engine for Terminal Agents
Direct Answer
CLI‑Universe is a systematic task‑synthesis engine that builds high‑quality, verifiable terminal‑agent challenges by combining a multi‑dimensional capability taxonomy with evidence‑driven research and a rigorous multi‑stage verification pipeline. It matters because it delivers a compact, 6,000‑trajectory dataset that enables a 32‑billion‑parameter model (Qwen3‑32B) to set a new state‑of‑the‑art on Terminal‑Bench 2.0, proving that carefully engineered synthetic data can dramatically improve data efficiency for LLM‑powered command‑line agents.
Background: Why This Problem Is Hard
Terminal agents—LLMs that can read, write, and execute shell commands—promise to automate DevOps, data‑engineering, and IT support tasks. Yet their progress is throttled by a chronic shortage of reliable training signals:
- Scarcity of executable examples: Public repositories contain many code snippets, but few end‑to‑end command sequences that are both syntactically correct and semantically meaningful.
- Ambiguous instructions: Existing synthetic pipelines often graft natural‑language prompts onto pre‑existing command logs, producing instructions that lack clear intent or contain hidden assumptions.
- Shallow execution paths: Many generated tasks involve a single command or trivial pipelines, offering limited learning signal for multi‑step reasoning.
- Brittle validation: Simple unit tests or string‑matching checks fail to catch subtle failures (e.g., wrong file permissions, environment‑specific errors), leading to noisy supervision.
Because LLMs learn from patterns in the data, noisy or under‑specified tasks cause models to overfit to surface forms rather than develop genuine procedural understanding. This bottleneck is especially acute for open‑source communities that cannot afford massive proprietary datasets.
What the Researchers Propose
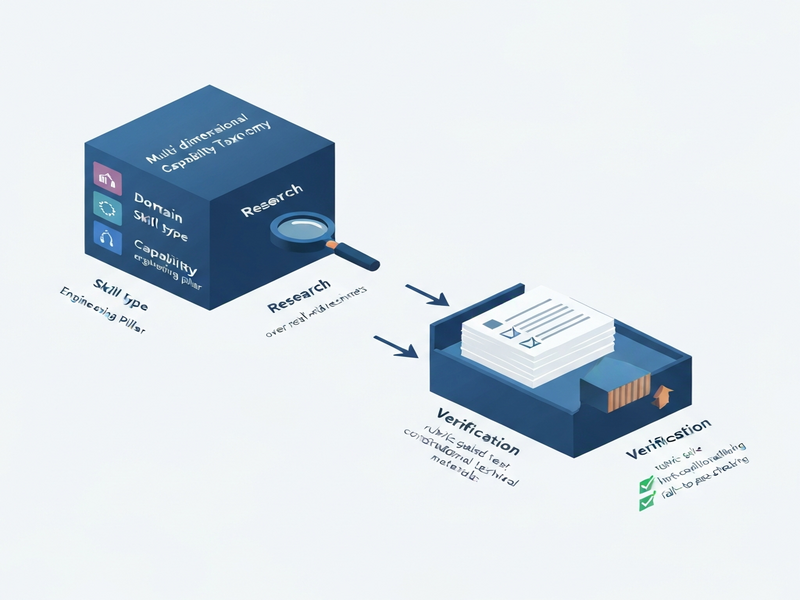
The authors introduce CLI‑Universe, a principled synthesis framework that treats task creation as a research‑driven engineering process rather than a blind random generation. The core ideas are:
- Capability taxonomy: A four‑axis grid (Domain × Skill Type × Capability × Engineering Pillar) that enumerates realistic terminal‑agent competencies, from file‑system manipulation to network diagnostics.
- Evidence‑guided deep research: For each taxonomy cell, the system retrieves real‑world technical documents (man pages, tutorials, GitHub READMEs) and extracts concrete command sequences, ensuring that generated tasks reflect authentic usage patterns.
- Multi‑stage executable verification: A pipeline that (a) builds a Dockerized sandbox, (b) constructs rubric‑gated tests, (c) filters candidates using hint‑conditional heuristics, and (d) enforces a strict fail‑to‑pass rule before a task is admitted.
By integrating domain knowledge, empirical evidence, and rigorous testing, CLI‑Universe filters out roughly two‑thirds of candidate tasks, retaining only those that are genuine, challenging, and fully verifiable.
How It Works in Practice
Conceptual Workflow
- Taxonomy Sampling: The engine randomly selects a combination from the capability grid, defining the high‑level intent of the task (e.g., “compress log files in a Linux environment using streaming tools”).
- Evidence Retrieval: A search module queries a curated corpus of technical resources, pulling snippets that match the selected capability. Natural‑language processing extracts command sequences, arguments, and expected outcomes.
- Blueprint Construction: The retrieved evidence is synthesized into a structured “blueprint” containing:
- Human‑readable instruction
- Step‑by‑step command plan
- Success criteria (file existence, output checksum, exit codes)
- Dockerized Instantiation: Each blueprint spawns an isolated Docker container pre‑loaded with the necessary OS packages, mirroring the environment described in the source material.
- Rubric‑Gated Test Generation: A test generator creates unit‑style checks aligned with the success criteria. Tests are graded against a rubric that rewards completeness, correctness, and non‑triviality.
- Hint‑Conditional Filtering: If a task can be solved with a single hint (e.g., “use tar”), it is discarded to avoid overly easy examples.
- Fail‑to‑Pass Enforcement: The task is executed repeatedly; any failure to meet the rubric results in rejection. Only tasks that consistently pass are added to the final dataset.
Key Differentiators
- Evidence‑first generation: Unlike surface‑level retrofitting, CLI‑Universe grounds every task in real documentation, reducing hallucination.
- Layered verification: The combination of rubric checks, hint filtering, and strict pass criteria creates a high signal‑to‑noise ratio.
- Scalable taxonomy: The four‑dimensional grid can be expanded to new domains (e.g., cloud CLI tools) without redesigning the entire pipeline.
Evaluation & Results
Dataset Construction
The authors instantiated the pipeline to produce CLI‑Universe‑6K, a distilled collection of 6,000 verified trajectories covering a broad spectrum of terminal tasks. Each trajectory includes the natural‑language prompt, the full command trace, and the Docker environment definition.
Benchmarking Methodology
To assess data efficiency, the team fine‑tuned the open‑source Qwen3‑32B model on CLI‑Universe‑6K and evaluated it on the CLI‑Universe paper on arXiv‘s Terminal‑Bench 2.0 suite, which contains 1,200 held‑out tasks spanning the same taxonomy.
- Baseline comparisons: Models trained on generic web‑scraped command logs, as well as larger proprietary agents (e.g., 100B‑parameter models), served as baselines.
- Metrics: Success rate (full task completion), step‑wise accuracy, and execution correctness were recorded.
Key Findings
- Qwen3‑32B achieved a 33.4 % success rate on Terminal‑Bench 2.0, surpassing all open‑source baselines and outperforming several proprietary agents that are an order of magnitude larger.
- The improvement was most pronounced on multi‑step tasks involving conditional logic and file‑system state changes, indicating that the verification pipeline successfully emphasized complex reasoning.
- Ablation studies showed that removing any verification stage (e.g., hint filtering) reduced performance by 5–8 percentage points, confirming the importance of each pipeline component.
These results demonstrate that a well‑engineered synthetic dataset can close the gap between modest‑size open models and heavyweight commercial systems, highlighting the value of data quality over sheer quantity.
Why This Matters for AI Systems and Agents
For practitioners building terminal‑oriented AI assistants, CLI‑Universe offers several practical takeaways:
- Data‑efficient fine‑tuning: High‑fidelity synthetic tasks can dramatically boost performance without the need for costly human annotation or large‑scale web crawling.
- Robust evaluation scaffolding: The Docker‑based verification framework can be repurposed as a test harness for any new agent, ensuring that deployments are safe before hitting production environments.
- Modular taxonomy extension: Teams can plug in domain‑specific CLI tools (e.g., AWS CLI, Kubernetes kubectl) by expanding the taxonomy, instantly generating relevant training material.
- Integration with existing AI platforms: The dataset’s JSON‑L format aligns with popular orchestration tools, making it straightforward to feed into pipelines such as the UBOS platform overview or the Workflow automation studio.
In short, CLI‑Universe shifts the bottleneck from “where do we find data?” to “how do we verify that the data truly reflects real‑world command‑line challenges?” This paradigm enables faster iteration cycles for AI agents that need to interact with operating systems, cloud services, and developer tools.
What Comes Next
While CLI‑Universe marks a significant step forward, several avenues remain open for exploration:
Limitations
- Domain coverage: The current taxonomy focuses on Unix‑like environments; Windows PowerShell or container orchestration CLIs are under‑represented.
- Dynamic external services: Tasks that depend on live APIs (e.g., fetching remote data) are difficult to sandbox reliably.
- Human‑in‑the‑loop refinement: Although the pipeline is automated, occasional manual curation could further improve edge‑case realism.
Future Research Directions
- Extending the taxonomy to cover OpenAI ChatGPT integration scenarios, enabling agents that can seamlessly switch between natural‑language and CLI modalities.
- Incorporating ElevenLabs AI voice integration to generate multimodal tasks where agents must interpret spoken commands before executing terminal actions.
- Leveraging the Chroma DB integration for semantic retrieval of past task executions, facilitating few‑shot learning within the same session.
- Building a community‑driven repository of taxonomy extensions, similar to open‑source plugin ecosystems, to accelerate coverage of emerging DevOps tools.
Potential Applications
Enterprises can adopt CLI‑Universe‑style pipelines to generate internal training data for compliance‑aware automation bots, while startups may use the dataset to bootstrap AI‑assisted developer assistants. The approach also aligns with the Enterprise AI platform by UBOS, which emphasizes secure, containerized execution of AI workloads.
Conclusion
CLI‑Universe demonstrates that a disciplined, evidence‑driven synthesis engine can produce a compact yet powerful dataset that elevates the capabilities of mid‑scale language models in the terminal‑agent domain. By marrying a rich capability taxonomy with rigorous verification, the framework delivers data efficiency gains that rival much larger proprietary solutions. As AI agents continue to migrate from chat‑only interfaces to full‑stack system orchestration, the need for trustworthy, executable training material will only grow—making CLI‑Universe a blueprint for the next generation of synthetic data pipelines.
For developers interested in experimenting with the dataset or integrating the verification pipeline into their own workflows, explore the UBOS templates for quick start and the UBOS partner program for collaborative opportunities.