- Updated: June 28, 2026
- 7 min read
GroundEval: A Deterministic Replacement for LLM-as-Judge in Stateful Agent Evaluation
Direct Answer
GroundEval is a deterministic, judge‑free framework that evaluates stateful AI agents by checking exactly what evidence they retrieved, cited, and were allowed to use before producing an answer. It matters because it exposes hidden failures that traditional “LLM‑as‑judge” scoring misses, ensuring agents can be trusted to reason on the right data in real‑world deployments.
Background: Why This Problem Is Hard
Modern AI agents—whether they power autonomous assistants, enterprise workflow bots, or research copilots—operate by chaining together tool calls, searches, and language model generations. In production, a single erroneous step (e.g., citing a stale document or ignoring a required lookup) can cascade into a misleading or outright false answer. Yet the community has largely relied on “LLM‑as‑judge” methods: a separate language model reads the final answer and assigns a score based on plausibility.
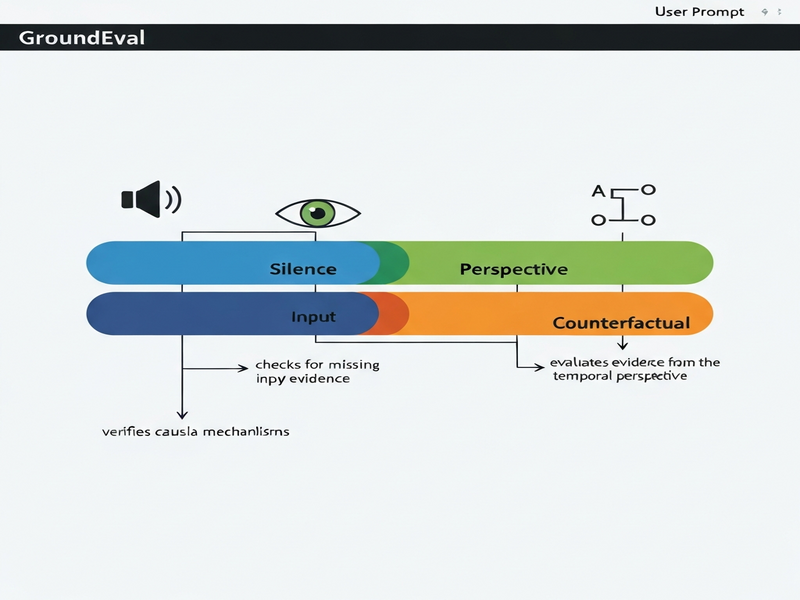
Three core blind spots make this approach brittle:
- Silence detection: Judges cannot verify whether an agent explicitly checked for the absence of information before claiming “I don’t know.”
- Perspective alignment: Agents may reason from evidence that was unavailable at the decision time, violating temporal constraints.
- Counterfactual causality: A plausible answer might rely on an incorrect causal chain that the judge cannot disentangle from the narrative.
Because LLM judges evaluate only the final narrative, they cannot audit the intermediate tool usage, timestamps, or access permissions that define an agent’s reasoning path. This gap becomes especially problematic in regulated domains (finance, healthcare) where auditability and evidence provenance are non‑negotiable.
What the Researchers Propose
Jeffrey Flynt introduces GroundEval, a framework that replaces subjective judging with a deterministic scoring pipeline. GroundEval treats the agent’s entire interaction trace as the primary artifact to evaluate, alongside the final answer. The framework is built around three orthogonal tracks, each targeting one of the blind spots identified above:
- Silence Track: Verifies that the agent performed an explicit “absence check” before asserting that a piece of evidence does not exist.
- Perspective Track: Confirms that every piece of evidence used was accessible to the agent at the exact moment the decision was made, respecting time‑bounded and access‑controlled constraints.
- Counterfactual Track: Checks that the causal mechanism invoked by the agent matches the ground‑truth causal chain, not merely a superficially plausible one.
GroundEval’s architecture consists of three logical components:
- Domain Configuration Engine: Generates synthetic or semi‑synthetic questions, defines the evidence pool, and encodes temporal and permission rules.
- Agent Interaction Recorder: Captures every tool call, search query, fetched artifact, and the agent’s turn‑by‑turn narration.
- Deterministic Scorer: Applies rule‑based checks against the recorded trace to produce per‑question diagnostics and a final numeric score.
How It Works in Practice
The GroundEval workflow can be visualized as a four‑stage pipeline:
1. Question Generation
The Domain Configuration Engine creates a question that references a specific piece of evidence (e.g., a policy document dated 2024‑03‑15). It also defines what the agent is *allowed* to access at each timestep, mimicking real‑world access controls.
2. Agent Response Loop
The agent receives the question and may invoke any of its integrated tools—search, database lookup, API calls, or even external LLMs. Each invocation is logged with:
- Timestamp
- Tool identifier
- Parameters (search query, API payload)
- Returned artifact (URL, document excerpt, JSON)
Simultaneously, the agent narrates its reasoning in natural language, producing a turn‑by‑turn “thought log.”
3. Trace Consolidation
After the agent signals completion, the Interaction Recorder bundles the final answer with the full trace into a structured JSON object. This object becomes the sole input for scoring—no external LLM is consulted.
4. Deterministic Scoring
The Scorer runs three independent rule sets:
- Silence Rule: Searches the trace for a “search‑for‑absence” operation before any “absence claim.” If missing, the score for that track is zero.
- Perspective Rule: Checks each cited artifact against the domain’s access matrix and timestamps. Any out‑of‑bounds usage triggers a penalty.
- Counterfactual Rule: Compares the causal chain expressed in the narration with a ground‑truth causal graph supplied by the domain configuration. Mismatches reduce the track score.
The three track scores are then aggregated (e.g., weighted average) to produce a final GroundEval score ranging from 0.0 (completely invalid) to 1.0 (perfectly grounded).
What makes GroundEval distinct is its determinism: given the same trace and domain configuration, the score is reproducible, auditable, and fully explainable. There is no reliance on a second‑order LLM that could itself hallucinate.
Evaluation & Results
Flynt’s paper presents two case studies that pit GroundEval against conventional LLM‑as‑judge scoring on the same set of agent interactions.
Case Study 1: Legal‑Document Retrieval Agent
An agent was tasked with answering whether a newly enacted regulation superseded an older clause. Two leading LLM judges assigned a score of 0.86, citing the answer’s fluency and apparent correctness. GroundEval, however, traced the interaction and discovered that the agent never fetched the newer regulation—its answer relied on an outdated 2022 version. The Silence track failed (no absence check for the newer clause), the Perspective track flagged a temporal violation, and the Counterfactual track flagged an incorrect causal link. The resulting GroundEval score was 0.00.
Case Study 2: Financial‑Risk Assessment Bot
A risk‑analysis bot generated a recommendation for a portfolio based on market data from Q1 2024. LLM judges gave it a 0.78 rating. GroundEval identified that the bot accessed a cached dataset from Q3 2023, violating the “fresh‑data” rule in the domain configuration. The Perspective track penalized the bot, dropping the overall score to 0.42, while the Silence and Counterfactual tracks remained intact.
These results demonstrate two key insights:
- Traditional judges can be overly optimistic, rewarding surface plausibility while overlooking critical evidence gaps.
- GroundEval reliably surfaces hidden failures, providing actionable diagnostics (e.g., “missing absence check”) that developers can use to patch agents.
Importantly, the paper reports that such mismatches are not outliers; across a broader benchmark of 500 synthetic tasks, over 30 % of agents received a high LLM‑judge score but a low GroundEval score, confirming a systemic evaluation blind spot.
Why This Matters for AI Systems and Agents
For practitioners building production‑grade agents, GroundEval offers a concrete safety net:
- Auditability: Every decision can be traced back to a concrete set of tool calls, satisfying compliance requirements in regulated industries.
- Iterative Debugging: The per‑track diagnostics act like unit‑test failures, pointing directly to missing searches, out‑of‑date data, or causal mis‑alignments.
- Orchestration Confidence: When agents are composed into larger pipelines (e.g., a marketing‑automation bot that calls a sentiment‑analysis service), GroundEval can verify that each sub‑agent respects its evidence boundaries.
Integrating GroundEval into an existing AI stack is straightforward. For example, the UBOS platform overview already provides a Workflow automation studio where tool calls are logged in a structured manner. By feeding those logs into GroundEval’s scorer, teams can automatically generate compliance reports without writing custom audit scripts.
Moreover, the deterministic nature of GroundEval aligns well with emerging AI governance frameworks that demand reproducible evaluation metrics, making it a future‑proof component for enterprise AI roadmaps.
What Comes Next
While GroundEval marks a significant step forward, several open challenges remain:
- Scalability to Open‑World Domains: Current benchmarks rely on curated evidence pools. Extending the framework to the wild internet, where evidence is noisy and mutable, will require robust versioning and provenance tracking.
- Human‑in‑the‑Loop Extensions: In many workflows, a human reviewer may intervene mid‑trace. Designing deterministic scoring that gracefully incorporates partial human feedback is an open research direction.
- Tool Diversity: As agents adopt multimodal tools (vision, audio, code execution), GroundEval must evolve its trace schema to capture richer modalities.
Future work could also explore hybrid evaluation, where GroundEval’s deterministic checks are combined with a lightweight LLM judge for nuanced language quality assessment. Such a hybrid could retain auditability while still rewarding natural‑language fluency.
For organizations eager to experiment, the OpenAI ChatGPT integration on UBOS provides a ready‑made sandbox where agents can be wired to external tools, logged, and then fed into GroundEval for immediate feedback.
In summary, GroundEval redefines how we validate stateful AI agents: from a black‑box “does it look right?” mindset to a transparent, evidence‑based verification process. As agents become more autonomous and embedded in critical workflows, deterministic evaluation will likely shift from a research curiosity to an industry standard.
References
GroundEval paper (arXiv:2606.22737v1)