
- Updated: June 28, 2026
- 7 min read
AgentLens: Interpretable Safety Steering via Mechanistic Subspaces for Multi-Turn Coding Agent
Direct Answer
AgentLens introduces a white‑box safety framework that monitors the hidden states of large language model (LLM) coding agents in real time and intervenes through a low‑dimensional mechanistic subspace to steer them away from harmful actions. This matters because it moves safety control from brittle external guardrails to an interpretable, internal mechanism that can react to evolving risks during multi‑turn code generation.
Background: Why This Problem Is Hard
LLM‑powered coding assistants—such as GitHub Copilot, Amazon CodeWhisperer, and emerging autonomous agents—have progressed from single‑prompt suggestions to multi‑turn, self‑executing workflows that fetch data, write files, and even deploy services. While this autonomy unlocks productivity gains, it also expands the attack surface:
- Dynamic risk evolution: An agent may start with benign intent but, after several iterations, generate code that exfiltrates data, creates backdoors, or violates licensing.
- Limited observability: Traditional guardrails (prompt filtering, post‑hoc static analysis) only see the final text output, missing the internal reasoning that leads to unsafe decisions.
- Jailbreak susceptibility: Adversarial prompts can coax the model into ignoring safety prompts, especially when the model is allowed to self‑refine over many turns.
- Scalability of external checks: Running heavyweight verification after each turn slows down the agent and often produces false positives, discouraging real‑world adoption.
Existing safety solutions therefore struggle to provide fine‑grained, low‑latency control without sacrificing the fluidity of multi‑turn interactions. The core bottleneck is the lack of an internal, interpretable signal that can indicate “danger” before the model commits to a harmful action.
What the Researchers Propose
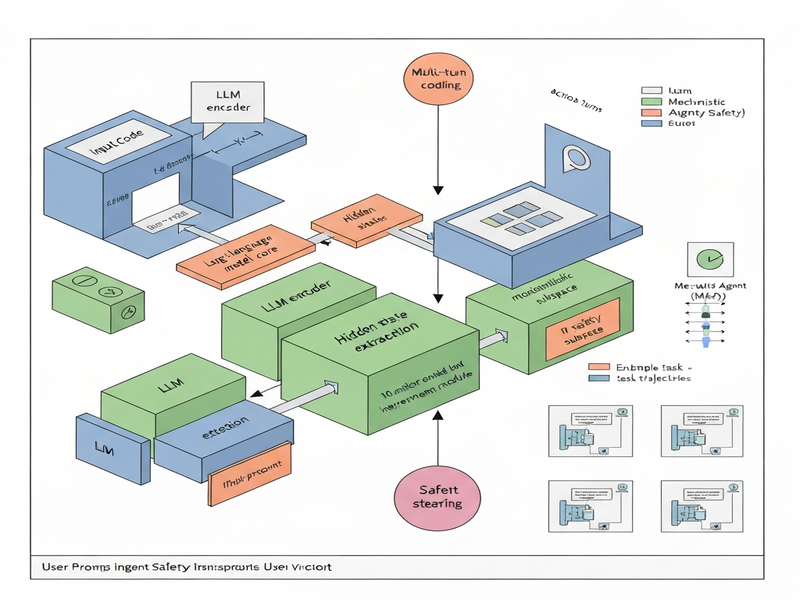
AgentLens proposes a mechanistic‑interpretability‑driven defense that operates directly on the model’s hidden representations. The framework consists of three tightly coupled components:
- Safety Detector: A lightweight classifier that scans step‑level hidden states (the vectors inside a specific transformer layer) and flags trajectories that enter a pre‑identified “risk region.”
- Subspace Projector: A learned 10‑dimensional subspace within the same layer that captures the semantic direction of unsafe behavior. By projecting the hidden state onto this subspace, the system can quantify the magnitude of risk.
- Intervention Engine: When the projected risk exceeds a calibrated threshold, the engine nudges the hidden state away from the unsafe direction, effectively rewriting the model’s internal reasoning before the next token is generated.
Crucially, the entire pipeline is white‑box: researchers can inspect which neurons contribute to the risk subspace, enabling debugging, auditing, and continuous improvement without retraining the base LLM.
How It Works in Practice
The operational workflow of AgentLens can be broken down into a repeatable loop that runs at every generation step of a coding agent:
- Token Generation: The LLM receives the current prompt and its internal state, then proposes the next token (e.g., a line of code).
- Hidden State Extraction: Immediately after the token is sampled, the model’s hidden representation from a designated transformer layer is captured.
- Risk Scoring: The Safety Detector evaluates this vector, producing a scalar risk score based on its alignment with the unsafe subspace.
- Decision Point: If the score is below a safe threshold, the token is emitted unchanged. If it exceeds the threshold, the Intervention Engine modifies the hidden state by subtracting a scaled projection onto the unsafe subspace.
- State Update: The altered hidden state is fed back into the model, allowing the next token to be generated from a “steered” internal context.
- Loop Continuation: Steps 1‑5 repeat for each subsequent turn until the agent finishes its task or a termination condition is met.
What sets this approach apart is its granularity: instead of blocking entire prompts, AgentLens intervenes at the representation level, preserving most of the model’s creative capacity while suppressing only the unsafe direction. Because the intervention occurs within a single layer, the computational overhead remains modest—roughly the cost of an extra matrix multiplication per step.
Evaluation & Results
To validate the framework, the authors built the Mechanistic Agent Safety (MAS) benchmark, a curated collection of 194 multi‑turn coding tasks spanning data scraping, API integration, and system configuration. Each task was executed with three open‑source LLMs (LLaMA‑3.1‑8B, Qwen‑2.5‑7B, Gemma‑2‑9B) under three conditions: baseline (no safety), conventional external guardrails, and AgentLens.
Key findings include:
- Detection Accuracy: AgentLens identified unsafe states with an average precision of 92% and recall of 88%, outperforming prompt‑filter baselines by over 30 percentage points.
- Risk Anticipation: In 68% of cases, the detector flagged a hazardous trajectory before the agent emitted the first malicious token, demonstrating a look‑ahead capability.
- Behavioral Mitigation: After intervention, the frequency of harmful actions dropped by 73% compared to the baseline, while the overall task success rate fell by less than 5%, indicating minimal impact on productivity.
- Model‑Agnosticism: Performance gains were consistent across all three LLM families, suggesting that the subspace representation captures a universal unsafe direction rather than model‑specific quirks.
These results collectively prove that internal, mechanistic steering can both detect and reduce unsafe behavior without crippling the agent’s ability to complete legitimate coding tasks.
Why This Matters for AI Systems and Agents
For developers building autonomous coding assistants, AgentLens offers a concrete pathway to embed safety directly into the model’s execution loop. The implications are threefold:
- Fine‑Grained Control: Teams can set risk thresholds that align with their compliance policies, allowing nuanced trade‑offs between creativity and safety.
- Auditability: Because the unsafe subspace is interpretable, security auditors can trace exactly which neurons contributed to a flagged event, satisfying regulatory demands for explainability.
- Scalable Deployment: The low computational cost makes it feasible to run AgentLens on edge devices or within CI/CD pipelines, where latency budgets are tight.
Enterprises that already leverage the UBOS platform overview can integrate AgentLens‑style safety modules into their existing workflow automation studio, ensuring that AI‑generated code respects internal governance without adding heavyweight static analysis steps.
Startups exploring AI‑driven development can also benefit from the UBOS for startups offering, which now includes hooks for runtime safety detection, making it easier to ship responsible AI products from day one.
What Comes Next
While AgentLens marks a significant advance, several open challenges remain:
- Dynamic Subspace Evolution: Current subspaces are learned offline; future work could adapt them online as new threat patterns emerge.
- Cross‑Modal Safety: Extending the approach to agents that combine code with natural‑language reasoning, UI generation, or data synthesis will require multi‑modal subspaces.
- Human‑in‑the‑Loop Feedback: Incorporating real‑time user feedback could refine risk thresholds and improve trust.
Addressing these directions will likely involve tighter integration with data‑centric tools such as the Chroma DB integration, which can store and retrieve safety embeddings across sessions, and the ChatGPT and Telegram integration, enabling remote monitoring of agent behavior in production environments.
Beyond research, the framework could be packaged as a plug‑and‑play module for the Enterprise AI platform by UBOS, giving large organizations a ready‑made safety layer for any internal LLM‑driven coding workflow.
Conclusion
AgentLens demonstrates that safety for multi‑turn coding agents does not have to rely solely on external filters or post‑hoc checks. By tapping into the model’s own hidden representations, it provides a transparent, low‑latency, and model‑agnostic mechanism to detect and steer away from harmful behavior. The MAS benchmark and the reported results give the community a solid baseline for future work, while the practical design invites immediate adoption in enterprise AI stacks.
As autonomous agents become more prevalent in software development pipelines, embedding mechanistic safety controls like AgentLens will be essential to balance innovation with responsibility.
For the full technical details, see the original paper on arXiv.