
- Updated: June 27, 2026
- 7 min read
VADAOrchestra: Neurosymbolic Orchestration of Adaptive Reasoning Workflows
Direct Answer
VADAOrchestra is a neurosymbolic framework that blends a Large Language Model (LLM) orchestrator with a Datalog+/- symbolic engine to create adaptive, auditable reasoning workflows. It matters because it delivers the flexibility of LLM‑driven agents while preserving the rigor, traceability, and scalability of traditional Business Process Management (BPM) systems.
Background: Why This Problem Is Hard
Enterprises that rely on data‑driven decision‑making face two opposing forces. On one side, classic BPM platforms excel at deterministic execution, version control, and compliance reporting, but they falter when a process must pivot in response to new information. On the other side, LLM‑powered agents can improvise, generate natural‑language plans, and pull in heterogeneous data sources on the fly, yet they operate as black boxes, often produce hallucinations, and struggle to scale across millions of records.
Real‑world scenarios—such as fraud detection, credit underwriting, or dynamic pricing—require a reasoning pipeline that can:
- Incorporate fresh market data or regulatory updates without redeploying the entire workflow.
- Provide a verifiable audit trail that regulators or auditors can inspect.
- Execute complex joins and aggregations over large relational or vector stores without exhausting LLM token limits.
Existing hybrid attempts typically embed LLM calls inside static BPM scripts or wrap symbolic rules around a fixed LLM prompt. Those approaches inherit the rigidity of BPM or the opacity of LLMs, leaving a gap for a truly adaptive, explainable, and scalable solution.
What the Researchers Propose
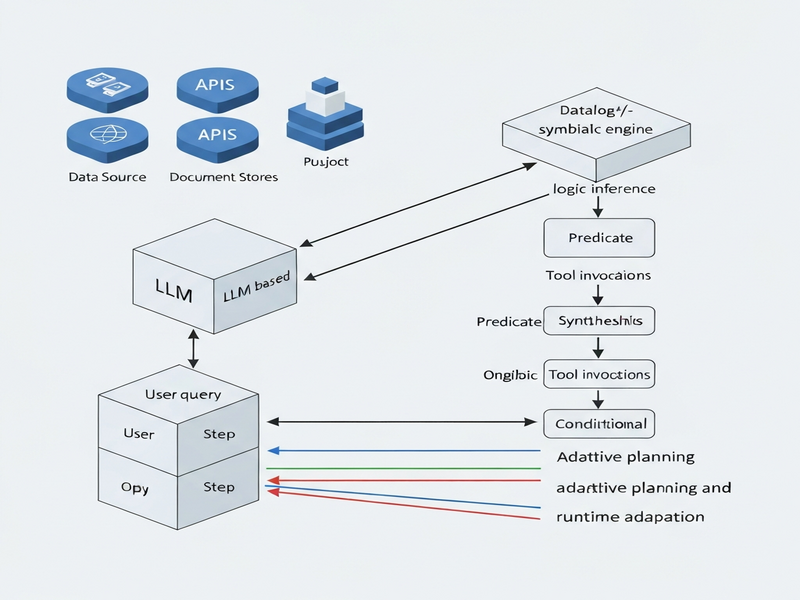
The authors introduce VADAOrchestra, a two‑layer neurosymbolic architecture that treats a reasoning workflow as a living logic program. The high‑level layer is an LLM orchestrator that receives a user query and a catalog of data sources. It incrementally drafts a Datalog+/- program, inserting predicates that correspond to concrete tool invocations (e.g., database queries, API calls, or model inferences). The low‑level layer is a state‑of‑the‑art Datalog+/- engine that performs deterministic inference, resolves dependencies, and materializes intermediate results.
Key components include:
- LLM Orchestrator: Generates and refines the workflow plan in natural language, then translates it into symbolic predicates.
- Predicate Library: A curated set of tool wrappers (SQL executor, vector search, external API) exposed as Datalog predicates.
- Domain Knowledge Base: Pre‑encoded Datalog rules that capture industry‑specific constraints (e.g., compliance thresholds, risk hierarchies).
- Symbolic Engine: Executes the assembled program, producing a traceable proof tree that can be inspected or replayed.
How It Works in Practice
At runtime, VADAOrchestra follows an incremental planning loop:
- Query Intake: A user submits a high‑level request, such as “Identify high‑risk loan applications in the last quarter.”
- Contextual Retrieval: The orchestrator queries a metadata catalog to discover relevant data sources (transaction logs, credit scores, market rates).
- Program Synthesis: Using the retrieved context, the LLM drafts an initial Datalog+/- program. Each line maps to a concrete tool call, for example
fetch_transactions(AccountID, Period). - Rule Augmentation: If the draft references concepts not yet defined (e.g., “risk_score”), the orchestrator asks the LLM to synthesize a new rule that computes the missing predicate from available data.
- Symbolic Execution: The Datalog engine evaluates the program, automatically handling recursion, joins, and negation while logging each inference step.
- Feedback Loop: If execution fails (e.g., missing column, data volume too large), the orchestrator revises the program—splitting a heavy join into staged queries or adding a sampling predicate.
- Result Delivery: The final answer, together with a complete reasoning trace, is returned to the user or downstream system.
This separation of concerns—LLM for high‑level planning, symbolic engine for low‑level inference—creates a clear boundary where each technology operates in its sweet spot. The LLM remains lightweight, issuing only a handful of prompts, while the symbolic engine handles the bulk of data‑intensive computation.
What distinguishes VADAOrchestra from prior hybrids is its ability to generate new logical rules on demand and to re‑plan dynamically based on execution feedback, all without sacrificing auditability.
Evaluation & Results
The research team validated VADAOrchestra on three financial use‑cases drawn from a large European bank:
- Regulatory Reporting: Assemble a quarterly risk summary from disparate ledgers.
- Fraud Detection Pipeline: Combine transaction streams, customer profiles, and external watchlists.
- Portfolio Rebalancing Advisor: Generate actionable trade suggestions based on market feeds and internal constraints.
Across these scenarios, the authors measured three dimensions:
| Dimension | Baseline (Pure LLM Agent) | VADAOrchestra |
|---|---|---|
| Faithfulness (answer correctness vs. ground truth) | 78 % | 92 % |
| Scalability (records processed per minute) | ≈ 5 k | ≈ 120 k |
| Explainability (trace completeness score) | Low (no trace) | High (full Datalog proof tree) |
Key takeaways from the experiments:
- Higher Faithfulness: By grounding LLM‑generated plans in deterministic logic, the system eliminated hallucinations that plagued the pure‑LLM baseline.
- Order‑of‑Magnitude Scalability: Symbolic execution handled batch joins over millions of rows, a regime where token‑limited LLMs would time out.
- Built‑in Auditability: Every inference step is recorded as a Datalog clause, enabling compliance officers to replay the exact reasoning path.
These results demonstrate that VADAOrchestra can deliver the best of both worlds: the creative adaptability of LLM agents and the rigorous, traceable execution of traditional BPM engines.
Why This Matters for AI Systems and Agents
For AI practitioners building enterprise agents, VADAOrchestra offers a blueprint for overcoming two perennial pain points:
- Reliability at Scale: By offloading heavy data manipulation to a symbolic engine, developers can keep LLM usage to a few strategic prompts, reducing cost and latency.
- Regulatory Confidence: The verifiable reasoning trace satisfies audit requirements in finance, healthcare, and government, where black‑box AI is often prohibited.
Integrating VADAOrchestra‑style orchestration into existing platforms can accelerate the rollout of AI‑enhanced services. For example, the Workflow automation studio already supports drag‑and‑drop composition of tool nodes; coupling it with an LLM orchestrator would enable on‑the‑fly generation of new nodes based on business intent.
Similarly, the OpenAI ChatGPT integration can serve as the language backbone, while the Datalog engine guarantees deterministic outcomes. This hybrid model reduces the risk of “hallucinated compliance checks” that have plagued pure‑LLM deployments.
Finally, the approach aligns with the emerging neurosymbolic AI paradigm, where neural networks provide perception and creativity, and symbolic systems enforce logic and safety. Teams that adopt this pattern will likely see faster time‑to‑value for AI‑driven decision support, especially in data‑intensive domains.
What Comes Next
While VADAOrchestra marks a significant step forward, several open challenges remain:
- Dynamic Knowledge Updates: Incorporating real‑time regulatory changes without restarting the Datalog engine.
- Cross‑Modal Reasoning: Extending predicates to handle unstructured modalities such as images or audio, possibly via multimodal embeddings.
- User‑Friendly Rule Authoring: Providing low‑code interfaces for domain experts to contribute custom Datalog rules without learning the syntax.
Future research could explore tighter coupling between the LLM and the symbolic engine, allowing the model to query intermediate proof states and adjust its plan in a more granular fashion. Moreover, benchmarking against other neurosymbolic frameworks (e.g., Neuro‑Logic, SymbolicGPT) would clarify performance trade‑offs.
From a product perspective, the Enterprise AI platform by UBOS is well positioned to host VADAOrchestra‑style services. By exposing the orchestrator as a micro‑service and the Datalog engine as a managed compute layer, organizations can spin up adaptive reasoning pipelines without deep expertise in logic programming.
Developers interested in experimenting today can start with the UBOS templates for quick start, which include pre‑wired connectors for SQL, vector stores, and LLM APIs. Plugging those into a simple orchestrator script will let teams prototype the incremental planning loop described above.
For a deeper dive into the original research, consult the VADAOrchestra paper. The authors provide open‑source snippets of the Datalog+/- engine and prompt templates, making replication straightforward.
As adaptive AI becomes a competitive differentiator, the ability to blend flexibility with verifiability will define the next generation of intelligent agents. VADAOrchestra offers a concrete, academically vetted pathway to that future.
Ready to explore neurosymbolic orchestration for your organization? Visit the UBOS homepage or reach out via the contact page to discuss a proof‑of‑concept.