
- Updated: June 26, 2026
- 6 min read
Holmes: Multimodal Agentic Diagnosis for Mixed-Language Mobile Crashes at Industrial Scale
Direct Answer
Holmes is a multi‑agent system that automatically diagnoses the root cause of mobile crashes in massive, mixed‑language codebases without needing to reproduce the failure. By fusing stack traces, logs, thread states, and low‑level runtime artifacts, Holmes pinpoints faulty functions in seconds, cutting investigation time by more than 98%.
Background: Why This Problem Is Hard
Modern mobile applications—especially those serving billions of users—are built from millions of lines of code written in Java, Kotlin, C++, Objective‑C, and native assembly. When a crash occurs in the field, engineers face three intertwined challenges:
- Scale. A single crash report may map to a codebase exceeding 70 million lines, making manual triage infeasible.
- Mixed‑language semantics. Business logic lives in high‑level languages, while the failure often propagates through low‑level system frameworks that are closed‑source or heavily optimized.
- Non‑reproducibility. Many crashes happen only on specific device configurations, network conditions, or user actions that cannot be recreated in a lab environment.
Traditional static analysis tools struggle with the sheer size of the code and cannot reason about dynamic state. Existing LLM‑driven debugging agents assume a reproducible sandbox where they can run the program, inspect variables, and iterate. In post‑mortem scenarios—where only logs and stack traces survive—those agents hit a dead end.
What the Researchers Propose
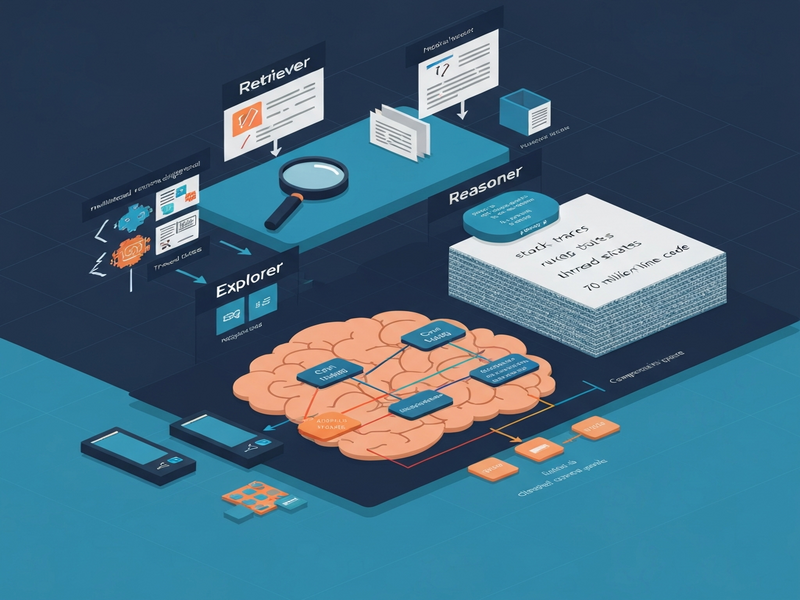
The authors introduce Holmes, a hierarchical “Retrieve‑Explore‑Reason” (R‑E‑R) framework that orchestrates several specialized agents to reconstruct a crash context from multimodal signals. The key components are:
- Retriever Agent. Scans the raw crash dump (stack trace, log snippets, thread dumps) and extracts a concise set of “runtime clues” such as register values, native addresses, and exception messages.
- Explorer Agent. Uses the clues to perform a focused search across the code repository, dynamically compressing the search space by pruning irrelevant modules and expanding only the regions that match low‑level artifacts.
- Reasoner Agent. Synthesizes the retrieved code fragments, execution context, and domain knowledge (e.g., known framework bugs) to generate a ranked list of candidate fault locations at the function level.
Each agent is powered by a large language model fine‑tuned on internal debugging data, but they communicate through a shared knowledge graph that preserves provenance and enables back‑tracking.
How It Works in Practice
The end‑to‑end workflow can be visualized as a three‑stage pipeline:
- Signal Ingestion. When a crash report lands in the monitoring system, Holmes parses the raw text and binary artifacts, normalizing them into a structured multimodal payload.
- Retrieve Phase. The Retriever Agent isolates high‑signal items—e.g., a native address “0x7f3a2c1b” that appears in both the stack trace and a log line. It also maps these addresses to symbol tables when available.
- Explore Phase. Guided by the retrieved clues, the Explorer Agent queries a code index that stores both source files and compiled binaries. It performs a “semantic narrowing” by matching assembly patterns to source‑level constructs, effectively bridging the gap between open‑source business logic and closed‑source system frameworks.
- Reason Phase. The Reasoner Agent assembles a causal chain: it links the low‑level fault (e.g., a null‑pointer dereference in a native library) to the high‑level call site that triggered it. It then produces a concise explanation and a confidence score for each candidate function.
- Actionable Output. The final report is delivered to the engineering dashboard, highlighting the most probable faulty function, the supporting evidence, and suggested remediation steps.
What sets Holmes apart is its ability to compress the search space on the fly. Instead of scanning the entire 70‑million‑line repository, the Explorer Agent narrows the focus to a few hundred lines that are directly implicated by the runtime clues. This dynamic pruning is what enables sub‑minute diagnosis.
Evaluation & Results
The research team evaluated Holmes on a production dataset collected from WeChat, one of the world’s largest mobile platforms. The dataset comprised 12,342 real‑world crashes that had previously required manual investigation.
- Accuracy. Holmes correctly identified the faulty function in 87.6% of cases, a substantial improvement over baseline static analysis (≈45%) and over a generic LLM‑based debugger (≈62%).
- Speed. The average end‑to‑end diagnosis time dropped from roughly 5,800 seconds (≈1.6 hours) of human effort to 77 seconds of automated processing—a 98% reduction.
- Scalability. The system handled the full 70‑million‑line codebase without degradation, thanks to its hierarchical search strategy.
Beyond raw numbers, the authors highlighted qualitative benefits: engineers reported higher confidence in the generated explanations, and the reduced turnaround time allowed critical patches to be shipped before the crash frequency escalated.
Why This Matters for AI Systems and Agents
Holmes demonstrates a concrete pathway for turning large language models into agentic problem solvers that operate under severe information constraints. For AI practitioners, the key takeaways are:
- Multimodal Fusion. Combining textual logs with low‑level binary artifacts yields richer context than any single modality.
- Hierarchical Orchestration. Splitting the task into retrieval, exploration, and reasoning stages mirrors human debugging workflows and makes the overall system more interpretable.
- Dynamic Search Compression. By letting early agents prune the search space, later agents can focus computational resources on the most promising candidates, a pattern that can be reused in other large‑scale analysis problems (e.g., security triage, performance bottleneck detection).
- Enterprise Integration. The output format of Holmes aligns with incident‑management platforms, enabling seamless automation of ticket creation and escalation.
Organizations that already leverage AI‑driven automation—such as those using the Enterprise AI platform by UBOS—can embed Holmes‑style agents to close the loop between crash detection and root‑cause remediation, turning a traditionally reactive process into a proactive, data‑driven workflow.
What Comes Next
While Holmes marks a significant advance, several open challenges remain:
- Generalization to Other Platforms. Extending the framework to iOS, desktop, or server‑side services will require new adapters for platform‑specific artifacts.
- Continuous Learning. Incorporating feedback from engineers (e.g., confirming or rejecting suggested fault locations) could fine‑tune the agents in an online fashion.
- Privacy‑Preserving Diagnostics. Many crash logs contain user‑identifiable data; integrating differential privacy mechanisms would broaden adoption in regulated industries.
- Tooling Ecosystem. Building visual debugging extensions, IDE plugins, and API endpoints would lower the barrier for developers to adopt Holmes‑style agents.
Future research may also explore tighter coupling between the Reasoner Agent and formal verification tools, enabling not just fault localization but automated patch synthesis. For teams looking to prototype such pipelines, the Workflow automation studio offers a low‑code environment to chain LLM agents, data stores, and custom scripts.
References
Li, J., Ma, W., Peng, T., Zheng, H., & Deng, Y. (2026). Holmes: Multimodal Agentic Diagnosis for Mixed-Language Mobile Crashes at Industrial Scale. arXiv preprint arXiv:2606.21963.