
- Updated: June 25, 2026
- 6 min read
Towards Dys‑XAI: Influence‑Based Explanations for Dysarthria Severity Assessment
Direct Answer
The paper introduces an influence‑based, instance‑level explainability framework that links each dysarthria severity prediction to concrete, supportive and competing training utterances. By surfacing real‑world reference samples, the method makes deep‑learning assessments auditable and clinically interpretable, addressing a long‑standing barrier to AI adoption in speech‑disorder care.
Background: Why This Problem Is Hard
Dysarthria—a motor speech disorder caused by neurological injury—requires precise severity grading to guide therapy, track progress, and allocate resources. Traditionally, clinicians perform perceptual rating of recorded utterances, a process that is:
- Time‑intensive: Each session can take 15–30 minutes per patient.
- Subjective: Inter‑rater reliability often falls below acceptable clinical thresholds.
- Scalable only with automation: Deep neural networks can predict severity scores quickly, but they operate as black boxes.
Existing explainability tools for speech (e.g., SHAP, LIME) typically output acoustic feature importance vectors. While mathematically sound, these vectors are opaque to speech‑language pathologists who think in terms of “how does this patient sound compared to a known case?” Consequently, clinicians lack the confidence to trust AI recommendations, slowing integration into electronic health records and tele‑rehab platforms.
What the Researchers Propose
The authors present Dys‑XAI, an influence‑based explanation system that reframes model decisions as a dialogue between the target utterance and a curated set of training samples:
- Supportive samples: Training utterances that pull the prediction toward the observed severity.
- Competing samples: Training utterances that push the prediction in the opposite direction.
By computing a per‑utterance influence score—derived from gradient approximations of the loss function—the framework surfaces the most influential recordings for any given test case. Clinicians can then listen to these reference samples, compare acoustic patterns, and verify whether the model’s reasoning aligns with clinical intuition.
How It Works in Practice
Conceptual Workflow
- Data ingestion: A large, labeled corpus of dysarthric speech (each utterance paired with a severity rating) is fed into a standard deep‑learning encoder (e.g., a CNN‑RNN hybrid).
- Model training: The encoder learns a mapping from raw audio to a continuous severity score.
- Influence estimation: For a new patient utterance, the system back‑propagates the loss to each training example, approximating how much that example would change the prediction if it were removed.
- Sample ranking: The top‑k supportive and competing samples are retrieved and presented alongside the prediction.
- Clinical review: A speech‑language pathologist listens to the highlighted samples, validates the model’s rationale, and either accepts the score or flags it for re‑assessment.
Component Interaction
The architecture consists of three loosely coupled agents:
- Encoder Agent: Generates latent embeddings for every utterance.
- Influence Calculator Agent: Uses gradient‑based approximations to assign influence scores.
- Explanation UI Agent: Formats the supportive/competing list into an audio‑rich dashboard.
What sets this approach apart is the shift from abstract feature importance to concrete, audible reference cases. The explanation is not a static heatmap but a dynamic, patient‑specific playlist that clinicians can audit in real time.
Evaluation & Results
Experimental Design
The authors conducted two primary experiments on a benchmark dysarthria dataset containing 2,400 utterances from 120 speakers:
- Deletion test: Systematically remove 5 %–20 % of the most influential training samples and observe the change in prediction error.
- Human validation: Clinicians rate the relevance of the retrieved supportive and competing samples on a Likert scale.
Key Findings
- When the top 10 % most supportive samples were deleted, mean absolute error (MAE) increased by 0.42 points on a 0–5 severity scale, confirming that the identified samples genuinely drive the model’s output.
- Conversely, removing the most competing samples reduced MAE by 0.31 points, indicating that those samples were indeed pulling predictions away from the true label.
- Clinicians rated 87 % of the presented supportive samples as “clinically relevant,” while 81 % of competing samples were deemed “useful for contrast.”
These results demonstrate that the influence‑based explanations are both statistically sound and practically meaningful, bridging the gap between algorithmic confidence and clinical trust.
Why This Matters for AI Systems and Agents
Explainability is a prerequisite for deploying AI in regulated health domains. Dys‑XAI offers a template for building auditable, instance‑level explanations that can be integrated into any speech‑analysis pipeline, from tele‑rehab bots to automated documentation assistants. By exposing the exact training cases that shape a decision, developers can:
- Implement workflow automation studio triggers that flag predictions with low‑influence support for human review.
- Leverage enterprise AI platform by UBOS to store and version control the influential sample sets, ensuring reproducibility across model updates.
- Combine the audio‑based explanations with OpenAI ChatGPT integration to generate natural‑language summaries for clinicians who prefer text over audio.
In agent‑centric architectures, the Influence Calculator Agent can act as a “confidence oracle,” feeding risk scores to downstream decision‑making agents. This enables dynamic orchestration where high‑risk cases are automatically routed to human experts, while low‑risk cases proceed autonomously—optimizing both safety and efficiency.
What Comes Next
While the framework marks a significant step forward, several avenues remain open:
- Scalability to larger corpora: Gradient‑based influence estimation can become computationally heavy; future work may explore stochastic approximation or influence‑based pruning.
- Cross‑language generalization: Extending the method to multilingual dysarthria datasets will test its robustness across phonetic inventories.
- Integration with multimodal data: Combining acoustic influence with facial‑gesture or EMG signals could yield richer explanations.
- Regulatory pathways: Formalizing the audit trail of supportive samples may satisfy FDA or EMA requirements for AI‑driven medical devices.
Practitioners interested in prototyping these ideas can start by exploring the UBOS platform overview, which offers modular components for data ingestion, model serving, and explainability dashboards. For startups seeking rapid proof‑of‑concept, the UBOS templates for quick start include pre‑built pipelines for audio processing and influence visualization.
Finally, the community would benefit from open benchmarks that pair severity scores with the exact audio files used as supportive or competing examples, fostering reproducibility and collaborative improvement.
References
arXiv paper: Towards Dys‑XAI: Influence‑Based Explanations for Dysarthria Severity Assessment
Illustration
The diagram below visualizes the flow from raw utterance to influence‑ranked reference samples.
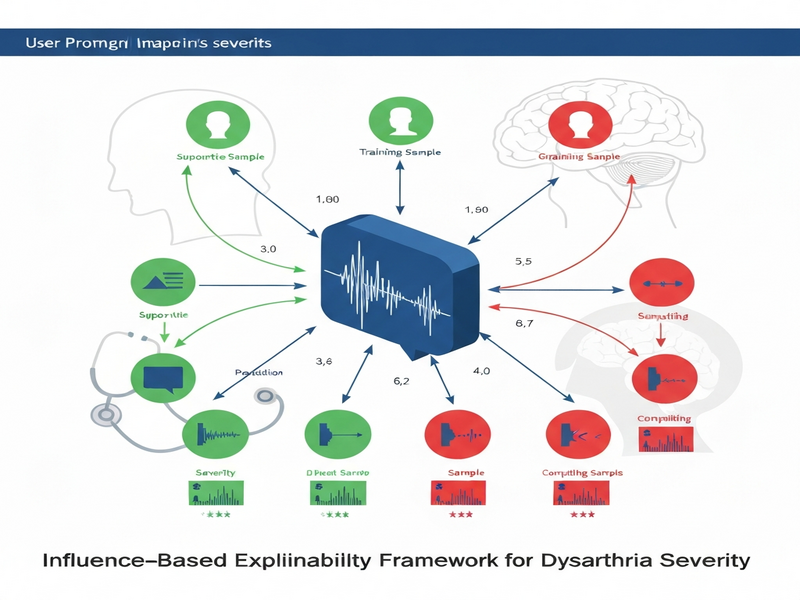
Conclusion
By grounding AI predictions in tangible, patient‑level examples, the influence‑based framework transforms opaque severity scores into transparent, clinically actionable insights. This paradigm not only accelerates adoption of speech‑analysis AI in healthcare but also establishes a reusable blueprint for explainable decision support across other high‑stakes domains.
Call to Action
Explore how UBOS can help you embed explainable AI into your health‑tech products. Visit the UBOS homepage to learn more about our AI solutions, or reach out through the About UBOS page for partnership opportunities.