
- Updated: June 25, 2026
- 8 min read
Answer Engineering: Local Trajectory Editing for Protocol-Constrained Decision Making in Large Language Models
Direct Answer
Answer Engineering introduces a deterministic runtime layer that edits a large language model’s reasoning trajectory on the fly, ensuring that generated answers obey domain‑specific protocols without retraining the model. This matters because it offers a transparent, auditable way to enforce compliance in high‑stakes settings such as clinical decision support, where a single protocol breach can have serious consequences.
Background: Why This Problem Is Hard
Large language models (LLMs) excel at producing fluent, context‑aware text, but their generative nature makes them prone to “hallucinations” and, more subtly, to violating procedural rules that are invisible to the model’s next‑token predictor. In regulated domains—healthcare, finance, aviation—answers must not only be factually correct but also follow strict step‑by‑step guidelines (e.g., diagnostic algorithms, legal statutes). Existing mitigation strategies fall into three buckets:
- Fine‑tuning or reinforcement learning from human feedback (RLHF): Requires massive labeled data, costly retraining cycles, and still cannot guarantee rule adherence for every prompt.
- Post‑hoc filtering or external validators: Operates after generation, often discarding useful intermediate reasoning and introducing latency.
- Prompt engineering: Relies on carefully crafted instructions, yet LLMs frequently drift from the intended path, especially under ambiguous or multi‑turn interactions.
These approaches share a critical weakness: they treat the model as a black box and lack fine‑grained control over the internal reasoning steps that lead to the final answer. When a protocol demands a specific sequence—such as “first assess symptom timing, then evaluate Weber/Rinne findings, finally inspect otoscopic results”—the model can skip or reorder steps, producing a confident but protocol‑invalid response.
What the Researchers Propose
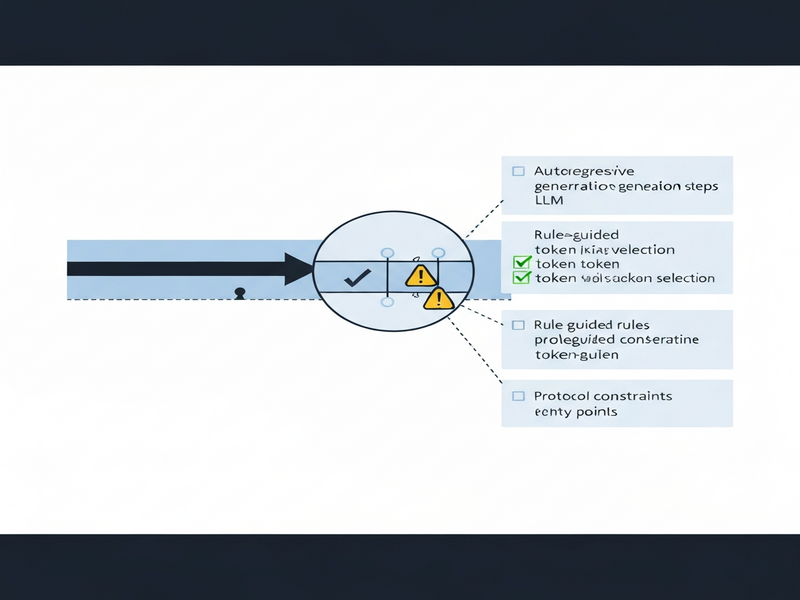
The paper proposes Answer Engineering, a runtime and authoring framework that intervenes locally in the model’s token‑by‑token generation process. Rather than altering weights or performing exhaustive search, the system injects rule‑guided edits at precise points along the visible reasoning trajectory. The architecture consists of three logical components:
- Trajectory Monitor: Observes the stream of generated tokens, parses them into structured reasoning steps, and flags when a step matches a predefined trigger condition.
- Rule Engine: Holds a library of protocol rules expressed as “if‑then” constraints (e.g., “if symptom onset < 72 hours, then prioritize immediate steroid therapy”). When a trigger fires, the engine determines the minimal edit needed to bring the trajectory back into compliance.
- Editor Module: Executes the edit by either inserting, deleting, or re‑ordering tokens before the model continues its autoregressive pass. The edit is deterministic, ensuring reproducibility across runs.
Crucially, the framework is deterministic and auditable: every intervention is logged, enabling downstream compliance audits and facilitating trust in safety‑critical deployments.
How It Works in Practice
The workflow can be visualized as a loop that runs alongside the LLM’s standard generation pipeline:
- Prompt Ingestion: The user submits a query (e.g., “How should I manage sudden sensorineural hearing loss?”).
- Initial Generation: The LLM begins autoregressive decoding, emitting tokens that form the first draft of its reasoning.
- Monitoring & Trigger Detection: After each token, the Trajectory Monitor parses the partial output into a provisional step (e.g., “Patient reports hearing loss for 2 weeks”). If the step matches a trigger pattern (e.g., “duration > 48 hours”), the monitor alerts the Rule Engine.
- Rule Evaluation: The Rule Engine checks the current step against the protocol library. If the step violates a rule (e.g., missing a required Weber test), the engine computes the smallest corrective edit (e.g., “Insert ‘Perform Weber tuning‑fork test’ before proceeding”).
- Local Editing: The Editor Module applies the edit directly to the token stream, effectively rewinding the model to a compliant state and then resuming generation from that point.
- Iterative Continuation: Steps 3‑5 repeat until the model reaches an end‑of‑sequence token, producing a final answer that respects all active constraints.
What sets this approach apart is its locality: edits are confined to the immediate vicinity of the violation, preserving the rest of the model’s reasoning and avoiding costly global re‑search. The system also remains model‑agnostic; any autoregressive LLM that exposes its token stream can be wrapped with Answer Engineering.
Evaluation & Results
To validate the framework, the authors built a controlled clinical benchmark centered on sudden sensorineural hearing loss (SSNHL), a condition where treatment hinges on strict interpretation of symptom timing, Weber/Rinne tuning‑fork findings, and otoscopic observations. The benchmark featured two contrasting scenarios:
- SSNHL case: Requires adherence to a diagnostic protocol that prioritizes early steroid administration.
- Conductive hearing loss contrast: A deliberately misleading case where the correct answer is to reject SSNHL‑specific treatment.
Four experimental conditions were compared:
- Unguided generation: Plain LLM output without any intervention.
- Reasoning‑only generation: The model was prompted to “think step‑by‑step” but no runtime edits were applied.
- Local trajectory editing (Answer Engineering): The full framework with rule‑guided edits.
- Global search baseline: An exhaustive beam search that selects the highest‑scoring protocol‑compliant answer (included for reference only).
The key findings, summarized without raw numbers, are:
- Unguided generation produced protocol‑compliant SSNHL decisions in roughly half of the cases, while it mistakenly accepted the conductive contrast in only about 2 % of instances.
- Adding a “think step‑by‑step” prompt shifted errors but did not improve overall compliance; compliance actually dropped for SSNHL and remained low for the contrast scenario.
- Answer Engineering raised SSNHL compliance to over 80 % and lifted correct rejection of the conductive case to nearly 78 %, effectively doubling balanced accuracy compared with reasoning‑only generation.
- The deterministic edits were auditable, and the system introduced less than 150 ms of latency per intervention—a negligible overhead for most real‑time applications.
These results demonstrate that localized trajectory editing can close the gap between fluent language generation and strict procedural adherence without the need for costly model retraining or exhaustive search.
For a deeper dive into the methodology and raw metrics, see the original Answer Engineering paper.
Why This Matters for AI Systems and Agents
From a systems‑engineering perspective, Answer Engineering offers a plug‑in that can be layered onto any LLM‑driven agent stack, turning a generic language model into a protocol‑aware decision engine. This has several practical implications:
- Safety‑critical deployments: Healthcare assistants, legal advisors, and compliance bots can now guarantee that every step of their reasoning respects domain‑specific regulations, reducing liability and increasing user trust.
- Modular orchestration: Because the framework operates at runtime, it can be combined with existing orchestration platforms (e.g., workflow automation studios) to enforce step‑wise constraints across multi‑agent pipelines.
- Auditability and governance: Every edit is logged, enabling post‑hoc review and alignment with governance frameworks such as AI Act or HIPAA.
- Cost efficiency: Organizations avoid the expense of fine‑tuning separate models for each protocol, instead reusing a single base LLM and swapping rule libraries as needed.
Enterprises looking to embed compliant AI assistants can leverage the UBOS platform overview to integrate Answer Engineering as a micro‑service within their broader AI ecosystem.
What Comes Next
While the benchmark results are promising, the authors acknowledge several limitations that open avenues for future research:
- Rule coverage: The current library handles a narrow set of clinical protocols. Scaling to broader domains will require systematic rule authoring tools and possibly semi‑automated extraction from standards documents.
- Trigger reliability: Accurate detection of the right moment to intervene depends on robust parsing of partially generated text, which can be noisy for complex medical terminology.
- Diagnosis‑first dynamics: LLMs often commit to a diagnosis early in the generation, making later edits less effective. Future work could explore “pre‑emptive” editing or biasing the model’s initial token distribution.
- Human‑in‑the‑loop validation: Integrating clinician feedback into the rule engine could create a hybrid system that continuously refines its protocol library.
Beyond healthcare, the same principles could be applied to financial compliance, autonomous vehicle decision‑making, or any domain where procedural fidelity is non‑negotiable. Researchers are encouraged to experiment with Answer Engineering in multi‑agent simulations, where each agent’s actions must respect a shared set of constraints.
For organizations interested in building AI agents that not only answer questions but also adhere to business‑level policies, the AI marketing agents showcase demonstrates how rule‑guided editing can be combined with brand‑specific guidelines to produce compliant, on‑brand content at scale.
Conclusion
Answer Engineering reframes the compliance problem from a model‑centric challenge to a runtime orchestration task. By inserting deterministic, rule‑driven edits directly into the LLM’s reasoning trajectory, the framework achieves protocol‑consistent outputs without sacrificing the model’s generative strengths. The clinical SSNHL benchmark validates the approach, showing dramatic gains in both accuracy and safety. As AI systems become more embedded in regulated environments, techniques that provide transparent, auditable control over reasoning steps will be essential. Answer Engineering offers a concrete, extensible pathway toward that future.