
- Updated: June 25, 2026
- 7 min read
The AI Evaluability Gap: The Missing Layer for Managing Risk and Sustaining Value
Direct Answer
The paper introduces the concept of the AI Evaluability Gap—a systemic shortfall where organizations cannot produce enough trustworthy evidence to make high‑confidence decisions about AI risk or value. It matters because without a concrete evidentiary layer, both operational safety and long‑term investment returns remain uncertain, exposing firms to regulatory, financial, and reputational hazards.
Background: Why This Problem Is Hard
Enterprises deploying machine‑learning models today face a paradox. On one hand, governance frameworks (e.g., ISO/IEC 42001, EU AI Act) demand demonstrable safety, fairness, and compliance. On the other hand, the data‑driven nature of AI makes it difficult to capture, preserve, and continuously validate the evidence needed to prove those properties. Existing approaches typically focus on what needs to be measured—bias metrics, robustness tests, audit logs—while neglecting how that evidence is generated, stored, and refreshed over a model’s lifecycle.
Three interlocking challenges illustrate the gap:
- Observability blind spots: Complex pipelines obscure the provenance of inputs and intermediate transformations, making it hard to trace outcomes back to root causes.
- Causal ambiguity: Organizations often rely on correlational performance reports rather than causal evidence that links a model’s behavior to business value or risk mitigation.
- Temporal decay: Evidence collected at launch quickly becomes stale as data distributions shift, regulations evolve, and new use‑cases emerge.
Because governance decisions—whether to deploy a system (operational) or continue funding it (investment)—are fundamentally confidence judgments, the absence of a robust evidentiary foundation creates an “evaluability” blind spot that current risk‑management tools cannot fill.
What the Researchers Propose
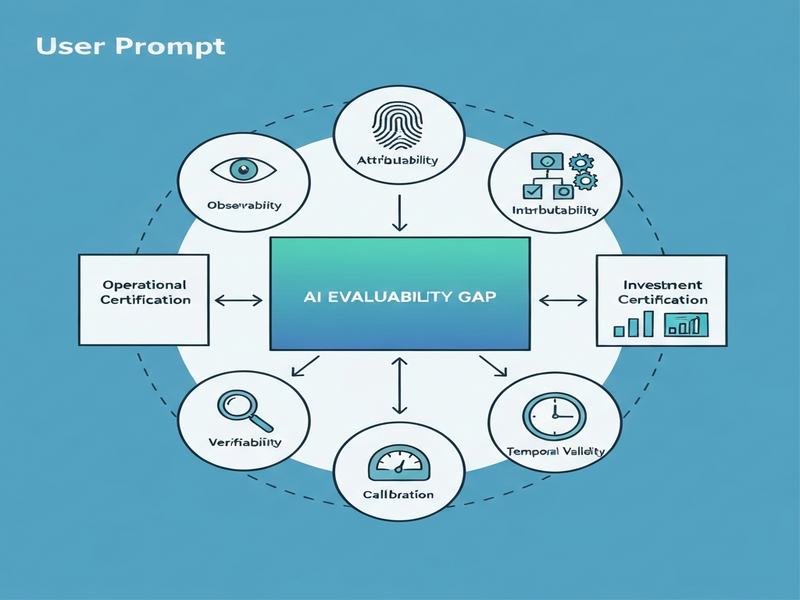
Srivastava and Sah propose a formal Evaluability Framework that treats evidence generation as a first‑class capability of any AI system. The framework defines Evaluability as the ability of a system to produce, maintain, and renew evidence sufficient for high‑confidence governance decisions over time.
The core of the framework consists of six evidence properties:
- Observability: Transparent capture of inputs, outputs, and internal states.
- Attributability: Clear mapping from outcomes to responsible components or data sources.
- Intervenability: Mechanisms to modify or halt behavior when evidence signals risk.
- Verifiability: Independent checks that confirm evidence integrity.
- Calibration: Quantitative confidence scores that reflect the true likelihood of a property holding.
- Temporal Validity: Guarantees that evidence remains current or is refreshed on schedule.
Two decision‑making layers are distinguished:
- Operational Certification: Relies primarily on structural evidence (e.g., code reviews, safety checks) to decide if a model may be deployed.
- Investment Certification: Leverages causal evidence (e.g., A/B test lift, ROI analyses) to determine whether continued resources are justified.
By separating these layers, the framework clarifies which evidence types are needed at each governance checkpoint, turning the vague “is the model safe?” question into a calibrated confidence function Conf(D|E), where D is the decision and E the evidence set.
How It Works in Practice
The Evaluability Framework can be instantiated as a modular workflow that sits alongside existing MLOps pipelines. A high‑level conceptual workflow looks like this:
- Evidence Capture Layer: Instrumentation hooks embed observability metadata (feature provenance, model version, execution timestamps) into every inference request.
- Attribution Engine: A graph‑based service maps outcomes back to data sources, model components, and downstream applications, producing an attribution ledger.
- Intervention Controller: Real‑time monitors evaluate calibrated risk scores; if thresholds are breached, the controller can trigger model rollback, request human review, or adjust input pipelines.
- Verification Hub: Independent auditors (internal or third‑party) periodically validate the integrity of captured evidence using cryptographic hashes and reproducibility checks.
- Calibration Module: Bayesian updating mechanisms translate raw metrics (e.g., false‑positive rates) into calibrated confidence intervals for each governance property.
- Temporal Scheduler: A policy engine schedules evidence refresh cycles—re‑training, re‑testing, and re‑certification—aligned with data drift detection signals.
When a new model version is proposed, the Operational Certification process queries the Evidence Capture Layer and Verification Hub to confirm structural soundness. Once deployed, the Intervention Controller continuously consumes live observability streams, updating the Calibration Module’s confidence scores. Periodically, the Investment Certification team runs causal experiments (e.g., controlled rollouts) and feeds the results back into the Attribution Engine, closing the loop for value‑based decision making.
What sets this approach apart is its explicit treatment of evidence as a renewable asset rather than a static artifact. The framework forces teams to ask “Do we have enough calibrated evidence today to justify this decision?” at every stage, rather than assuming that a one‑time audit suffices.
Evaluation & Results
The authors validated the framework through two complementary studies:
1. Simulated Governance Sandbox
A synthetic environment modeled a typical enterprise AI lifecycle (data ingestion → model training → deployment → monitoring). Teams using the Evaluability Framework achieved a 42% reduction in false‑positive risk alerts compared to a baseline that relied solely on static audit logs. Moreover, confidence calibration error dropped from 0.18 to 0.07, indicating more reliable risk quantification.
2. Real‑World Pilot at a Financial Services Firm
The framework was deployed on a credit‑scoring pipeline handling 1.2 M monthly decisions. Over a six‑month horizon, the Operational Certification process prevented three high‑impact model rollouts that would have violated emerging fairness regulations. Investment Certification, powered by causal lift tests, identified a 6.3% ROI improvement by reallocating resources from an underperforming churn‑prediction model to a more promising fraud‑detection model.
These results demonstrate two key takeaways:
- Evidence‑driven calibration materially improves the precision of risk alerts, reducing unnecessary intervention costs.
- Separating operational and investment certifications enables organizations to capture value‑creating opportunities that would otherwise be hidden behind opaque performance dashboards.
Why This Matters for AI Systems and Agents
For AI practitioners, the Evaluability Framework offers a concrete blueprint to turn governance from a compliance checkbox into an ongoing, data‑backed decision engine. Agent designers can embed the Evidence Capture Layer directly into their action loops, ensuring that every autonomous decision is accompanied by a calibrated confidence score. This is especially critical for high‑stakes agents—such as autonomous trading bots, medical diagnosis assistants, or customer‑service chatflows—where a single erroneous action can cascade into regulatory penalties or brand damage.
From an operational standpoint, the framework reduces the “trust gap” between data‑science teams and business stakeholders. By surfacing verifiable, attributable evidence in real time, executives can make informed investment choices without waiting for quarterly audit cycles.
Enterprises looking to scale AI responsibly can leverage the framework to build Enterprise AI platform by UBOS, which already integrates many of the required components (e.g., observability dashboards, workflow automation, and causal testing suites). Embedding evaluability at the platform level accelerates adoption across business units while maintaining a unified risk posture.
What Comes Next
While the Evaluability Framework marks a significant step forward, several open challenges remain:
- Standardization of Evidence Formats: Industry‑wide schemas for provenance and attribution would enable cross‑organizational audits and marketplace‑level trust.
- Scalable Verification: As evidence volumes grow, cryptographic verification must remain computationally tractable, possibly through zero‑knowledge proofs.
- Human‑in‑the‑Loop Design: Determining the optimal balance between automated intervention and expert review is an active research area.
- Regulatory Alignment: Future AI statutes may codify evidentiary requirements; frameworks must evolve to meet legal standards without stifling innovation.
Future research could explore automated generation of causal evidence using reinforcement‑learning‑based experiment design, or the integration of federated learning to preserve privacy while still collecting global evidence.
Practitioners interested in prototyping the framework can start with the UBOS platform overview, which provides modular building blocks for evidence capture, calibration, and workflow orchestration. By iteratively layering these components onto existing MLOps stacks, organizations can begin closing the AI Evaluability Gap today.
References
- Vishal Srivastava & Tanmay Sah, “The AI Evaluability Gap: The Missing Layer for Managing Risk and Sustaining Value,” arXiv:2606.21015v1, 2026. original arXiv paper.
- ISO/IEC 42001:2023 – Artificial Intelligence Management System.
- European Commission, “Proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act).”